机器学习 -- 跟李沐学 AI【论文精读】(进行中)
AI 论文精读 https://www.bilibili.com/video/BV1H44y1t75x/
深度学习经典、新论文逐段精读 https://github.com/mli/paper-reading
如何读论文 06:39
- title
- abs
- intro
- method
- exp
- conclusion
9 年后重读深度学习奠基作之一:AlexNet【上】 18:59
9 年后重读深度学习奠基作之一:AlexNet【下】 55:21
ReLU 函数其实是分段线性函数,把所有的负值都变为 0,而正值不变,这种操作被成为单侧抑制。 可别小看这个简单的操作,正因为有了这单侧抑制,才使得神经网络中的神经元也具有了稀疏激活性。
因为中间断开了链接,所以泛化的结果是两部分解决不同的功能,提取不同类别的特征。 这么训应该不止颜色上面分开,应该有很多方面都是分开的,只是做视觉容易去关注颜色上的特征。
撑起计算机视觉半边天的 ResNet【上】 11:50
ResNet 论文逐段精读 53:46

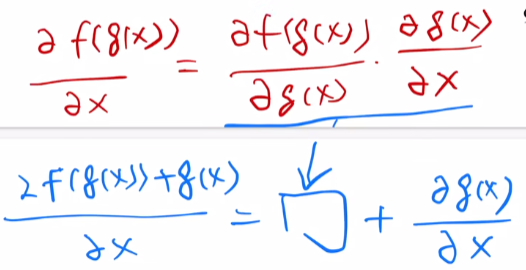
梯度保持的很好,训练更快。
正常情况下,梯度应该在 0 附近的高斯分布。 有点像泰勒展开啊。
Transformer 论文逐段精读
1:27:05
零基础多图详解图神经网络(GNN/GCN)
1:06:19 不知道这玩意有啥用。
需要有一定的机器学习的背景。 图是一个非常强大的东西,但是它的强大也带来了很多问题:很难在图上做出优化,图一般比较稀疏,有效的在 CPU、GPU、加速器上计算是一件比较难的事情;图神经网络对超参数比较敏感。 图神经网络门槛比较高,这些年吸引了很多人对他的研究,但在工业界上的应用还需要时间的积累。 很多图是交互图(既是优点(非常漂亮)又是缺点(门槛太高,有时用一个公式可以清晰的将其表达出来))。
- 什么是图?图的属性应该用向量来进行表示。对于顶点、边、全局都用向量来表示它的属性。
- 现实生活中的现象怎么表示成图,怎么对顶点、边、全局进行预测?
- 机器学习的算法用到图上有什么挑战?
- 定义 GNN:GNN 就是对属性做变换,但不改变图的结构。
- 属性有缺失可以做聚合操作,把边的数据拿到结点上面,补足缺失的数据。
- GNN:每一层里面通过汇聚操作,把信息传递过来,每个顶点看邻接顶点的信息;每个顶点看邻接边的信息或全局的信息。在每一层上如果能对信息进行充分的汇聚,那么 GNN 可以对图的结构进行一个发掘。
- 实验:做了很多实验,可以看到参数对实验结果的影响。
GAN 论文逐段精读
46:18 刺猬摸电线,卷麻了。 这么多年了,GAN、SVM 和 强化学习 的 数学部分,还是没有彻底吃透。
经典论文 GAN。一个分布,通过学习一个模型去近似,收敛多多少少要看运气。判断两个统计是否同一个分布,训练一个二分类分类器即可。

训练一个 GAN 可能很困难,它经常会遇到各种问题,其中最主要的问题有以下三点:
- 消失梯度:这种情况经常发生,特别是当判别器太好时,这会阻碍生辰器的改进。使用最佳的判别器时,由于梯度的消失,训练可能失败,因此无法提供足够的信息给生成器改进。
- 模式塌缩:这是指生成器开始反复产生相同的输出(或一小组输出)的现象。如果判别器陷入局部最小值,那么下一个生成器迭代就很容易找到判别器最合理的输出。判别器永远无法学会走出陷阱。
-
收敛失败:由于许多因素(已知和未知),GANs 经常无法收敛。
- 生成对抗网络 —— 原理解释和数学推导

- 大白话 10 分钟讲明白 GAN 的数学原理



- $V(D^*, G) = -\log(4)$,取其对应极大值。
令 $f(y) = a \log(y) + b \log(1 - y)$
求导 $\frac{\partial}{\partial y} (a \log(y) + b \log(1 - y)) = 0$ \(\frac{a}{y} + \frac{b}{1 - y} (-1) = 0 \\ a - ay = by \\ y = \frac{a}{a + b}\)
所以 $D(x)^* = \frac{p_{data}(x)}{p_{data}(x) + p_g(x)}$
当 $p_{data}(x) = p_g(x)$ 时,$D(x)^* = \frac{1}{2}$
二 . \(V(D, G) = E_{x \sim p_{data}(x)} [\log \frac{1}{2}] + E_{z \sim p_z(z)} [\log \frac{1}{2}] \\ = - \log(2) - \log(2) = - 2 \log(2) \quad \text{ 取其对应极大值。}\)
三 . 定义 KL 散度。任意两个分布 $P$ 和 $Q$ 的差异度量。
\[D_{KL}(P||Q) = E_{x \sim P} [\log (\frac{P(x)}{Q(x)})] \\ = E_{x \sim P} [\log (\frac{P(x)}{Q(x)})] - \log 2\]四 . 代入后,得:
\[V(G, D) = - \log(4) + KL(\frac{p_{data} + p_g}{2} || \frac{p_{data} + p_g}{2}) + KL(\frac{p_g}{2} || \frac{p_{data} + p_g}{2}) \\ \text{ 设 JS 散度 } JSD(P||Q) = \frac{1}{2} D_{KL}(P||\frac{P+Q}{2}) + \frac{1}{2} D_{KL}(Q||\frac{P+Q}{2}) \\ \text{ 可从容地看出散度表示了这两个分布的重合度量。}\] \[V(G, D) = - \log(4) + 2 JSD({p_{data}} || {p_g})\]最终目标,$\min_G V(D, G) = - \log(4)$,当且仅当 $p_{data} = p_g$。
BERT 论文逐段精读
45:49
\(P\left(w_i \mid w_1, \ldots, w_{i-1}, w_{i+1}, \ldots, w_n\right)\) \(P\left(w_i \mid w_1, \ldots w_{i-1}\right) \text { 和 } P\left(w_i \mid w_{i+1}, \ldots w_n\right)\)
ViT 论文逐段精读
1:11:31
感觉关键的是不要对原始数据做过多的处理,让 AI 自己去学习规律。 想法不值钱,没钱的 lab 也没法搞,所以最近几年好的模型都是谷歌微软推进的。
CNN 1. translation equivariance 2. locality.
一篇论文,内容如此饱满,做实验都要做好久好久。
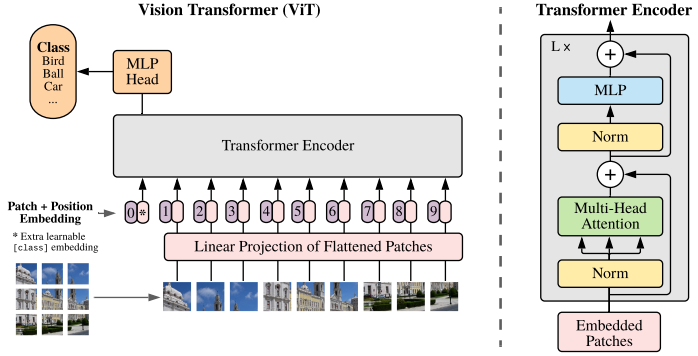
真的是 力大飞砖 。 Vision Transformer 挑战了 CNN 在 CV 中绝对的统治地位。 Vision Transformer 得出的结论是如果在足够多的数据上做预训练, 在不依赖 CNN 的基础上,直接用自然语言上的 Transformer 也能 CV 问题解决得很好。 Transformer 打破了 CV、NLP 之间的壁垒。
MAE 论文逐段精读
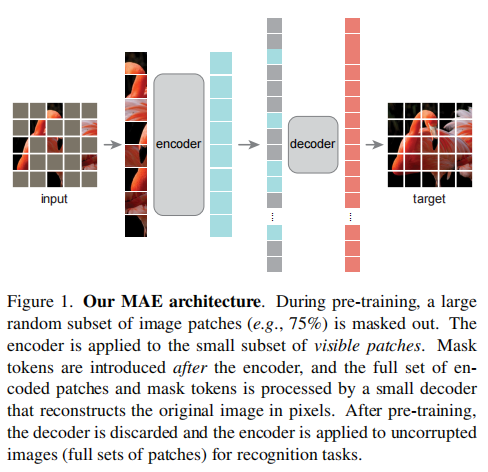
47:04
Mu Li is scalable and efficient tutor
经典论文 2022 MAE。前沿 AI 距离普通人越来越远,以 MAE 这个“便宜”论文为例: 每次训练都需要使用 128 个 TPUv3 的核,训练一天以上,换算大概几千美金; 整个论文大概要做几十上百个实验,整体下来大概几十万美金。 AI 每次改进都有点反直觉,都是靠做实验进步的。
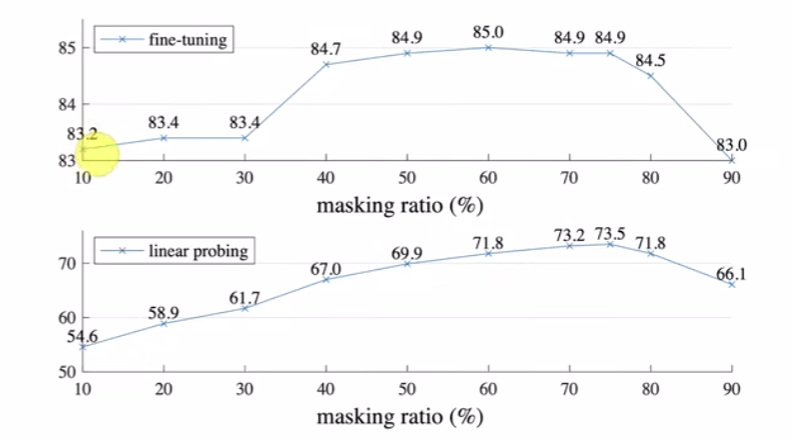
增强不增强我不好说,但是我认为可以抑制过拟合。
- ImageNet,正态分布。
- JFT 数据集,长尾分布。
如何找研究想法 1
05:35 何恺明 涵盖 ResNet、Faster RCNN、Mask RCNN、MoCO 和 MAE。
- Residual Layer 是 LLM 的基本组成部分。
- Faster/Mask R-CNN 是图像分割和机器人感知领域的行业标准。
- Panoptic segmentation 重新定义了视觉研究的一个子领域。
- Mask AutoEncoder (MAE) 是最优秀的通用自监督算法,适用于计算机视觉等多个领域。
- 在 MAE 之前,Momentum Contrast (MoCo) 是最先进的对比学习技术。
- SlowFast 网络是视频学习的默认核心技术之一,直到 ViTs 的出现才慢慢取代了它。
暗通道先验去雾算法
暗通道去雾 https://zhuanlan.zhihu.com/p/418174496
年轻的时候我们有太多的纠结,好像走错了一步棋自己的人生就可能满盘皆输。 但其实我们中的大多数人都只是普通人,花了很多的力气来思考来做抉择,最终还是只能度过平凡的一生。 我们处在某个时间点上,总是想看到未来,却忘了最该做的是走好现在的路。 我在读研期间看书的时候,压根就没想到将来面试的时候考官会问到专业问题,但如果我没有认真学习专业知识,就一定回答不出考官的问题。 也许读完研你会觉得它没有卵用,但是不读研你未必就能成为一个有多少用的人。
MoCo 论文逐段精读
1:24:11
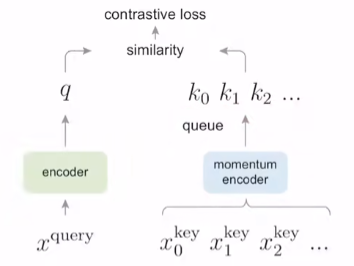
Momentum Contrast From the above perspective, contrastive learning is a wayof building a discrete dictionary on high-dimensional con.tinuous inputs such as images. The dictionary is dynamic inthe sense that the keys are randomly sampled, and that thekey encoder evolves during training. Our hypothesis is thatgood features can be learned by a large dictionary that cov-ers a rich set of negative samples, while the encoder for thedictionary keys is kept as consistent as possible despite itsevolution. Based on this motivation, we present MomentumContrast as described next.
