机器学习 -- DALL·E 2 & 扩散模型
整理 李沐论文精读系列 —— 由 DALL·E 2 看图像生成模型
DALL·E 2(内含扩散模型介绍)  note
note 
搞 AI 的就是这么卷!!!
DALL·E?Dalí ! 读到论文 DALL·E 2 时,不禁感到一阵触动。AI 的发展就像一门实验科学,理论的进展相对缓慢,更多依赖于无数试验的推动。然而,这样的探索伴随着巨大的资源投入,也让普通人难以触及这场科技变革的核心。
通过映射到高维空间,再投射回来。 通过 bottleneck 强制模型去学习规律, 为了投射回来的图片更符合真实,对高维空间施加一定约束,比如 VAE 的高斯分布,VQ-VAE 的 codebook。 为了生成的图片更有意义,还可以用文本或者 CLIP 对模型进行引导。 最后是大力出奇迹,only scale matters。其它的东西,比如模型的种类和训练的技巧,都只是锦上添花罢了。

生成模型概览
AE
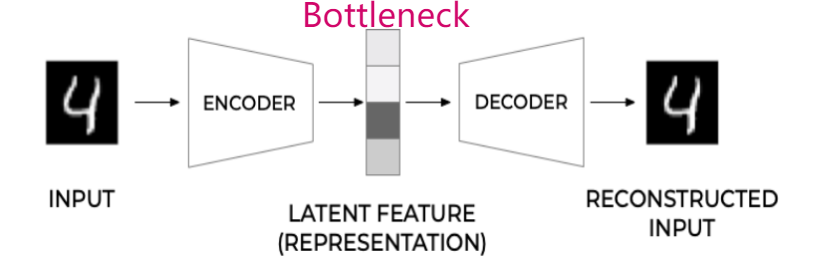
AE(auto-encoder)是很早之前的技术了,思路也非常简单:用一个编码器(Encoder)把输入编码为 latent vector;然后用 Decoder 将其解码为重建图像,希望重建后的图像与输入图像越接近越好。通常 latent vector 的维度比输入、输出的维度小,因此称之为 bottleneck。AE 是一个自重建的过程,所以叫做“自-编码器”。
DAE
DAE(Denoising autoencoder)将原始输入图像进行一定程度的打乱,得到 corrupted input。然后把后者输入 AE,目标仍然是希望重建后的图像与原始输入越接近越好。DAE 的效果很不错,原因之一就是图像的冗余度太高了,即使添加了噪声,模型依然能抓取它的特征。而这种方式增强了模型的鲁棒性,防止过拟合。
VAE
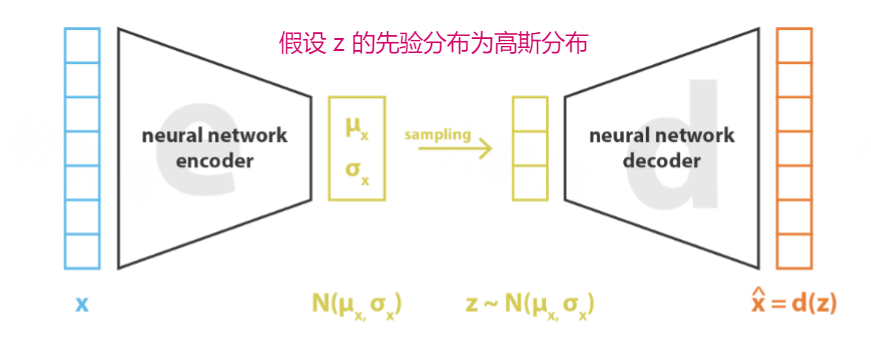
