机器学习 -- 经典论文 ViT (Vision Transformer)
经典论文 ViT。非常喜欢这篇论文,第一次直观一窥 Attention 内部,模型真的学到了图片知识。 感觉关键的是不要对原始数据做过多的处理,让 AI 自己去学习规律。 想法不值钱,没钱的 lab 也没法搞,所以最近几年好的模型都是谷歌微软推进的。 美国 AI 从业者 / 研究者 60% 以上为华人 / 华裔,已经是统治级别的地位了。 有好的丹炉和原料也还要有过硬的炼丹技术。
- Transformer 相较于 CNN 结构,缺少一定的平移等变性(translation equivariance)和局部感知性,因此在数据量不充分时,很难达到同等的效果。具体表现为使用中等规模的 ImageNet 训练的 Transformer 会比 ResNet 在精度上低几个百分点。
- 数据规模至少 ImageNet-21k 才建议选择 ViT。
- 当有大量的训练样本时,结果则会发生改变。使用大规模数据集进行预训练后,再使用迁移学习的方式应用到其他数据集上,可以达到或超越当前的 SOTA 水平。
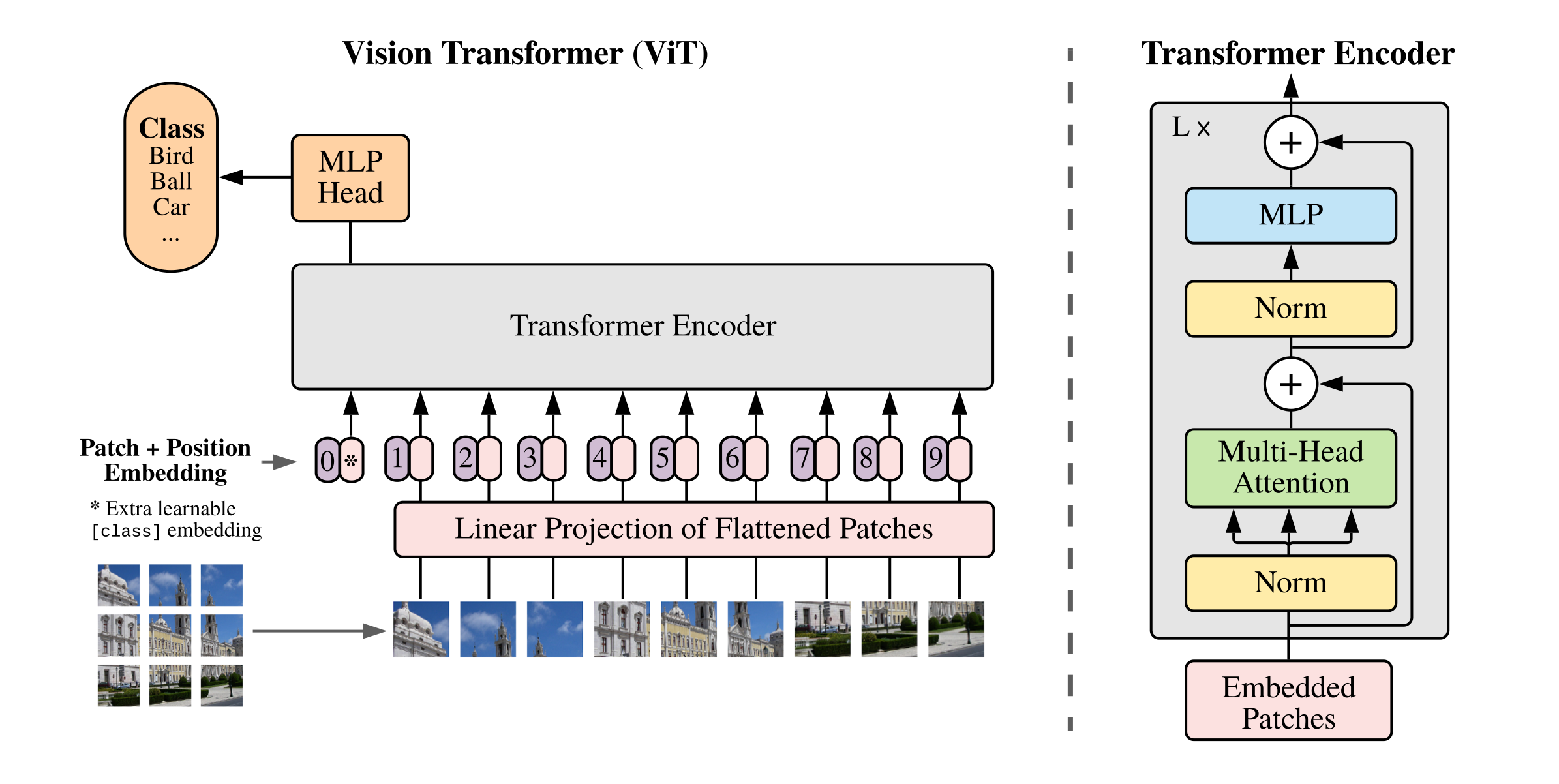
但是当训练数据集不够大的时候,ViT 的表现通常比同等大小的 ResNets 要差一些,因为 Transformer 和 CNN 相比缺少归纳偏置(inductive bias),即一种先验知识,提前做好的假设。CNN 具有两种归纳偏置,一种是局部性(locality / two-dimensional neighborhood structure),即图片上相邻的区域具有相似的特征;一种是平移等变性(translation equivariance), $f(g(x))=g(f(x))$ ,其中 $g$ 代表卷积操作,$f$ 代表平移操作。当 CNN 具有以上两种归纳偏置,就有了很多先验信息,需要相对少的数据就可以学习一个比较好的模型。