对比学习论文综述
1:32:01
- 百花齐放
- CV 双雄,MoCo vs SimCLR。
- 不用负样本
- Transformer
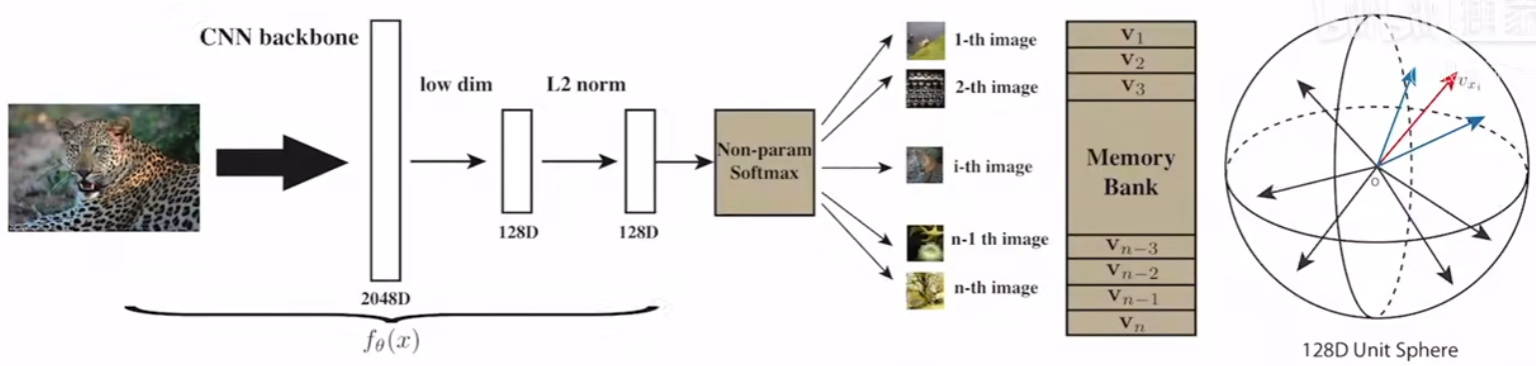
InstDisc
AlphaFold2 论文精读预告
03:28
Deepmind 用机器学习指导数学直觉论文逐段精读
52:51
发表在 Nature 的封面文章 AI 辅助直觉(AI-guided intuition)希望通过机器学习辅助发现纯数学的猜想和定理。
- 对于两个数学对象 X(z), Y(z) ,如果 机器学习 能够学到 f 使得 f(X(z)) 约等于 Y(z) ,说明 X 与 Y 之间有一定关系。
- 其中利用 归因技术(Attribution Techniques) 来辅助发现哪些特征更加重要。(归因技术:计算输入关于输出的梯度,梯度大说明该输入(特征)重要,梯度小说明该输入(特征)不重要)
Swin Transformer 论文精读
Swin transformer 是 2021 年 ICCV 的 best paper。 才过去三年,AI 像过了一个世纪,现在看论文都有点考古的感觉了。 基础性的工作基本都是 Meta、Google、Microsoft、OpenAI 推动的,它们真的改变了世界。
https://zhuanlan.zhihu.com/p/659117181
Swin Transformer 学习笔记 ![]()
1:00:22
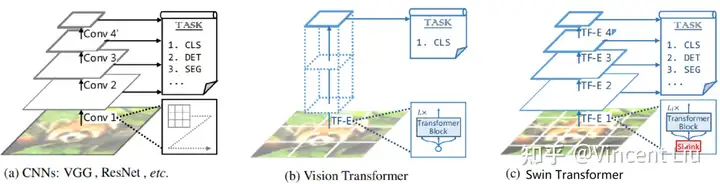
网络结构对比
上图从左到右,我们可以看到:
- CNN:金字塔结构,网络越深,feature map 尺寸越小,channel 数越多。
- ViT:柱状结构,单一的 feature map 尺寸。
- Swin Transformer:金字塔结构,网络越深,feature map 尺寸越小,channel 数越多。
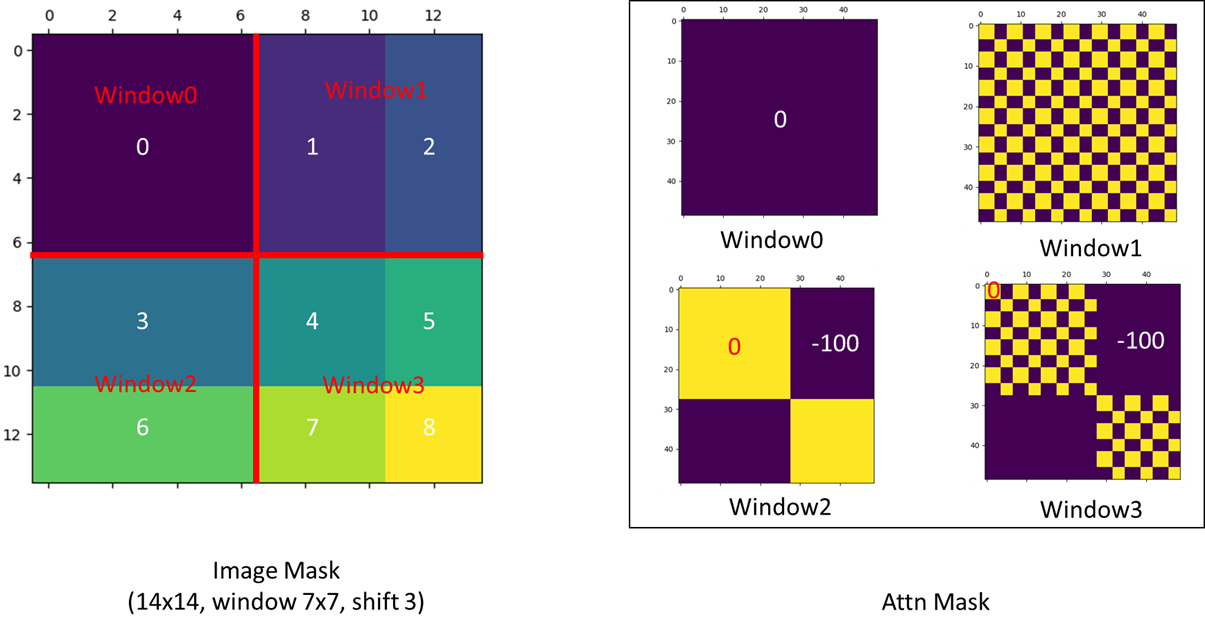
The Question about the mask of window attention #38 https://github.com/microsoft/Swin-Transformer/issues/38
RegNet 由 Facebook 用 NAS 搜出的模型,Efficient Net 是 google 用 NAS 搜索出的模型性能都很好。之前的 VIT 由于没有用好的数据增强,而且缺少偏置归纳所以效果较差。 而 DeiT 用了更好的数据增强和模型蒸馏的方法效果更好。而 Swin 效果更好一些。 但与 Efficient Net 不分伯仲,虽然效果胜于 EffNet 但参数量计算速度不如 EffNet b 展示,先在更大的数据集上做预训练,在在 ImageNet-1k 上微调做测试,会提升其性能。
- 局部性:同一个物体的不同部位或者是语义相近的不同物体还是大概率会出现在相连的地方。所以在 local 一个小范围的窗口去计算自注意力也是差不多够用的,全局计算对于视觉任务是有些浪费资源的。
-
Patch Merging 十分类似于 Pixel Shuffle 的上采样的反过程。Pixel Shuffle 是 low level 任务中常用的上采样。
- NAS 神经网络架构搜索
- 神经网络架构搜索是一种自动化的方法,用于搜索最佳的神经网络架构来解决特定的任务。 它通过在给定的搜索空间中评估和优化不同的网络结构,来找到最适合的架构。 神经网络架构搜索的目标是在给定的计算资源限制下,找到一个性能最佳的神经网络架构。 它可以通过遗传算法、强化学习、贝叶斯优化等方法进行搜索。
在进行神经网络架构搜索时,以下是一些常见的步骤和考虑因素:
- 定义搜索空间:确定神经网络架构的可选组件和参数范围,例如层数、节点数、卷积核大小等。
- 评估策略:定义一个性能指标,用于评估每个网络结构的表现,例如准确率、速度等。
- 搜索算法:选择合适的搜索算法来遍历搜索空间并找到最佳架构。常用的方法包括遗传算法、强化学习和贝叶斯优化等。
- 训练和评估:对每个候选架构进行训练和评估,以确定它们在给定任务上的性能。
- 迭代优化:根据评估结果调整搜索策略,并进行多次迭代以找到最佳架构。
数学基础 —— 生成模型必备知识
https://pytorch.org/vision/stable/models.html
ConvNext
RegNet
EfficientNet
某种程度上可以说,Swin Transformer 就是披着 Transformer 皮的 CNN。 Swin Transformer 像 CNN 一样具有层级式结构,而且它的计算复杂度是跟输入图像的大小呈线性增长的。这种层级式结构使得它在下游任务上的表现非常好,如 Swin Transformerr 在 COCO 和 ADE20K 上的效果都非常的好,远远超越了之前最好的方法。
最大的创新就是使用了基于 Shifted Window 的自注意力,可以看到,相比于全局自注意力,它在有效地减少了的计算量的同时,还保持了很好的效果,因此对很多视觉的任务,尤其是对下游密集预测型的任务是非常有帮助的。
但是如果 Shifted Window 操作不能用到 NLP 领域里,其实在模型大一统上论据就不是那么强了,所以作者说接下来他们的未来工作就是要把 Shifted Windows 用到 NLP 里面(看了下 github,现在还没有实现),如果真的能做到这一点,那 Swin Transformer 真的就是一个里程碑式的工作了,NLP 和 CV 模型真正大一统的未来也就来了。
如何判断(你自己的)研究工作的价值
09:00
- 用有新意的方法
- 有效的解决
- 一个研究问题
AlphaFold 2 论文精读
1:15:29 MSA row-wise gated self-attention with pair bias.
好复杂的模型。
突然想起来中科院张真人说过的一句话:如果你看到了科学的突破进展,只能说明你还没有搞懂发展历史。真正的科学进步都是一点一点堆起来的。
你(被)吐槽过论文不够 novel 吗?