VAE(Variational autoencoder)仍然由一个编码器和一个解码器构成,并且目标仍然是重建原始输入。 但中间不再是学习 latent vector $z$,而是学习它的后验分布 $p(z|x)$,并假设它遵循多维高斯分布。 具体来说,编码器得到两个输出,并分别作为高斯分布的均值和协方差矩阵的对角元(假设协方差矩阵是对角矩阵)。 然后在这个高斯分布中采样,送入解码器。实际工程实现中,会用到重参数化(reparameterization)的技巧。
VAE 提高了生成结果的多样性。对于同一个输入,由于 latent vector 不再是固定的,而是采样得到,我们可以得到不同的但类似的任意多个输出。并且 VAE 在数学上也很干净优美,在贝叶斯框架里用到了变分法。
VQ-VAE
VAE 具有一个最大的问题就是使用了固定的先验(高斯分布),其次是使用了连续的中间表征,导致模型的可控性差。 为了解决这个问题,VQ-VAE(Vector Quantized Variational Autoencoder)选择使用 离散的中间表征 ,同时,通常会使用一个自回归模型来学习先验(例如 PixelCNN),在训练完成后,用来采样得到 $z_e$。
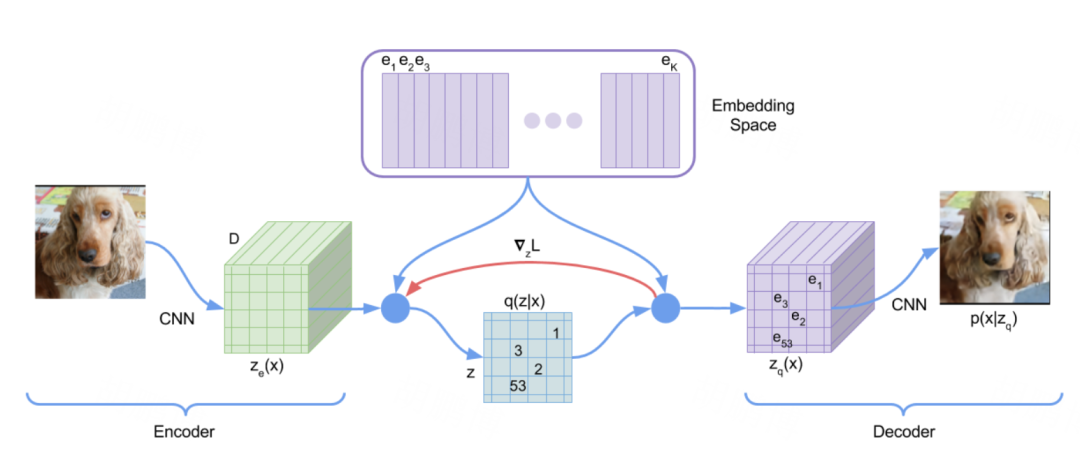
图片首先经过 encoder,得到 $z_e$ ,它是 $H \times W$ 个 $D$ 维向量。$e_1, e_2, …, e_K$ 是 $K$ 个 $D$ 维向量,称为 codebook。对于 $z_e$ 中每个 $D$ 维向量,都在 codebook 中找到最接近的 $e_i$ ,构成 $z_q$ ,这就是 decoder 的输入。一般 $k=8192$,$D=512 \ \ or \ \ 768$。 从 $z_e(x)$ 到 $z_q(x)$ 这个变化可以看成一个聚类,$e_1, e_2, …, e_K$ 可以看作 $K$ 个聚类中心。这样把 encoder 得到的 embedding 离散化了,只由聚类中心表示。