Tips
- 很多人搞的方案主要是贫穷,比如孤立自注意力、轴注意力等等。
- 这对于人均两张卡的小实验室来说,用 ViT 训练一个 ImageNet 真太贵了,哎,总之现在要发顶会,没有硬件真的是很难的事情。
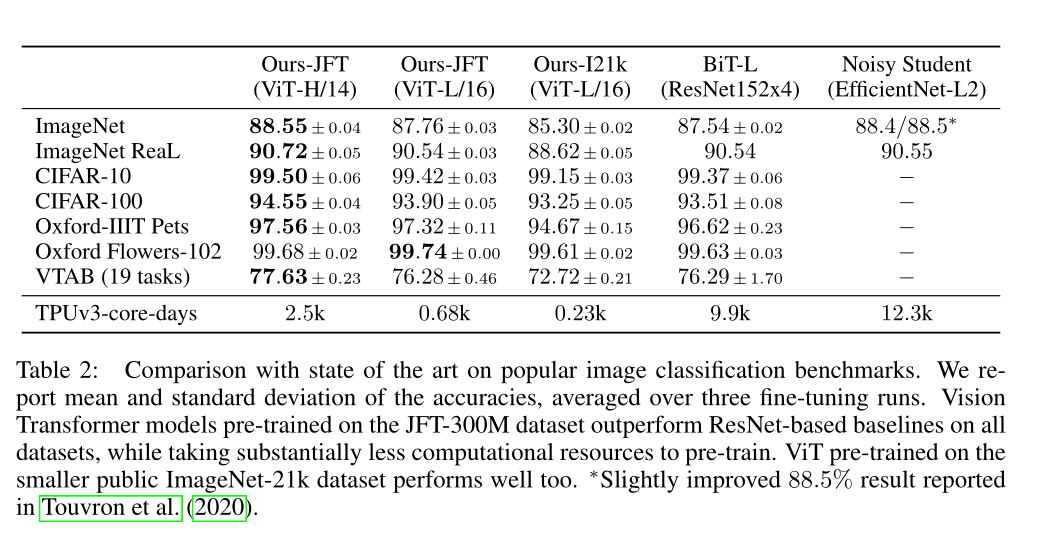
- Google JFT-300M 数据集( 3 个亿 ),下图中的 12.3k 是 一万多天 ,半辈子都过去了。
Positional Encoding
按照 Transformer 结构中的位置编码习惯,这个工作也使用了位置编码。不同的是,ViT 中的位置编码没有采用原版 Transformer 中的 sincos 编码,而是直接设置为可学习的 Positional Encoding。对训练好的 Positional Encoding 进行可视化。我们可以看到,位置越接近,往往具有更相似的位置编码。此外,出现了行列结构,同一行 / 列中的 patch 具有相似的位置编码。
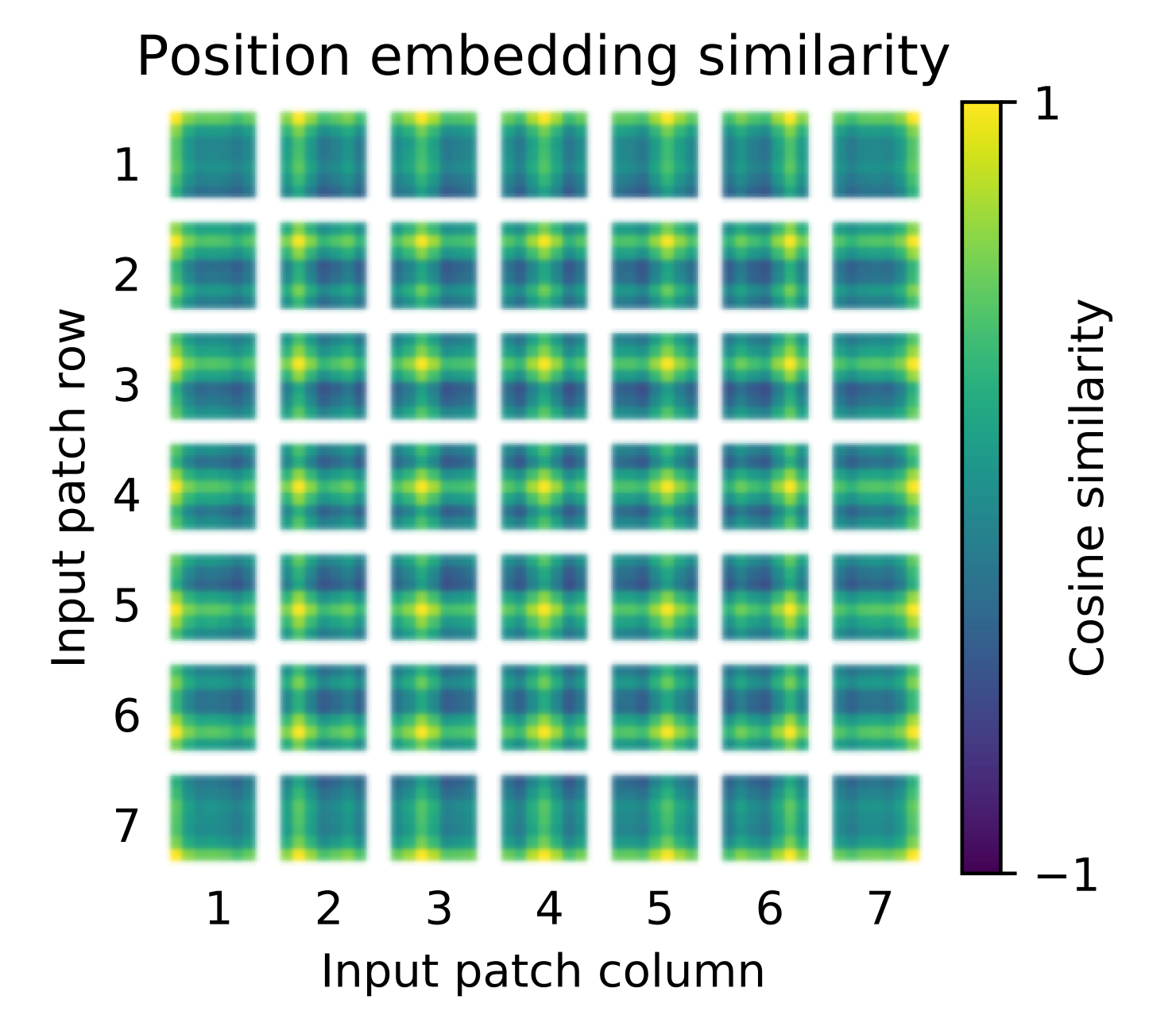
位置编码得相似性分析 (cos),位置越接接近,patches 之间的相似度越高;相同行 / 列的 patches 有相似的 embeddings;
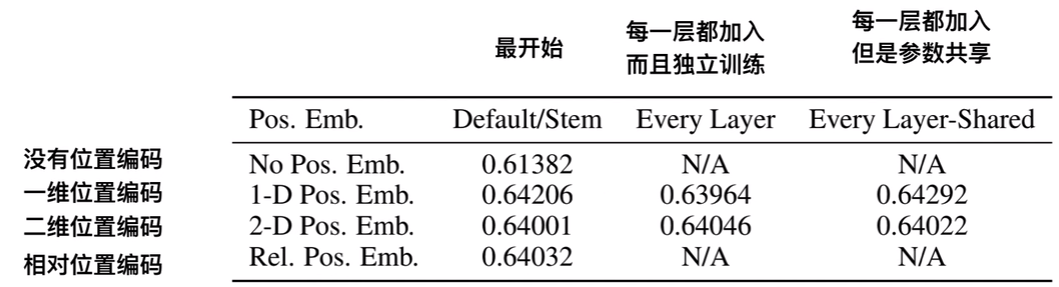
- 1-D 位置编码:例如 3x3 共 9 个 patch,patch 编码为 1 到 9。
- 2-D 位置编码:patch 编码为 11,12,13,21,22,23,31,32,33,即同时考虑 X 和 Y 轴的信息,每个轴的编码维度是 D/2。