14:11
CLIP 论文逐段精读
1:38:26 我个人感觉,4 亿张图片的训练集就肯定或多或少包括了那 30 类数据集中相似的图片,就像 LLM 那种,我感觉这些 zero-shot 就其实都是早就 train 过的原因。
CLIP 为 CV 研究者打开了一片非常非常广阔的天地,原因在于 CLIP 真的把自然语言级别的抽象概念带到计算机视觉里了。当然肯定有其它类似工作,但 CLIP 跨过了奇点。
数据集
作者在 Prompt_Engineering_for_ImageNet.ipynb
列出了使用的这 80 个 context prompts,比如有 "a photo of many {}" 适合包含多个物体的情况,"a photo of the hard to see {}" 可能适合一些小目标或比较难辨认的目标。

- itap of a {}.
- a bad photo of the {}.
- a origami {}.
- a photo of the large {}.
- a {} in a video game.
- art of the {}.
- a photo of the small {}.
上面的 prompt template 是 a photo of a {} Prompt engineering:避免歧义和与 NLP 那边保持一致,避免 distribution gap(分布误差) Prompt ensembling:多用提示的模板 prompt template,然后综合一下选最高的 这个就是咒语。
Torch 计算 Cross-Entropy 时直接输入 label 的 id,它会先转成一个 one-hot 矩阵,np.range(n) 就会因此转为一个 n 维的单位矩阵,正好跟文本表征和图片表征的相似矩阵计算交叉熵。
一文读懂三篇少样本微调 CLIP 的论文及代码实现细节 
局限
- 还是没有 SOTA(跟领域最好的,包括有监督)
- 某些数据集不好,有 bias
- MNIST 很差,因为 4 亿里没有
- 虽然 CLIP 可以做 zero-shot 的分类任务,但它还是在你给定的这些类别中去做选择
- 4 亿还是太夸张了,自监督和伪标签
- 调参和 tricks 还是用了很多
- 通过自然语言引导图像分类器是一种灵活和通用的接口,但它有自己的局限性。 许多复杂的任务和视觉概念可能很难仅仅通过文本来指导,即使用语言也无法描述。
- 实验还是在监督的数据集做,对于 zero-shot 来说还是不好
- 政治、性别、宗教
- 当从 zero-shot 转换到设置 few-shot 时,当 one-shot、two-shot、four-shot 时反而不如 zero-shot, 不提供训练样本时反而比提供少量训练样本时差了,这与人类的表现明显不同, 人类的表现显示了从 zero-shot 到 one-shot 大幅增加。 今后需要开展工作,让 CLIP 既在 zero-shot 表现很好,也能在 few-shot 表现很好。 作者:鸡笋 Jeasun https://www.bilibili.com/read/cv25773666/ 出处:bilibili
[中文字幕] OpenAI CLIP 论文解读 https://www.bilibili.com/video/BV1Cv411h72S/
双流网络论文逐段精读
52:57 视频理解。 Two-Stream Convolutional Networks for Action Recognition in Videos
- 空间流
- 时间流
GPT,GPT-2,GPT-3 论文精读
1:29:59
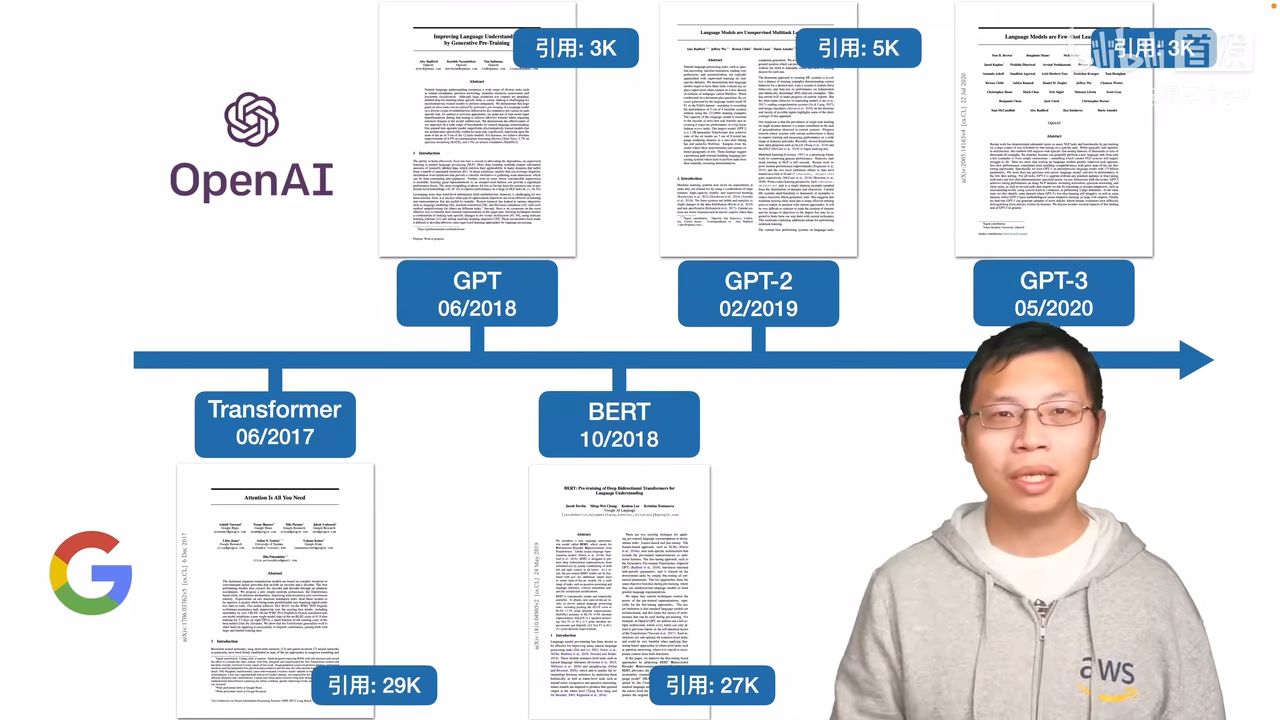
沐神关于做研究的启发: 做研究不要一条路走到黑,做过程你可以一条路走到黑,但是在做研究的时候,你要灵活一些,不要一条路走到黑。你需要尝试从一个新的角度来看问题。
gpt2 还是做语言模型,但是在做到下游任务的时候,会用一个叫做 zero-shot 的设定,zero-shot 是说,在做到下游任务的时候,不需要下游任务的任何标注信息,那么也不需要去重新训练已经预训练好的模型。这样子的好处是我只要训练好一个模型,在任何地方都可以用。 如果作者就是在 gpt1 的基础上用一个更大的数据集训练一个更大的模型,说我的结果比 Bert 好一些,可能也就好那么一点点,不是好那么多的情况下,大家会觉得 gpt2 这篇文章就没什么意思了,工程味特别重。那么我换一个角度,选择一个更难的问题,我说做 zero-shot。虽然结果可能没那么厉害了,没那么有优势,但是新意度一下就来了。
- translate to french, english text, french text.
- answer the question, document, question, answer.
https://blog.csdn.net/zcyzcyjava/article/details/127006287
- Zero-shot learning – 零样本学习
- One-shot learning – 单样本学习
- Zero-shot learning 指的是我们之前没有这个类别的训练样本。但是我们可以学习到一个映射 $X->Y$。 如果这个映射足够好的话,我们就可以处理没有看到的类了。 One-shot learning 指的是我们在训练样本很少,甚至只有一个的情况下,依旧能做预测。 这是如何做到呢?可以在一个大数据集上学到 general knowledge(具体的说,也可以是 $X->Y$ 的映射), 然后再到小数据上有技巧的 update。
- Few-shot learning – 小样本学习
- 如果训练集中,不同类别的样本只有少量,则成为 Few-shot learning. 就是给模型待预测类别的少量样本,然后让模型通过查看该类别的其他样本来预测该类别。 比如:给小孩子看一张熊猫的照片,那么小孩子到动物园看见熊猫的照片之后,就可以识别出那是熊猫。
去重复,LSH 算法(Local Sensitive Hash)。
人脑相当于一个已经预训练好的模型,预训练来自于基因遗传?!
OpenAI Codex 论文精读
47:59
DeepMind AlphaCode 论文精读
44:01 有点像机器翻译。
I can safely say the results of AlphaCode exceeded my expectations. I was skeptical because even in simple competitive problems it is often required not only to implement the algorithm, but also (and this is the most difficult part) to invent it. AlphaCode managed to perform at the level of a promising new competitor. I can't wait to see what lies ahead!
斯坦福 2022 年 AI 指数报告精读
1:19:56
I3D 论文精读
52:31
- CNN + LSTM
- 3D
- 双流网络
I3D Two-Stream Inflated 3D ConvNets
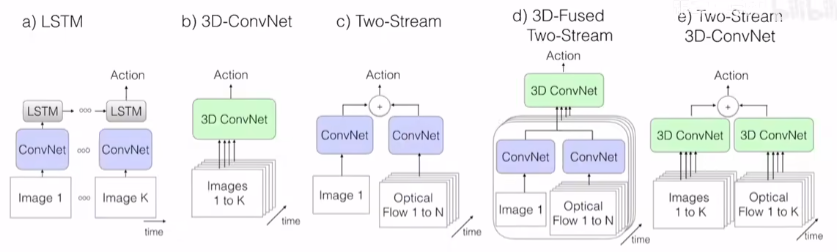
Bootstrapping 3D filters from 2D Filters. 从预先训练的 ImageNet 模型中引导参数来初始化 I3D: 作者将图像重复复制到视频序列中将图像转换为 (boring) 视频。 然后,在 ImageNet 上对 3D 模型进行隐式预训练,满足我们所谓的无聊视频固定点 ((boring) 视频上的池化激活应与原始单个图像输入上的池化激活相同 ),这可以实现通过在时间维度上重复 2D 滤波器的权重 N 次,并且通过除以 N 来重新缩放它们,这确保了卷积滤波器响应是相同的。
视频理解论文串讲(上)
51:15 TSN 很多分段算结果。
参数服务器(Parameter Server)逐段精读
1:37:40

数据压缩 灵活的一致性的模型和容灾 一致性哈希 向量钟
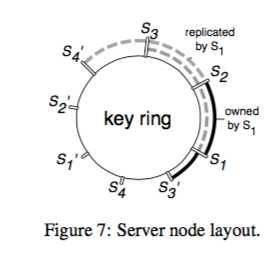
大规模机器学习框架的四重境界 https://www.leiphone.com/category/yanxishe/89T9wKWOxwCTCSHZ.html
视频理解论文串讲(下)
1:08:32
有些 AI 论文会做很多实验,就没有出乌龙或者 bug 的吗?