VAE 的目的是训练完成后,丢掉 encoder,在 prior 上直接采样,加上 decoder 就能生成。如果我们现在独立地采 $H \times W$ 个 $z$ ,然后查表得到维度为 $H \times W \times D$ 的 $z_q(x)$ ,那么生成的图片在空间上的每块区域之间几乎就是独立的。因此我们需要让各个 $z$ 之间有关系。用 PixelCNN,对这些 $z$ 建立一个自回归模型: $p(z_1,z_2,z_3,…) = p(z_1) p(z_2|z_1) p(z_3|z_1,z_2) …$ 这样就可以进行 ancestral sampling,得到一个互相之间有关联的 $H \times W$ 的整数矩阵。$p(z_1,z_2,z_3,…)$ 这个联合概率即为我们想要的 prior。 —— Elijha:VQ-VAE 解读
初代的 DALL·E 模型就是基于 VQ-VAE 的架构实现的。相当于做了简化,把高斯分布变成了固定的特征图。
GAN
整体结构而言,GAN(Generative Adversarial Networks)由生成器和判别器构成。生成器负责生成一张图片,而判别器则负责判断这张图片是真实样本还是生成的假样本。通过逐步的迭代,左右互博,最终生成器可以生成越来越逼真的图像,而判别器则可以更加精准的判断图片的真假。
GAN 的训练涉及到两个网络之间的平衡,很容易训练坍塌。而且,GAN 的目标函数是为了保真度而设计的,所以图片生成的多样性不好。另外,GAN 的生成过程是隐式的,我们并不知道 GAN 生成时遵循何种分布。
但这并不妨碍 GAN 成为过去几年生成模型的主潮流。人们基于最初版本的 GAN 发展出了许许多多的变种,如 Conditional GAN、 DCGAN (Deep Convolutional Generative Adversarial Networks) (作者就是 GPT-1,GPT-2 的一作)等等。还有借鉴 VQ-VAE 思路而诞生的 VQGAN 以及 VQGAN-CLIP 。
VQGAN
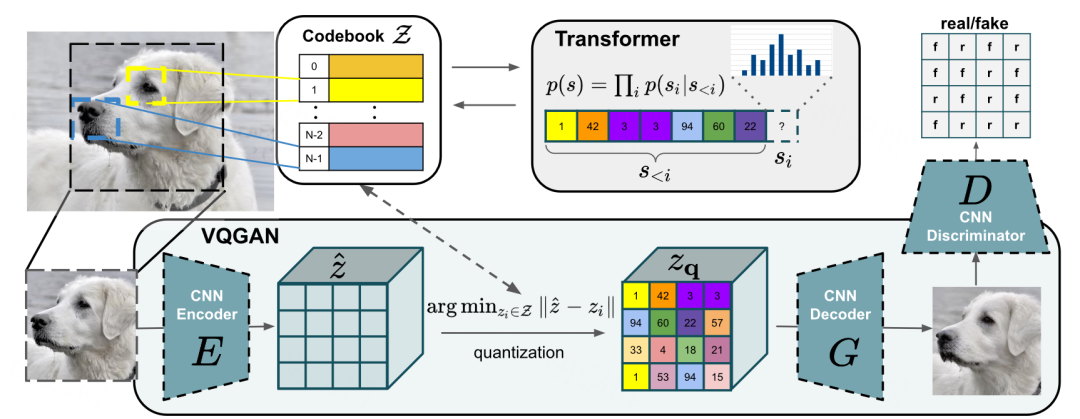