- 相对位置编码。
实际实验结果表明,不管使用哪种位置编码方式,模型的精度都很接近,甚至不使用位置编码,模型的性能损失也没有特别大。原因可能是 ViT 是作用在 image patch 上的,而不是 image pixel,对网络来说这些 patch 之间的相对位置信息很容易理解,所以使用什么方式的位置编码影响都不大。
模型可视化
ViT block 第一层(linear projection)的前 28 个主成分:

很像 Gabor 滤波器。 Gabor 和小波变换突破了傅里叶变换的局限性。
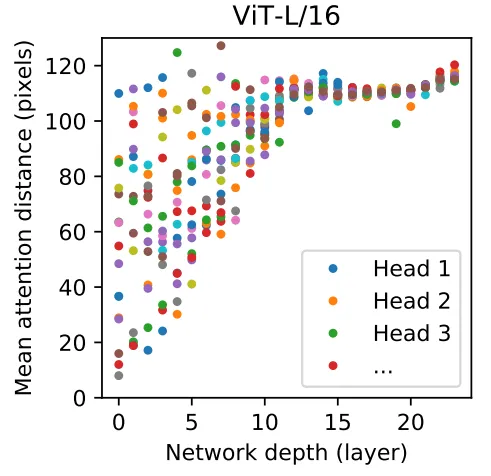
为了理解 self-attention 是如何聚合信息的(To understand how ViT uses self-attention to integrate information across the image),基于 attention weight 计算不同 layer 不同 head 的 average attention distance。 每一个 layer 的每一个 head 的 average attention distance,类似于 CNN 感受野的概念,可以发现一些 head 在第一个 layer 就 attent 到了几乎整张图片的范围。
Representative examples of attention from the output token to the input space.

Refs
参考资料快照
- 机器学习 -- 大型语言模型简史:从 Transformers (2017) 到 DeepSeek-R1 (2025) | 20 Feb 2025
- 机器学习 -- DALL·E 2 & 扩散模型 | 21 Dec 2024