这个卷积呢,拆分成了一个顺序的啊,先做空间再做时间的卷积形式。 那作者这里呢,也说了两点啊,就是说这种拆分的形式为什么比原来这个纯使用 3D 网络的好的原因。
- 就是增强了网络这个非线性。因为你原来如果只有一个 3d com 的话,你后面就只接了一个外路激活层,所以你只做了一次非线性操作。但是你现在呢,做了两次卷积,那你每个卷积后面都有一个外路激活层,那就有两次非线性的变化。你这个模型的非线性。这能力就加强了,那他的学习能力也就增加了。
- 从优化的角度来看啊,如果你直接去学一个 3D 卷积的话,那是不好学的。那如果你把它拆分成一个 2D 和 1D 来说呢,它就相对容易优化一些。
时间维度,不做下采样。
Pathways 论文精读
1:02:14 这届航展非常特别,几乎是一个转折点,武器全面无人化、智能化。也算是 AI 的下游应用了,机器狗已经能达到实战的水平了。 Keras 之父谷歌离职,tensorflow 败给了 pytorch。
GPipe 论文精读
58:48
在大模型训练里,几种经典的分布式并行范式: 流水线并行(Pipeline Parallelism),数据并行(Data Parallelism)和张量并行(Tensor Parallesim)。
经典的流水线并行范式有 Google 推出的 Gpipe,和微软推出的 PipeDream。 两者的推出时间都在 2019 年左右,大体设计框架一致。 主要差别为:在梯度更新上,Gpipe 是同步的,PipeDream 是异步的。 异步方法更进一步降低了 GPU 的空转时间比。 虽然 PipeDream 设计更精妙些,但是 Gpipe 因为其“够用”和浅显易懂,更受大众欢迎(torch 的 pp 接口就基于 Gpipe)。
note
时间换空间。主要思路是用算力换内存(计算换显存,反向求导时需要的中间结果从 checkpoint 重新计算),以及用带宽换显存。

很多地方没彻底听明白了。
Megatron LM 论文精读
56:08 Colossal-AI 并行技术 模型并行,即模型被分割并分布在一个设备阵列上。 通常有两种类型的并行:张量并行和流水线并行。 张量并行是在一个操作中进行并行计算,如矩阵-矩阵乘法。 流水线并行是在各层之间进行并行计算。 因此,从另一个角度来看,张量并行可以被看作是层内并行,流水线并行可以被看作是层间并行。
序列并行 序列并行是一种对于序列维度进行切分的并行策略,它是训练长文本序列的有效方法。 现成熟的序列并行方法包括 megatron 提出的序列并行,DeepSpeed-Ulysses 序列并行和 ring-attention 序列并行等。
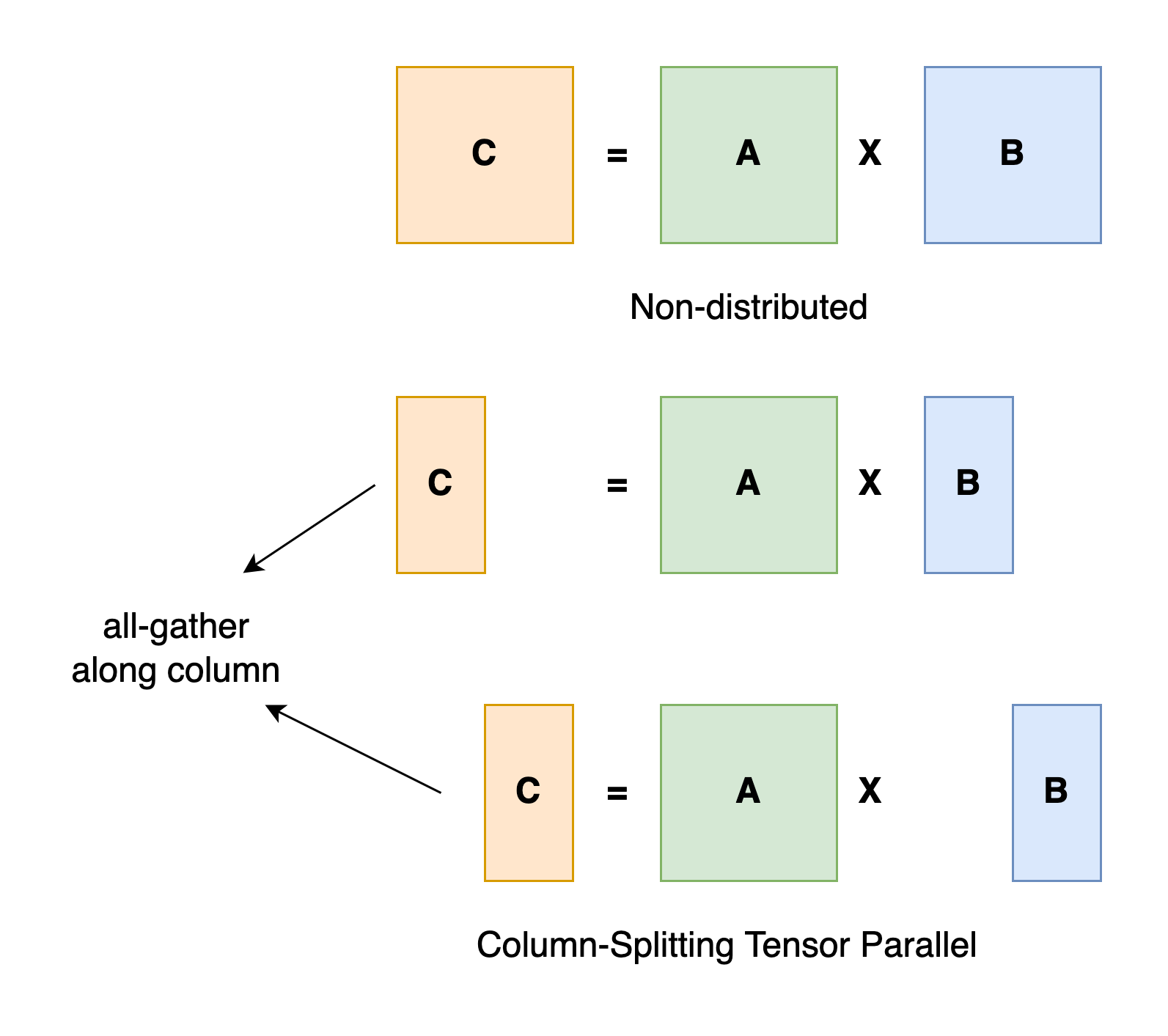
张量并行

机器基本上一个亿的人民币了。
megatron sp
该序列并行方法是在张量并行的基础上实现的序列并行,模型并行的每个 gpu 上,样本独立且重复的,对于非线性运算的部分如 layernorm 等无法使用张量并行的模块,可以在序列维度将样本数据切分为多个部分,每个 gpu 计算部分数据,然后在计算 attention 及 mlp 等线性部分使用张量并行策略,需要将 activation 汇总,这样可以在模型进行切分的情况下进一步减少 activation 的内存占用,需要注意的是该序列并行方法只能与张量并行一起使用。
DeepSpeed-Ulysses
序列并行通过在序列维度上分割样本并利用 all-to-all 通信操作,使每个 GPU 接收完整序列但仅计算注意力头的非重叠子集,从而实现序列并行。该并行方法具有完全通用的 attention,可支持密集和稀疏的注意力。 alltoall 是一个全交换操作,相当于分布式转置的操作,在 attention 计算之前,将样本沿序列维度进行切分,每个设备只有 N/P 的序列长度,然而使用 alltoall 后,qkv 的子部分 shape 变为 [N, d/p],在计算 attention 时仍考虑了整体的序列。
ring attention
ring attention 思路借鉴了 flash attention 的分块精确计算:每个 GPU 保留一段 query,并沿环传递不同的 key/value 子块,逐块累积 softmax 和输出,从而得到完整 attention,而不是只做局部 attention 再简单归约。在 Ring Attention 中,输入序列被沿着序列维度切分为多个块,每个块由不同的 GPU 或处理器负责处理,Ring Attention 采用了一种称为“环形通信”的策略,通过跨卡的 p2p 通信相互传递 kv 子块来实现迭代计算,可以实现多卡的超长文本。在这种策略下,每个处理器只与它的前一个和后一个处理器交换信息,形成一个环形网络。通过这种方式,中间结果可以在处理器之间高效传递,减少全局同步开销。
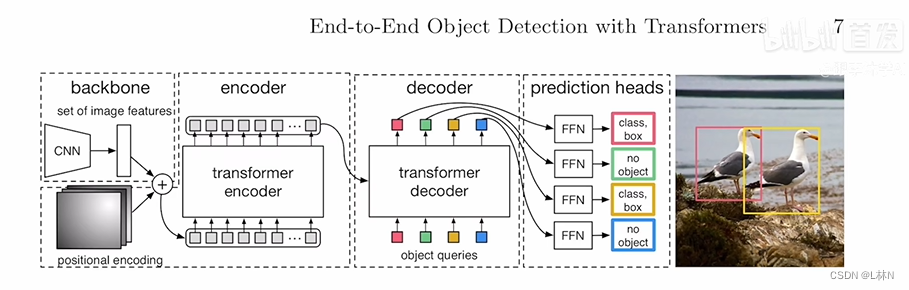
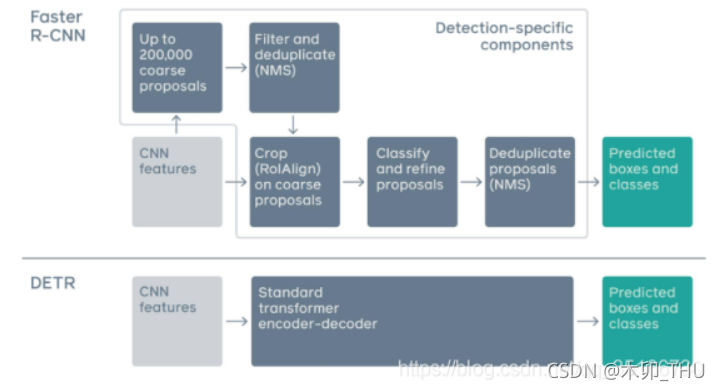
DETR 论文精读
54:23 End-to-End Object Detection with Transformers
目标检测模型后处理(非极大值抑制 NMS 与 WBF) 非极大值抑制(Non-Maximum Suppression,NMS),顾名思义就是抑制不是极大值的元素,可以理解为局部最大搜索。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。
This paper aims to bridge this gap.