VQGAN 的生成器部分,也借助了 codebook 将中间表征向量离散化。然后把生成的结果送入判别器。与传统 GAN 不同的是, 这里的判别器不是对每张图片进行判断,而是对图片的每一个小块进行判断。 (上图中,在狗狗的图片的 16 个小块上进行了判断)。
VQGAN-CLIP
VQGAN-CLIP 通过文本描述信息引导 VQGAN 模型,使其最终生成与文本描述非常相似的图片。
简单来说,它是 VQGAN 与 CLIP 的结合。通过 CLIP 模型,对比生成的图像与指定文本的相似度,来调节中间表征向量,从而使得 VQGAN 模块生成与文本描述一致的图片。
扩散模型
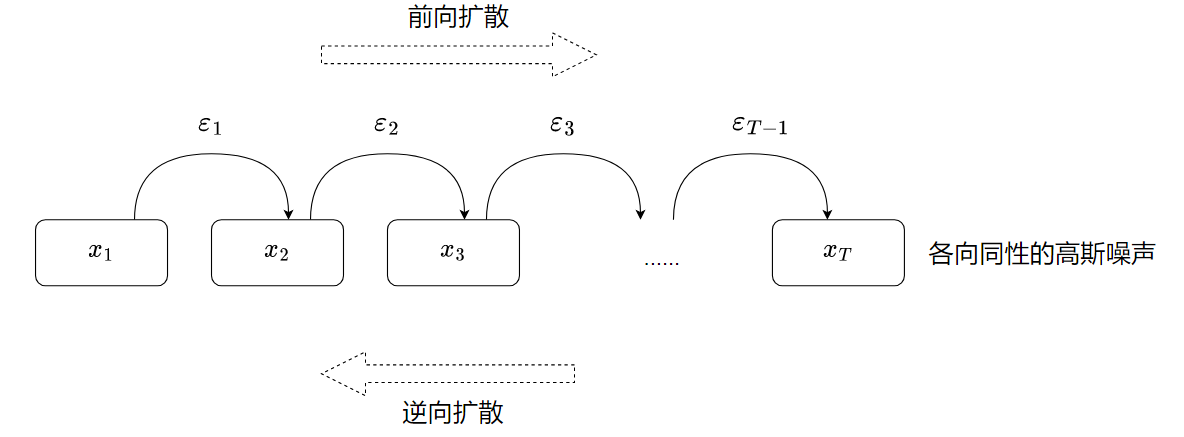
扩散模型(diffusion model)主要有两个过程组成, 前向扩散过程,反向去噪过程, 前向扩散过程主要是将一张图片变成随机噪音(标准高斯分布),而逆向去噪过程则是将一张随机噪音的图片还原为一张完整的图片。
为什么叫“扩散”模型呢?扩散这个名词来自于热力学,某个区域物质密度很高,那么它就会向低密度的区域扩散,最终达到平衡;就好比香水的味道会扩散到整个房间。这里的平衡指的是标准高斯分布的噪声。图片由原来的有序,逐渐变为无序的噪声,可以认为是“有序度”的扩散。
前向扩散过程就是 在原始图像上,随机添加高斯噪声。 通过 T 步迭代,最终将原始图片的分布变成标准高斯分布。这个过程中没有需要学习的参数,高斯噪声的参数都是定义好的。
逆向过程就是还原的过程,也就是 从高斯噪声中恢复原始分布的过程。
前向扩散可以理解成多步编码过程,得到“中间向量” $x_T$;逆向扩散是一个多步解码的过程,目的是重新构建原始输入。
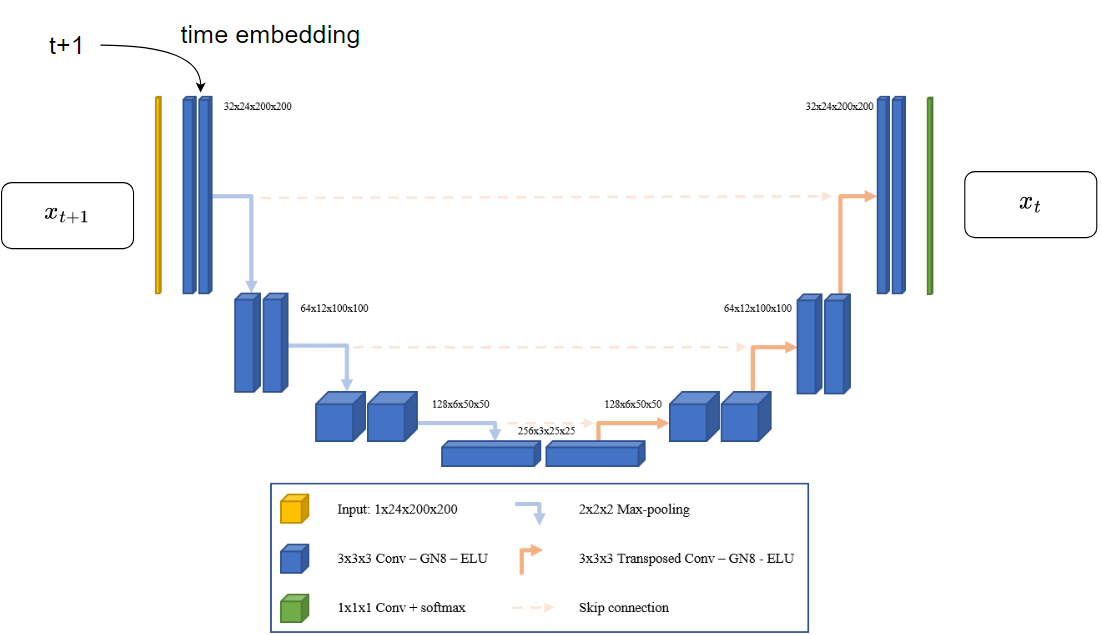
所以关键在于如何构建逆向扩散,即如何通过 $x_{t+1}$ 求出 $x_t$ 。由于每个时间步的图像大小都是一样的,所以可以采用 U-net 结构 —— 先 downsampling,再 upsampling,使得输出与输入的尺寸一致。