- 机器学习 -- 学术论文解读系列(进行中) | 04 Oct 2024
- 机器学习 -- 经典论文 ViT (Vision Transformer) | 24 Jul 2024
- 机器学习 -- 跟李沐学 AI【论文精读】(进行中) | 09 Jul 2024
- 机器学习 -- Attention is all you need | 30 Jun 2024
- 机器学习笔记 -- 3Blue1Brown 深度学习 Deep Learning(已完成) | 29 Jun 2024
- 机器学习 -- 李宏毅 2021/2022 春机器学习课程(进行中) | 31 Aug 2023
- 机器学习 -- 实用机器学习 李沐(进行中) | 31 Aug 2023
- 机器学习 -- ChatGPT Prompt 提示词 吴恩达(进行中) | 28 Jul 2023
- 机器学习 -- 浙江大学 · 机器学习(已完成) | 12 Feb 2023
- 机器学习 -- 人工智能学习路线(进行中……) | 10 Feb 2023
- 机器学习 -- 北交 · 图像处理与机器学习(已完成) | 03 Dec 2022
- 机器学习笔记 -- 人工智能 机器学习 算法概览(已完成) | 13 Oct 2022
- 机器学习笔记 -- 神经网络内部发生了什么?深度学习可视化 | 13 Oct 2022
- 机器学习 -- 吴恩达机器学习 Review(已完成) | 31 Aug 2022
- 机器学习 -- 吴恩达深度学习(进行中) | 31 Aug 2022
- 机器学习 -- 吴恩达机器学习(已完成) | 31 Aug 2022
- 机器学习笔记 -- 神经网络和深度学习简史 | 26 Dec 2020
 .
.