使用了 Transformer Encoder,每一个点或者说每一个特征就跟这个图片里其他的特征都会有交互。 那这样呢,他大概就知道哪块儿是哪个物体啊,哪块儿又是另外一个物体。 那对于同一个物体来说呢,你就只应该出一个框,而不是出好多个框。
- 用卷积神经网络抽特征啊。
- 用 Transformer Encoder 去学全局特征,帮助后面做检测。
- 用 Transformer Decoder 去生成很多的这个预测框。
- 把这个预测的框和 Ground Truth 的框做一个匹配,然后最后在匹配上的这个框里面去算这个目标检测的话。
二分图最大匹配问题匈牙利算法。 就是你从二分图中找出一条路径来,让路径的起点和终点都是还没有匹配过的点,并且路径经过的连线是一条没被匹配、一条已经匹配过,再下一条又没匹配这样交替地出现。找到这样的路径后,显然路径里没被匹配的连线比已经匹配了的连线多一条,于是修改匹配图,把路径里所有匹配过的连线去掉匹配关系,把没有匹配的连线变成匹配的,这样匹配数就比原来多 1 个。不断执行上述操作,直到找不到这样的路径为止。
而 $\mathcal{L}_{macth}$
则使用 scipy.optimize 这个库中的 linear_sum_assignment 函数即匈牙利算法的实现获得。
在论文的最后,作者给出了 DETR 的伪代码,其实就是 pytorch 的代码。 优雅,太优雅了。
import torch
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads,
num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)
Encoder 在学什么呢?Encoder 在学一个全局的特征。它是尽可能的让这些物体和物体之间分的开,但是呢,光分开还是不够的。对于这些头尾巴这些极值点最外围的这些点该怎么办呢?这个呢,就交给 Decoder 去做了。因为 Encoder 已经把这个物体都分好了。所以,Decoder 接下来呢,就可以把所有的注意力都分到去学这个边缘了,去怎么更好的区分物体啊,以及解决这种遮挡问题。
这就有点儿像之前做分割的时候,我们用这种 U-NET 的结构,就是说 Encoder 啊,去抽一个更有语义的特征。然后 Decoder 这边呢,一边一点一点儿把这个图片大小恢复出来啊,另外一边呢,把更多的细节加进去啊,从而能导成最后的这个分割效果很好啊,或者是图片重建的效果很好。
RT-DETR
是第一个实时端到端目标检测器。具体而言,我们设计了一个高效的混合编码器,通过解耦尺度内交互和跨尺度融合来高效处理多尺度特征,并提出了 IoU 感知的查询选择机制,以优化解码器查询的初始化。
RT-DETR 支持通过使用不同的解码器层来灵活调整推理速度,而不需要重新训练,这有助于实时目标检测器的实际应用。
推动进步的是 洞见(insight)而非技巧(trick)。 比如文档分类任务: [洞见] 通过研究文档的层次结构,提出一种分层注意力机制,从字、句到段落逐级建模,从而更好地捕捉语义层次关系。 这种洞见强调了对文档本质的理解,并为其他自然语言任务提供了新思路。 [技巧] 在现有 Transformer 架构中增加一个特定的附加层,只对当前数据集有效,提升了 1% 的准确率。 技巧虽然提升了性能,但只是“调参”的延伸,不具有一般性。
Zero 论文精读
DeepSpeed
52:21 另一种并行方法和优化器相关,目前这种并行最流行的方法是 ZeRO,即零冗余优化器。 ZeRO 在三个层面上工作,以消除内存冗余(ZeRO 需要进行 fp16 训练)。
- Level 1: 优化器状态在各进程中被划分。
- Level 2: 用于更新模型权重的 32 位梯度也被划分,因此每个进程只存储与其优化器状态划分相对应的梯度。
- Level 3: 16 位模型参数在各进程中被划分。
compute/communication efficiency 人月神话。一个公司的做一个项目也是这样大多数时间用在沟通上面了。
zero3 切 weight, 每张卡存一部分,但是整整计算的时候,还是会使用完整的 weight 计算,还是属于 数据并行。 megatron 中切 weight 是张量并行。
“ZeRO 就好比两个去野外跋涉的人,分别随身带着帐篷和搭帐篷的工具。 白天他们各自行动,晚上就会聚在一起搭帐篷过夜。 过夜后各自拿上各自的东西,继续赶路”。
一 · 跟读者建立联系【论文写作】Becoming a Researcher
45:02
book
note
《The Craft of Research, Fourth Edition (Chicago Guides to Writing, Editing, and Publishing)》

读者知道什么了,他们接下来想要知道什么。 整个论文的写作,就是跟你的读者的一个无声的交流。 跟正常的交流不一样的是说,他不是互动的,而说你要一开始就想好,整个交流应该是一个什么的过程,要想清楚读者是谁,他们需要什么。 所以你在写文章时,而写的能满足他们的需求,使得他们能信服你写的东西。
- 1 Thinking in Print: The Uses of Research, Public and Private
- 1.1 What Is Research?
- 1.2 Why Write It Up?
- 1.3 Why a Formal Paper?
- 1.4 Writing Is Thinking
研究是什么: Gather information to answer a question that solves a problem.
写作的好处: We write to remember more accurately, understand better, and evaluate what we think more objectively.
- Write to Remenber
- Write to Understand
- Write to Test Your Thinking
论文格式,是同行交流的一个协议。
Write is Thinking Writing a research report is, finally, thinking with and for your readers. If instead you find a topic that you care about, ask a question that you want to answer.
- 2 Connecting with Your Reader: Creating a Role for Yourself and Your Readers
- 2.1 Conversing with Your Readers
- 2.2 Understanding Your Role
- 2.3 Imagining Your Readers’ Role
- ★ Quick Tip: A Checklist for Understanding Your Readers
为你自己和读者都创建一个角色。 Research counts for little if few read it. Yet even experienced researchers sometimes forget to keep their readers in mind as they plan and draft their report. In this chapter we show you how to think about readers even before you begin your project.
Writing is an imagined conversation. once we decide what role to play and what role to assign to readers, those roles are fixed.
作者的角色有三种:
- I’ve Found Some New and Interesting Information
- I’ve Found a Solution to an Important Practical Problem
- I’ve Found an Answer to an Important Question
读者的角色也有三种:
- 娱乐我。Entertain Me
- Help Me Solve My Practical Problem
- Help Me Understand Something Better
没有找准读者的角色,可能会造成读者反馈: I don't care.
A Checklist for Understanding Your Readers
Think about your readers from the start, knowing that you’ll understand them better as you work through your project. Answer these questions early on, then revisit them when you start planning and again when you revise.
-
Who will read my report?
- Professionals who expect me to follow every academic convention and use a standard format?
- Well-informed general readers?
- General readers who know little about the topic?
-
What do they expect me to do? Should I
- entertain them?
- provide new factual knowledge?
- help them understand something better?
- help them do something to solve a practical problem in the world?
-
How much can I expect them to know already?
- What do they know about my topic?
- Is the problem one that they already recognize?
- Is it one that they have but haven’t yet recognized?
- Is the problem not theirs, but only mine?
- Will they take the problem seriously, or must I convince them that it matters?
-
How will readers respond to the solution /answer in my main claim?
- Will it contradict what they already believe? How?
- Will they make standard arguments against my solution?
- Will they want to see the steps that led me to the solution?
明白问题的重要性【研究的艺术 · 二】Planning Your Project—An Overview
1:03:40
你先找到大小合适的话题,然后问一些问题,然后把一个读者认为值得去了解答案的问题抽出来,做成一个研究问题。
研究问题可能是实际的也可能是概念上的,那不管是哪类问题,你都要想清楚,一它的状况是什么,二不解决它的话,它的后果是什么,但后面两节是说给一个问题的时候,你怎么样找到。资源就是找到前面的工作,然后怎么样读懂别人的工作,以及把你的工作放在别人的工作之上。
就是话题、问题以及它的后果。
- ★ Quick Tip: Creating a Writing Group
- 3 From Topics to Questions
- 3.1 From an Interest to a Topic
- 3.4.1 Step 1: Name Your Topic 你的话题是什么?
- 3.4.2 Step 2: Add an Indirect Question 你在这个话题里面的问题是什么?
- 3.4.3 Step 3: Answer So What? by Motivating Your Question 为什么别人会在意这个事情。
- 3.2 From a Broad Topic to a Focused One
- 3.3 From a Focused Topic to Questions
- 3.4 The Most Significant Question: So What?
- ★ Quick Tip: Finding Topics
- 4 From Questions to a Problem
- 4.1 Understanding Research Problems4.2 Understanding the Common Structure of Problems
- 4.3 Finding a Good Research Problem
- 4.3.1 Ask for Help
- 4.3.2 Look for Problems as You Read
- 4.3.3 Look at Your Own Conclusion
- 4.4 Learning to Work with Problems
- ★ Quick Tip: Manage the Unavoidable Problem of Inexperience
- 5 From Problems to Sources
- 5.1 Three Kinds of Sources and Their Uses
- 5.2 Navigating the Twenty-First-Century Library
- 5.3 Locating Sources on the Internet
- 5.4 Evaluating Sources for Relevance and Reliability
- 5.5 Looking Beyond Predictable Sources
- 5.6 Using People to Further Your Research
- ★ Quick Tip: The Ethics of Using People as Sources of Data
- 6 Engaging Sources
- 6.1 Recording Complete Bibliographical Information
- 6.2 Engaging Sources Actively
- 6.3 Reading for a Problem
- 6.4 Reading for Arguments
- 6.5 Reading for Data and Support
- 6.6 Taking Notes
- 6.7 Annotating Your Sources
- ★ Quick Tip: Manage Moments of Normal Anxiety
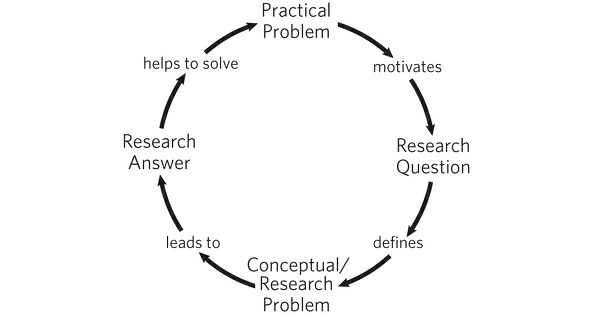
A topic is an approach to a subject, one that asks a question whose answer solves a problem that your readers care about.
Even so, once you have a question that holds your interest, you must pose a tougher one about it: So what?
At that point, you have posed a problem that they recognize needs a solution.
DALL·E 2
1:27:55 扩散模型其实就是一种多层的 VAE?!