逆向扩散不同时间步使用同一个 U-net 模型,参数共享,类似于 RNN 结构。所以还需要给模型提供一个具有时间信息的输入 —— time embedding,类似于 Transformer 里的 positional embedding。
DDPM
以上是原初版本的扩散模型,它早在 2015 年甚至更早就被提出了。但由于前向和逆向扩散需要的时间步很多,训练和推理都需要很长的时间,所以扩散模型一直被 GAN 压着打,直到 2020 年 Denoising Diffusion Probabilistic Models(DDPM)的出现。DDPM 主要有两个贡献:
一、它说不需要推测 $x_t$ ,只需要推测 $\epsilon_t$ 就可以了。这样大大降低了推理的难度。此时的损失函数表示为: $l(x_{t-1}|x_t) = || \epsilon_{t-1} -f_{\theta}(x_t, t) ||$ 这里的 $f$ 就是 U-net。
二、由于每步都是高斯噪声,只需要预测它的均值和方差即可。并且作者提出,固定方差,仅仅预测噪声的均值就可以达到很好的效果。
Diffusion Models Beat GANs
DDPM 的成功引起了大家的兴趣。2020 年底, improved DDPM 就出炉了。它在 DDPM 的基础上,不仅仅预测均值,而且预测方差;并且在更大模型上尝试了 DDPM,发现大模型会带来很大的效果提升。于是紧接着有一篇 Diffusion Models Beat GANs,进一步把模型做大、做复杂,取得了很好的效果;并且,作者在这篇论文里使用了 classifier guidance 的方法,引导模型做采样和生成。这不仅让生成的图像更逼真,而且加速了反向采样的速度,只需要 25 次采样就能从噪声还原出高质量的图片。
简单来说,classifier guided diffusion 使用一个额外训练好的图像分类器,每次判别 $x_t$ 的类别,得到交叉熵损失函数,进一步可以得到梯度,用这个梯度去引导 $f_{\theta}$ 做预测。这里的梯度大概暗含了当前生成的图像有没有某个物体,以及生成的物体真不真实。通过引导,扩散模型的逼真度提升了很多,击败了一些 GAN 模型。