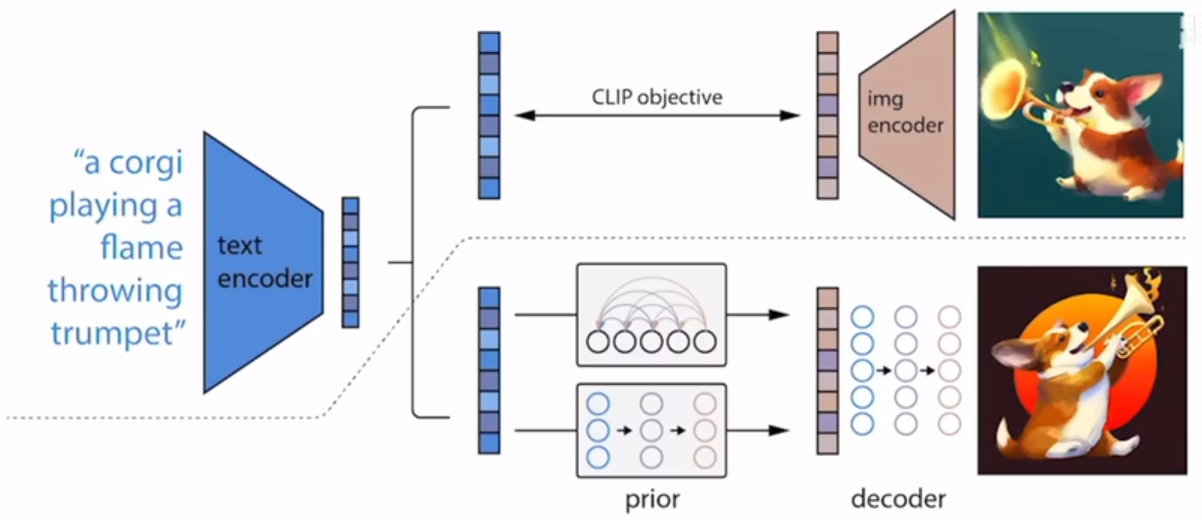
Prior,加了一步映射,从文本映射到图像特征,让文本对特征的影响通过解码器放大。
- AE
- DAE
- VAE: 本质上是强迫中间这个表征在空间里面可以随机去取都会有意义。
- 并不是所有空间都有有效语义,但是 vae 也比 ae 缓解了很多。
- VAE 里的方差和均值,是学到的,因为给了编码器监督信息,通过 $KL$ 散度作为损失函数,强制编码器的输出是高斯分布。这是 vae 的核心思想。
- VQVAE
DALL-E 2 的训练过程为:
- 训练一个 CLIP 模型,使其能够对齐文本和图片特征。
- 训练一个先验模型,由自回归模型或者一个扩散先验模型(实验证明,扩散先验模型表现更好),其功能是将文本表征映射为图片表征。
- 训练一个扩散解码模型,其目标是根据图片表征,还原原始图片。
有想法和实现是天差地别的,几万人可能都想到这么简单的思路框架,但是各个细节做出来的才是真的。

讲好故事、论点【研究的艺术 · 三】
43:57
理由、论据和担保【研究的艺术 · 四】
44:14
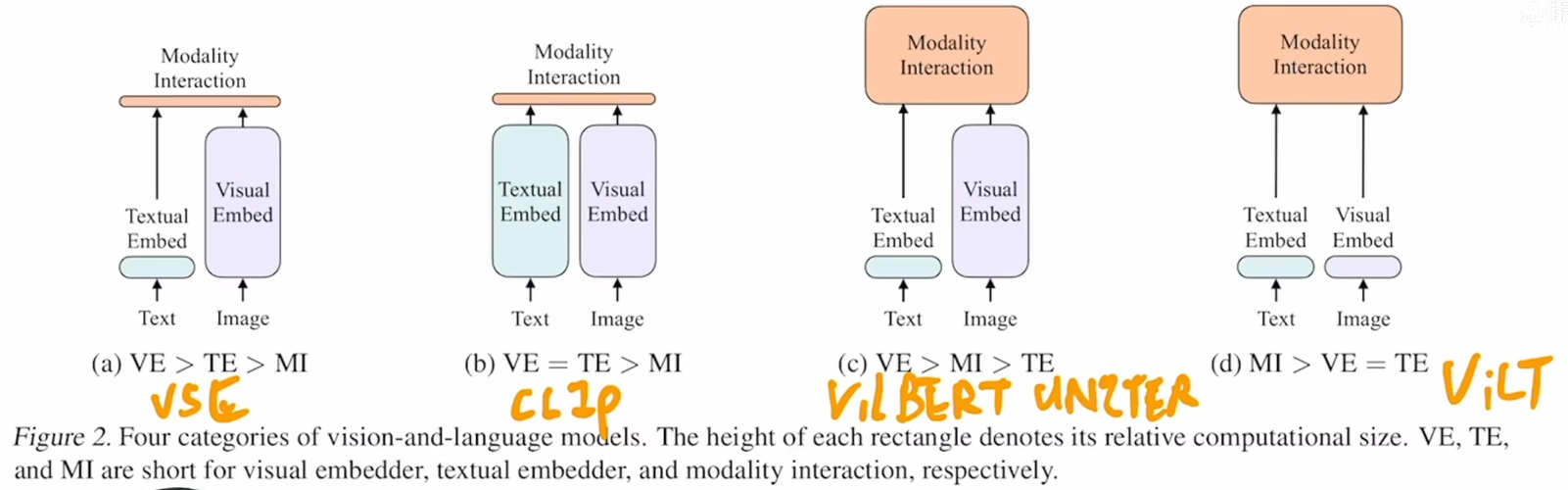
ViLT 论文精读
1:03:26 目标检测。Vision-and-Language Transformer Without Convolution or Region Supervision
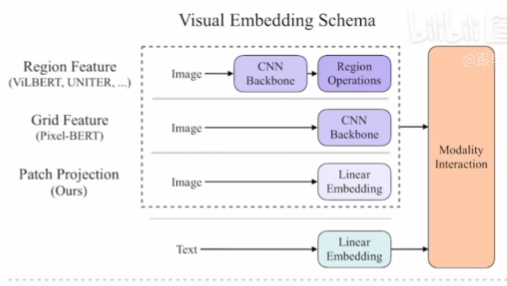
- ViLT is the simplest architecture by far for a vision.and-language model as it commissions the transformermodule to extract and process visual features in placeof a separate deep visual embedder. This design in-herently leads to significant runtime and parametereffciency.
- For the frst time, we achieve competent performanceon vision-and-language tasks without using region fea-tures or deep convolutional visual embedders in gen-eral.
- Also, for the first time, we empirically show that wholeword masking and image augmentations that were un-precedented in VLP training schemes further drivedownstream performance.
因为 MAE 直接在图像层面恢复,并配合了强大的 decoder,恢复方式和 NLP 完形填空不太一样。 本文则是直接按 NLP 方式恢复,自然不 work。
CLIP 改进工作串讲(上)
1:15:43
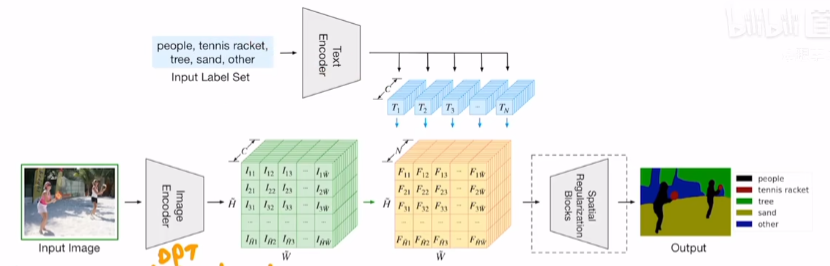
AI 发展到后来,有点“实验科学”的味道,说不清为啥,但是效果好。来不及了,大家都在做一样的工作,论文抢着赶紧发。
有很多地方没听懂。mark
听.*懂|看.*懂|读.*懂
分割: LSeg GroupViT IoU(Intersection over Union,交并比)
目标检测: ViLD \(\begin{aligned} & \mathbf{e}_r=\mathcal{R}(\phi(I), r) \\ & \mathbf{z}(r)=\left[\operatorname{sim}\left(\mathbf{e}_r, \mathbf{e}_{b g}\right), \operatorname{sim}\left(\mathbf{e}_r, \mathbf{t}_1\right), \cdots, \operatorname{sim}\left(\mathbf{e}_r, \mathbf{t}_{\left|C_B\right|}\right)\right] \\ & \mathcal{L}_{\text {ViLD-text }}=\frac{1}{N} \sum_{r \in P} \mathcal{L}_{\mathrm{CE}}\left(\operatorname{softmax}(\mathbf{z}(r) / \tau), y_r\right) \end{aligned}\)
注意这个过程只是为了类别识别,不涉及检测 本质是把 CLIP 的图像编码方式迁移到 ViLD,保证他俩将特征映射到同一空间, 从而也就使得 CLIP 编码的文本特征也能跟 ViLD 对应上,也就可以实现新类别识别。
GLIP GLIP 本质上是将 目标检测任务 转化为 “短语(Phrase)” 识别任务,让检测框(bounding box)和语言描述在同一特征空间中对齐。
传统的视觉技术仅理解图片内容,但无法深入理解分类方式。它只是将物体,如猫、狗、房子、车、人等,分配到不同的框内,而无法解释为何这样分类。由于缺乏语言的辅助,这种分类方式是线性的,而非高维的。
在自然语言的加持下,视觉分类发生了重大变化。无论是 CNN 还是 Vision Transformer,它们的分类方式已与语言模型实现了一一对应。语言模型本质上是在高维空间中划分向量,而非简单的 A、B、C、D 式单维分类。这种图片与语言的 Transform 方法实现了双向对齐,使得模型能够在全网海量数据的训练下,构建更全面的世界认知。
例如,训练时仅出现猫、老虎、狮子,而测试时出现豹子。传统算法可能无法正确分类,而新的算法能推理出豹子属于猫科哺乳动物,即使未曾见过,也能在高维空间中找到相应位置,仅需增加一个新标签即可理解其含义。这正是新一代模型的核心优势。
GLIPv2
CLIP 改进工作串讲(下)
1:04:26 CLIPasso: Semantically-Aware Object Sketching
CLIPasso 利用 CLIP 进行感知引导优化,将图像逐步简化为具有抽象风格的矢量草图,同时保持语义一致性。
CLIP4Clip 通过利用 CLIP 的预训练能力,将视频检索问题转换为视频-文本匹配问题,并通过不同的匹配策略提升检索效果。它的优势在于减少计算开销,同时能在零样本(zero-shot)和少样本(few-shot)场景下取得较好的表现。
ActionCLIP Cross-Entropy 和 KL-divergence 作为目标函数效果是一样的,从数学上来说相差一个常数。 更准确地说,\(D_{KL}(P\|Q)=H(P,Q)-H(P)\),当真实分布 \(P\) 固定时,优化交叉熵等价于优化 KL 散度;one-hot 标签下 \(H(P)=0\)。
AudioCLIP
PointCLIP
DepthCLIP
| Prompt number | Prompt design details (in semantic token words) |
| Original prompt | [giant, extremely close, close, not in distance, a little remote, far, unseen] |
| Prompt 1 | [extremely close, close, middle, a little far, far, quite far, unseen] |
| Prompt 2 | [extremely close, very close, close, a little close, a little far, far, unseen] |
| Prompt 3 | [giant, close, a little close, not in distance, a bit remote, far, unseen] |
Implementation Details We implement our model with the PyTorch framework. Our image and textual encoders employ the pre-trained ResNet-50 [9] of CLIP [19]. For semantic prompts, we tested various kinds of hand-craft prompts, and pick "This object is [distance class]". For semantic distance classes, we investigated diverse combinations and select [’giant’, ’extremely close’, ’close’, ’not in distance’, ’a little remote’, ’far’, ’unseen’], 7 semantic bins in total. Each of which aligns with a depth bin of [1.00, 1.50, 2.00, 2.25, 2.50, 2.75, 3.00]. We set this setting for our main experiments since the range of indoor depth could be properly captured under such proper numbers of semantic and depth bins. The temperature of the final softmax function is set to 0.1.
总结三点关于通用模型(如 CLIP)的使用方式:
-
最小改动方式 :直接利用预训练模型(如 CLIP)提取特征,并将其与原有特征融合(如点乘或拼接),保持原有训练框架不变,仅通过更优特征增强模型性能。
-
蒸馏方式 :将通用模型作为 教师模型(Teacher) ,通过特征蒸馏(如提取中间或最终特征)来提升当前模型的学习效率,使其更快收敛,适用于不同模态和任务(如 3D 任务)。
-
对比学习方式 :不直接使用预训练参数,而是借鉴多模态对比学习的思想,定义正负样本,计算对比学习损失(contrastive loss),从而提升任务表现,如自由设定的检测(detection)或分类(classification)。
总体而言,当前趋势是利用已训练的大模型,而非为每个小任务单独训练。未来方向包括 高效微调(efficient tuning)、prompt tuning 和 adapter-based 方法 ,在尽量不改变大模型参数的基础上,通过少量可调模块进行高效训练。
Chain of Thought 论文、代码和资源
33:23
OpenAI Whisper 精读
1:12:16
多模态论文串讲 · 上
1:12:25
Neural Corpus Indexer 文档检索
55:47
InstructGPT 论文精读
1:07:11
多模态论文串讲 · 下
1:03:29
HELM 全面语言模型评测
1:23:38
Anthropic LLM 论文精读【论文精读 ·51】
1:01:52
大模型时代下做科研的四个思路【论文精读 ·52】
1:06:29
GPT-4 论文精读【论文精读 ·53】
1:20:39
深度学习论文精读
录制完成的论文
| 日期 | 标题 | 时长 | 视频(播放数) |
|---|---|---|---|
| 3/30/23 | GPT-4 | 1:20:38 | video |
| 3/23/23 | 大模型时代下做科研的四个思路 | 1:06:29 | video |
| 3/10/23 | [Anthropic LLM] | 1:01:51 | video |
| 1/20/23 | [Helm] 全面语言模型评测 | 1:23:37 | video |
| 1/11/23 | 多模态论文串讲 · 下 | 1:03:29 | video |
| 12/29/22 | [Instruct GPT] | 1:07:10 | video |
| 12/19/22 | [Neural Corpus Indexer] 文档检索 | 55:47 | video |
| 12/12/22 | 多模态论文串讲 · 上 | 1:12:27 | video |
| 11/14/22 | OpenAI Whisper 精读 | 1:12:16 | video |
| 11/07/22 | 在讲 OpenAI Whisper 前先做了一个剪视频小工具 | 23:39 | video |
| 10/23/22 | [Chain of Thought] 论文、代码和资源 | 33:21 | video |
| 9/17/22 | CLIP 改进工作串讲(下) | 1:04:26 | video |
| 9/2/22 | CLIP 改进工作串讲(上) | 1:14:43 | video |
| 7/29/22 | [ViLT] 论文精读 | 1:03:26 | video |
| 7/22/22 | 理由、论据和担保【研究的艺术· 四】 | 44:14 | video |
| 7/15/22 | 如何讲好故事、故事里的论点【研究的艺术· 三】 | 43:56 | video |
| 7/8/22 | [DALL·E 2] 逐段精读 | 1:27:54 | video |
| 7/1/22 | 明白问题的重要性【研究的艺术· 二】 | 1:03:40 | video |
| 6/24/22 | 跟读者建立联系【研究的艺术· 一】 | 45:01 | video |
| 6/17/22 | [Zero] 逐段精读 | 52:21 | video |
| 6/10/22 | [DETR] 逐段精读 | 54:22 | video |
| 6/3/22 | [Megatron LM] 逐段精读 | 56:07 | video |
| 5/27/22 | GPipe 逐段精读 | 58:47 | video |
| 5/5/22 | [Pathways] 逐段精读 | 1:02:13 | video |
| 4/28/22 | [视频理解论文串讲](下) | 1:08:32 | video |
| 4/21/22 | 参数服务器(Parameter Server) 逐段精读 | 1:37:40 | video |
| 4/14/22 | [视频理解论文串讲](上) | 51:15 | video |
| 3/31/22 | [I3D] 论文精读 | 52:31 | video |
| 3/24/22 | 斯坦福 2022 年 AI 指数报告 精读 | 1:19:56 | video |
| 3/17/22 | AlphaCode 论文精读 | 44:00 | video |
| 3/10/22 | [OpenAI Codex] 论文精读 | 47:58 | video |
| 3/3/22 | GPT, GPT-2, [GPT-3] 精读 | 1:29:58 | video |
| 2/24/22 | Two-Stream 逐段精读 | 52:57 | video |
| 2/10/22 | CLIP 逐段精读 | 1:38:25 | video |
| 2/6/22 | 你(被)吐槽过 论文不够 novel 吗? | 14:11 | video |
| 1/23/22 | AlphaFold 2 精读 | 1:15:28 | video |
| 1/18/22 | 如何判断(你自己的)研究工作的价值 | 9:59 | video |
| 1/15/22 | [Swin Transformer] 精读 | 1:00:21 | video |
| 1/7/22 | 指导数学直觉 | 52:51 | video |
| 1/5/22 | AlphaFold 2 预告 | 03:28 | video |
| 12/20/21 | 对比学习 论文综述 | 1:32:01 | video |
| 12/15/21 | [MoCo] 逐段精读 | 1:24:11 | video |
| 12/9/21 | 如何找研究想法 1 | 5:34 | video |
| 12/8/21 | [MAE] 逐段精读 | 47:04 | video |
| 11/29/21 | [ViT] 逐段精读 | 1:11:30 | video |
| 11/18/21 | [BERT] 逐段精读 | 45:49 | video |
| 11/9/21 | GAN 逐段精读 | 46:16 | video |
| 11/3/21 | 零基础多图详解 图神经网络(GNN/GCN) | 1:06:19 | video |
| 10/27/21 | [Transformer] 逐段精读 (视频中提到的文献 1) |
1:27:05 | video |
| 10/22/21 | [ResNet] 论文逐段精读 | 53:46 | video |
| 10/21/21 | 撑起计算机视觉半边天的 [ResNet] | 11:50 | video |
| 10/15/21 | AlexNet 论文逐段精读 | 55:21 | video |
| 10/14/21 | 9 年后重读深度学习奠基作之一:AlexNet | 19:59 | video |
| 10/06/21 | 如何读论文 | 06:39 | video |
所有论文
包括已经录制完成和之后将要介绍的论文。选取的原则是 10 年内深度学习里有影响力文章(必读文章),或者近期比较有意思的文章。当然这十年里重要的工作太多了,不可能一一过一遍。在选取的时候我会偏向一些之前 直播课 中没讲到过的。 欢迎大家在 讨论区 里提供建(点)议(歌)。
总论文数 67,录制完成数 32
(这里引用采用的是 semanticscholar,是因为它提供 API 可以自动获取,不用手动更新。)
计算机视觉 - CNN
| 已录制 | 年份 | 名字 | 简介 |
|---|---|---|---|
| ✅ | 2012 | AlexNet | 深度学习热潮的奠基作 |
| 2014 | [VGG] | 使用 3x3 卷积构造更深的网络 | |
| 2014 | [GoogleNet] | 使用并行架构构造更深的网络 | |
| ✅ | 2015 | [ResNet] | 构建深层网络都要有的残差连接。 |
| 2017 | [MobileNet] | 适合终端设备的小 CNN | |
| 2019 | [EfficientNet] | 通过架构搜索得到的 CNN | |
| 2021 | [Non-deep networks] | 让不深的网络也能在 ImageNet 刷到 SOTA |
计算机视觉 - Transformer
| 已录制 | 年份 | 名字 | 简介 |
|---|---|---|---|
| ✅ | 2020 | [ViT] | Transformer 杀入 CV 界 |
| ✅ | 2021 | [Swin Transformer] | 多层次的 Vision Transformer |
| 2021 | [MLP-Mixer] | 使用 MLP 替换 self-attention | |
| ✅ | 2021 | [MAE] | BERT 的 CV 版 |
生成模型
| 已录制 | 年份 | 名字 | 简介 |
|---|---|---|---|
| ✅ | 2014 | GAN | 生成模型的开创工作 |
| 2015 | [DCGAN] | 使用 CNN 的 GAN | |
| 2016 | [pix2pix] | ||
| 2016 | [SRGAN] | 图片超分辨率 | |
| 2017 | [WGAN] | 训练更加容易 | |
| 2017 | [CycleGAN] | ||
| 2018 | [StyleGAN] | ||
| 2019 | [StyleGAN2] | ||
| 2020 | [DDPM] | Diffusion Models | |
| 2021 | [Improved DDPM] | 改进的 DDPM | |
| 2021 | [Guided Diffusion Models] | 号称超越 GAN | |
| 2021 | [StyleGAN3] | ||
| ✅ | 2022 | [DALL.E 2] | CLIP + Diffusion models,文本生成图像新高度 |
计算机视觉 - Object Detection
| 已录制 | 年份 | 名字 | 简介 |
|---|---|---|---|
| 2014 | [R-CNN] | Two-stage | |
| 2015 | [Fast R-CNN] | ||
| 2015 | [Faster R-CNN] | ||
| 2016 | [SSD] | Single stage | |
| 2016 | [YOLO] | ||
| 2017 | [Mask R-CNN] | ||
| 2017 | [YOLOv2] | ||
| 2018 | [YOLOv3] | ||
| 2019 | [CenterNet] | Anchor free | |
| ✅ | 2020 | [DETR] | Transformer |
计算机视觉 - 对比学习
| 已录制 | 年份 | 名字 | 简介 |
|---|---|---|---|
| ✅ | 2018 | [InstDisc] | 提出实例判别和 memory bank 做对比学习 |
| ✅ | 2018 | [CPC] | 对比预测编码,图像语音文本强化学习全都能做 |
| ✅ | 2019 | [InvaSpread] | 一个编码器的端到端对比学习 |
| ✅ | 2019 | [CMC] | 多视角下的对比学习 |
| ✅ | 2019 | [MoCov1] | 无监督训练效果也很好 |
| ✅ | 2020 | [SimCLRv1] | 简单的对比学习(数据增强 + MLP head + 大 batch 训练久) |
| ✅ | 2020 | [MoCov2] | MoCov1 + improvements from SimCLRv1 |
| ✅ | 2020 | [SimCLRv2] | 大的自监督预训练模型很适合做半监督学习 |
| ✅ | 2020 | [BYOL] | 不需要负样本的对比学习 |
| ✅ | 2020 | [SWaV] | 聚类对比学习 |
| ✅ | 2020 | [SimSiam] | 化繁为简的孪生表征学习 |
| ✅ | 2021 | [MoCov3] | 如何更稳定的自监督训练 ViT |
| ✅ | 2021 | [DINO] | transformer 加自监督在视觉也很香 |
计算机视觉 - 视频理解
| 已录制 | 年份 | 名字 | 简介 |
|---|---|---|---|
| ✅ | 2014 | DeepVideo | 提出 sports1M 数据集,用深度学习做视频理解 |
| ✅ | 2014 | [Two-stream] | 引入光流做时序建模,神经网络首次超越手工特征 |
| ✅ | 2014 | [C3D] | 比较深的 3D-CNN 做视频理解 |
| ✅ | 2015 | [Beyond-short-snippets] | 尝试使用 LSTM |
| ✅ | 2016 | [Convolutional fusion] | 做 early fusion 来加强时空间建模 |
| ✅ | 2016 | [TSN] | 超级有效的视频分段建模,bag of tricks in video |
| ✅ | 2017 | [I3D] | 提出 Kinetics 数据集,膨胀 2D 网络到 3D,开启 3D-CNN 时代 |
| ✅ | 2017 | [R2+1D] | 拆分 3D 卷积核,使 3D 网络容易优化 |
| ✅ | 2017 | [Non-local] | 引入自注意力做视觉问题 |
| ✅ | 2018 | [SlowFast] | 快慢两支提升效率 |
| ✅ | 2021 | [TimeSformer] | 视频中第一个引入 transformer,开启 video transformer 时代 |
多模态学习
| 已录制 | 年份 | 名字 | 简介 |
|---|---|---|---|
| ✅ | 2021 | CLIP | 图片和文本之间的对比学习 |
| ✅ | 2021 | [ViLT] | 第一个摆脱了目标检测的视觉文本模型 |
| ✅ | 2021 | [ViLD] | CLIP 蒸馏帮助开集目标检测 |
| ✅ | 2021 | [GLIP] | 联合目标检测和文本定位 |
| ✅ | 2021 | [CLIP4Clip] | 拿 CLIP 直接做视频文本 retrieval |
| ✅ | 2021 | [ActionCLIP] | 用多模态对比学习有监督的做视频动作分类 |
| ✅ | 2021 | [PointCLIP] | 3D 变 2D,巧妙利用 CLIP 做点云 |
| ✅ | 2022 | [LSeg] | 有监督的开集分割 |
| ✅ | 2022 | [GroupViT] | 只用图像文本对也能无监督做分割 |
| ✅ | 2022 | [CLIPasso] | CLIP 跨界生成简笔画 |
| ✅ | 2022 | [DepthCLIP] | 用文本跨界估计深度 |
自然语言处理 - Transformer
| 已录制 | 年份 | 名字 | 简介 |
|---|---|---|---|
| ✅ | 2017 | [Transformer] | 继 MLP、CNN、RNN 后的第四大类架构 |
| ✅ | 2018 | GPT | 使用 Transformer 解码器来做预训练 |
| ✅ | 2018 | [BERT] | Transformer 一统 NLP 的开始 |
| ✅ | 2019 | GPT-2 | 更大的 GPT 模型,朝着 zero-shot learning 迈了一大步 |
| ✅ | 2020 | [GPT-3] | 100 倍更大的 GPT-2,few-shot learning 效果显著 |
系统