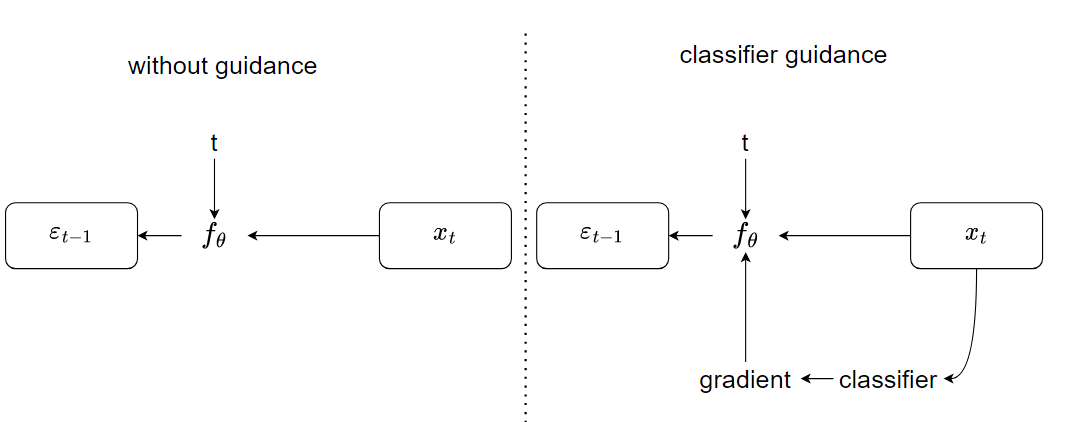
这和 conditional GAN 的思路差不多,提供更多的 condition,也就是引导,辅助它完成任务。
这里的引导不一定非得是一个分类器,可以是文本,也可以是 CLIP 模型。
Classifier free guidance
OpenAI 后续的 GLIDE 模型和 DALL·E 2 ,以及谷歌的 Imagen ,在推理过程中不再依赖额外训练的分类器,而是采用 classifier-free guidance。
具体来说,每一个逆向扩散时间步会产生两个输出:一个是提供引导(比如可以是 CLIP 模型)时候的输出;一个是无引导时候的输出。然后做差:$f_{\theta}(x_t, t,y) - f_{\theta}(x_t, t, vide)$ ,此处的 $y$ 表示 condition。这样就得到了一个方向,告诉网络如何从无引导的输出到达有引导的输出。这样,在推理的时候,就可以抛开引导,直接用训练过程中得到的差值。
Classifier free guidance 这种训练方法的成本很高。本来扩散模型的训练成本就不低,这里还在每个时间步生成两个输出,成本无疑更高。但这没有妨碍它深受青睐。
在使用了很多技巧之后,基于扩散模型的 GLIDE 用了 3.5 亿参数,效果就直逼基于 VQ-VAE 的、用了 12 亿参数的 DALL·E 模型。OpenAI 看到扩散模型确实靠谱,所以顺着 GLIDE 的思路,孕育出了现在的 DALL·E 2。
DALL·E 2
DALL·E 2 的整体架构说起来非常简单,它用了两阶段的生成 —— 第一阶段用 prior 模型从文本生成图像特征;第二阶段用 decoder 生成图像。
CLIP 只有两个编码器,没法从特征回到图像。 OOD:OOD(Out-of-Distribution) 。 分布外数据(Out-of-Distribution, OOD) 指的是在模型训练时未见过的、与训练数据分布存在显著差异的数据。
作者说,prior 模型有两种选择:自回归模型和扩散模型。我们这里着重说一下扩散模型。这里是用 sequence (text feature) 预测 sequence (image feature),没有要求前后尺寸不变。作者这里没有用 U-net,而是用了 Transformer —— 将 CLIP 的文本编码、加入噪声的 CLIP 的图像编码、扩散时间步的 time embedding 等输入,去预测未加噪声的 CLIP 图像编码。
注:CLIP 是一个 zero-shot 的视觉分类模型,详见 跟李沐读论文系列 —— CLIP。
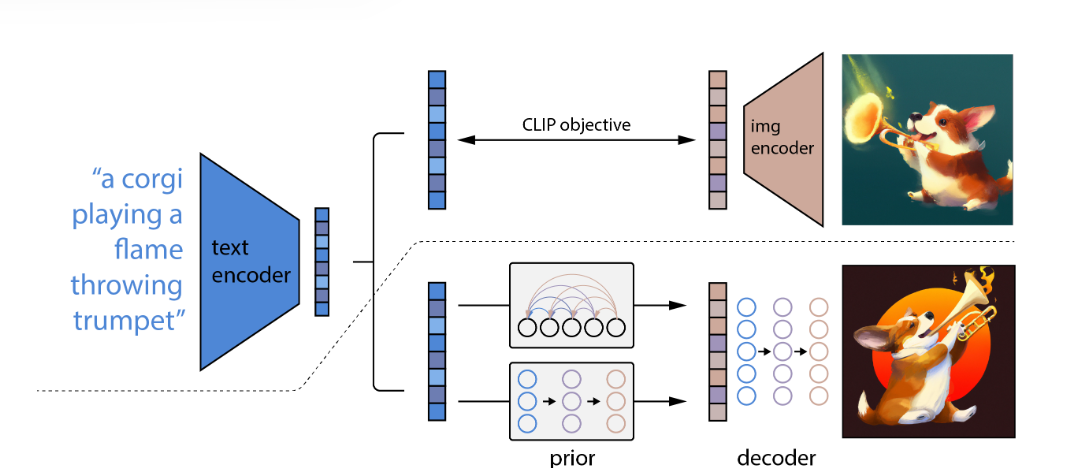
DALL·E 2 论文里还有非常多的技术细节。如果不研读源码,很难对这个模型进行宏观上的把握。谷歌的 Imagen 模型没有用两阶段的生成,直接用了一个 U-net 搞定,更简单,效果也好。另外谷歌 2022 年 6 月份最新的 Pathways Autoregressive Text-to-Image Model(Parti)模型,用 200 亿参数的 Pathways 模型做自回归的图像生成,效果直接超越了 DALL·E 2 和 Imagen。
朱神总结说,现在看来,无非是大力出奇迹, only scale matters 。其它的东西,比如模型的种类和训练的技巧,都只是锦上添花罢了。
另外一个比较有意思的讨论 —— 利用 DALL·E 2 这类文生图模型进行数据增强。给定文本,用 DALL·E 2 生成图片,这样就轻松得到了高质量的文本-图片对。然后用这些数据去训练 CLIP 这些模型,反过来增强 DALL·E 2 的效果。 这种“左脚踩右脚上天”的思路可不可行呢?我个人认为,虽然听起来很有意思,但大规模做数据增强行不通。这相当于模型固步自封,只学到了他懂的东西,没有接触到新东西。
局限性
首先一个局限性就是在社会影响方面,DALL·E 2 生成的图像几乎可以以假乱真,可能会被人拿去生成一些政治性、歧视性比较强的图像,而人们无法分辨真伪。