| 已录制 | 年份 | 名字 | 简介 |
|---|---|---|---|
| ✅ | 2014 | 参数服务器 | 支持千亿参数的传统机器学习模型 |
| ✅ | 2018 | GPipe | 流水线(Pipeline)并行 |
| ✅ | 2019 | [Megatron-LM] | 张量(Tensor)并行 |
| ✅ | 2019 | [Zero] | 参数分片 |
| ✅ | 2022 | [Pathways] | 将 Jax 拓展到上千 TPU 核上 |
图神经网络
| 已录制 | 年份 | 名字 | 简介 |
|---|---|---|---|
| ✅ | 2021 | 图神经网络介绍 | GNN 的可视化介绍 |
优化算法
| 已录制 | 年份 | 名字 | 简介 |
|---|---|---|---|
| 2014 | [Adam] | 深度学习里最常用的优化算法之一 | |
| 2016 | [为什么超大的模型泛化性不错] | ||
| 2017 | 为什么 Momentum 有效 | Distill 的可视化介绍 |
新领域应用
| 已录制 | 年份 | 名字 | 简介 |
|---|---|---|---|
| 2016 | AlphaGo | 强化学习出圈 | |
| 2020 | AlphaFold | 赢得比赛的的蛋白质 3D 结构预测 | |
| ✅ | 2021 | AlphaFold 2 | 原子级别精度的蛋白质 3D 结构预测 |
| ✅ | 2021 | [Codex] | 使用注释生成代码 |
| ✅ | 2021 | 指导数学直觉 | 分析不同数学物体之前的联系来帮助发现新定理 |
| ✅ | 2022 | AlphaCode | 媲美一般程序员的编程解题水平 |
参考资料快照
- https://www.bilibili.com/video/BV1H44y1t75x/
- https://github.com/mli/paper-reading
- https://www.bilibili.com/video/BV1Hw4m117Ka/
- https://mp.weixin.qq.com/s?__biz=MzI4MDYzNzg4Mw==&mid=2247528921&idx=2&sn=ba9d1de7a493d7f5492a3897a28d3406&chksm=ebb7490ddcc0c01b191f778ddff7fc2508cbd66ade755c4fdab87e61c6afb4f5c64905e31d31&scene=27
- https://alberthg.github.io/2018/05/05/introduction-gan/
- https://www.bilibili.com/video/BV1jh411472S/
- https://zhuanlan.zhihu.com/p/418174496
- https://zhuanlan.zhihu.com/p/659117181
- https://blog.csdn.net/qq_36936443/article/details/124296075
- https://github.com/microsoft/Swin-Transformer/issues/38
- https://pytorch.org/vision/stable/models.html
- https://github.com/openai/CLIP/blob/main/notebooks/Prompt_Engineering_for_ImageNet.ipynb
- https://www.zhihu.com/tardis/bd/art/670622153?source_id=1001
- https://www.bilibili.com/read/cv25773666/
- https://www.bilibili.com/video/BV1Cv411h72S/
- https://blog.csdn.net/zcyzcyjava/article/details/127006287
- https://www.leiphone.com/category/yanxishe/89T9wKWOxwCTCSHZ.html
- https://zhuanlan.zhihu.com/p/613196255
- https://colossalai.org/zh-Hans/docs/concepts/paradigms_of_parallelism/
- https://github.com/lyuwenyu/RT-DETR/blob/main/README_cn.md
- https://github.com/thongvhoang/CS519.M11/blob/master/The_Craft_of_Research_Fourth_Edition.pdf
- https://www.bilibili.com/opus/675153998359035925
- https://openai.com/research/gpt-4
- https://www.bilibili.com/video/BV1vM4y1U7b5
- https://www.bilibili.com/video/BV1oX4y1d7X6
- https://www.bilibili.com/video/BV1XY411B7nM
- https://www.bilibili.com/video/BV1z24y1B7uX
- https://www.bilibili.com/video/BV1fA411Z772
- https://www.bilibili.com/video/BV1hd4y187CR
- https://www.bilibili.com/video/BV1Se411w7Sn
- https://www.bilibili.com/video/BV1Vd4y1v77v
- https://cdn.openai.com/papers/whisper.pdf
- https://www.bilibili.com/video/BV1VG4y1t74x
- https://www.bilibili.com/video/BV1Pe4y1t7de
- https://www.bilibili.com/video/BV1t8411e7Ug
- https://www.bilibili.com/video/BV1gg411U7n4
- https://www.bilibili.com/video/BV1FV4y1p7Lm
- https://www.bilibili.com/video/BV14r4y1j74y
- https://press.uchicago.edu/ucp/books/book/chicago/C/bo23521678.html
- https://www.bilibili.com/video/BV1SB4y1a75c
- https://www.bilibili.com/video/BV1WB4y1v7ST
- https://www.bilibili.com/video/BV17r4y1u77B
- https://www.bilibili.com/video/BV11S4y1v7S2/
- https://www.bilibili.com/video/BV1hY411T7vy/
- https://www.bilibili.com/video/BV1tY411g7ZT/
- https://www.bilibili.com/video/BV1GB4y1X72R/
- https://www.bilibili.com/video/BV1nB4y1R7Yz/
- https://proceedings.neurips.cc/paper/2019/file/093f65e080a295f8076b1c5722a46aa2-Paper.pdf
- https://www.bilibili.com/video/BV1v34y1E7zu/
- https://www.bilibili.com/video/BV1xB4y1m7Xi/
- https://www.bilibili.com/video/BV11Y411P7ep/
- https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-li_mu.pdf
- https://www.bilibili.com/video/BV1YA4y197G8/
- https://www.bilibili.com/video/BV1fL4y157yA/
- https://www.bilibili.com/video/BV1tY4y1p7hq/
- https://aiindex.stanford.edu/wp-content/uploads/2022/03/2022-AI-Index-Report_Master.pdf
- https://www.bilibili.com/video/BV1s44y1N7eu/
- https://storage.googleapis.com/deepmind-media/AlphaCode/competition_level_code_generation_with_alphacode.pdf
- https://www.bilibili.com/video/BV1ab4y1s7rc/
- https://www.bilibili.com/video/BV1iY41137Zi/
- https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
- https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
- https://www.bilibili.com/video/BV1AF411b7xQ/
- https://proceedings.neurips.cc/paper/2014/file/00ec53c4682d36f5c4359f4ae7bd7ba1-Paper.pdf
- https://www.bilibili.com/video/BV1mq4y1x7RU/
- https://openai.com/blog/clip/
- https://www.bilibili.com/video/BV1SL4y1s7LQ/
- https://perceiving-systems.blog/en/post/novelty-in-science
- https://www.bilibili.com/video/BV1ea41127Bq/
- https://www.nature.com/articles/s41586-021-03819-2.pdf
- https://www.bilibili.com/video/BV1oR4y1K7Xr/
- https://www.bilibili.com/video/BV1oL411c7Us/
- https://www.bilibili.com/video/BV13L4y1475U/
- https://www.nature.com/articles/s41586-021-04086-x.pdf
- https://www.bilibili.com/video/BV1YZ4y1S72j/
- https://www.bilibili.com/video/BV1Eu411U7Te/
- https://www.bilibili.com/video/BV19S4y1M7hm/
- https://www.bilibili.com/video/BV1C3411s7t9/
- https://www.bilibili.com/video/BV1qq4y1z7F2/
- https://www.bilibili.com/video/BV1sq4y1q77t/
- https://www.bilibili.com/video/BV15P4y137jb/
- https://www.bilibili.com/video/BV1PL411M7eQ/
- https://papers.nips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf
- https://www.bilibili.com/video/BV1rb4y187vD/
- https://distill.pub/2021/gnn-intro/
- https://www.bilibili.com/video/BV1iT4y1d7zP/
- https://www.bilibili.com/video/BV1pu411o7BE/
- https://www.bilibili.com/video/BV1P3411y7nn/
- https://www.bilibili.com/video/BV1Fb4y1h73E/
- https://papers.nips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
- https://www.bilibili.com/video/BV1hq4y157t1/
- https://www.bilibili.com/video/BV1ih411J7Kz/
- https://c.d2l.ai/zh-v2/
- https://github.com/mli/paper-reading/discussions
- https://api.semanticscholar.org/api-docs/graph#operation/get_graph_get_paper
- https://cs.stanford.edu/people/karpathy/deepvideo/
- https://distill.pub/2017/momentum/
- https://storage.googleapis.com/deepmind-media/alphago/AlphaGoNaturePaper.pdf
- https://discovery.ucl.ac.uk/id/eprint/10089234/1/343019_3_art_0_py4t4l_convrt.pdf
-
1 [斯坦福 100+ 作者的 200+ 页综述],2 [对 LayerNorm 的新研究],3 [对 Attention 在 Transformer 里面作用的研究] ↩
- 机器学习 -- 大型语言模型简史:从 Transformers (2017) 到 DeepSeek-R1 (2025) | 20 Feb 2025
- 机器学习 -- DALL·E 2 & 扩散模型 | 21 Dec 2024
- 机器学习 -- 学术论文解读系列(进行中) | 04 Oct 2024
- 机器学习 -- 经典论文 ViT (Vision Transformer) | 24 Jul 2024
- 机器学习 -- 跟李沐学 AI【论文精读】(进行中) | 09 Jul 2024
- 机器学习 -- Attention is all you need | 30 Jun 2024
- 机器学习笔记 -- 3Blue1Brown 深度学习 Deep Learning(已完成) | 29 Jun 2024
- 机器学习 -- 李宏毅 2021/2022 春机器学习课程(进行中) | 31 Aug 2023
- 机器学习 -- 实用机器学习 李沐(进行中) | 31 Aug 2023
- 机器学习 -- ChatGPT Prompt 提示词 吴恩达(进行中) | 28 Jul 2023
- 机器学习 -- 浙江大学 · 机器学习(已完成) | 12 Feb 2023
- 机器学习 -- 人工智能学习路线(进行中……) | 10 Feb 2023
- 机器学习 -- 北交 · 图像处理与机器学习(已完成) | 03 Dec 2022
- 机器学习笔记 -- 人工智能 机器学习 算法概览(已完成) | 13 Oct 2022
- 机器学习笔记 -- 神经网络内部发生了什么?深度学习可视化 | 13 Oct 2022
- 机器学习 -- 吴恩达机器学习 Review(已完成) | 31 Aug 2022
- 机器学习 -- 吴恩达深度学习(进行中) | 31 Aug 2022
- 机器学习 -- 吴恩达机器学习(已完成) | 31 Aug 2022
- 机器学习笔记 -- 神经网络和深度学习简史 | 26 Dec 2020
 .
.