朱神提到,Twitter 上有个帖子,讨论说 DALL·E 2 其实有自己的一套语言,用这套我们无法理解的语言来生成对应的图片。Giannis Daras 把他们的发现,整理成了一篇论文,放到了 arXiv 上:Discovering the Hidden Vocabulary of DALLE-2。

比如上图的例子。输入“Two whales talking about food, with subtitles.”DALL·E 2 生成的图像里虽然有两只鲸鱼,但是说的语言令人摸不着头脑。但如果把这串文字重新喂给 DALL·E 2,得到的是海鲜的图片。就好像鲸鱼在以另一种语言讨论着它们的食物。
DALLE 的鸟语其实是自然语言的错误映射,如果在数据集里面压根就没有危险词汇的话应该映射不到。
Stable Diffusion
Stable Diffusion 是 Stability AI 与 CompVis/LMU、Runway、LAION 等合作者在 2022 年 8 月公开发布的文本生成图像开源模型,建立在隐扩散模型(Latent diffusion)的工作之上。普通的扩散模型在原始像素空间中进行,这对于高分辨率的图片来说计算量很大。隐扩散模型是在维度更低的隐空间中应用扩散过程。
隐扩散模型生成的是图片的隐空间向量表示。除了扩散模型,Stable Diffusion 还需要一个 autoencoder,将图片压缩至隐空间(encoder)并从隐空间向量中还原图片(decoder)。这一步选用的是 VAE 。
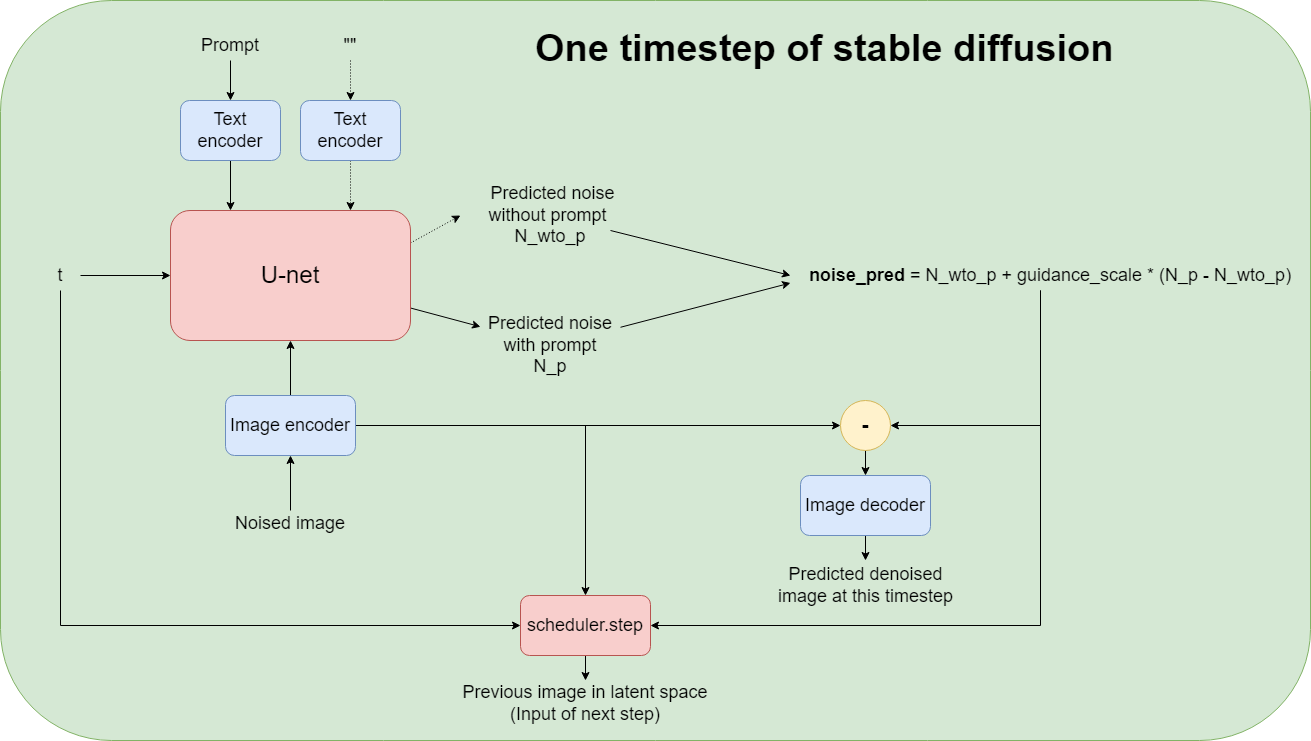
对于提示文本 Prompt,Stable Diffusion 用 Transformer blocks 获取 embeddings。为了让 text embeddings 与 image embeddings 有一个较好的对齐效果, text encoder in CLIP 是一个不错的选择。
在低维度的隐空间中,Stable Diffusion 用 U-net 预测噪声。
因此 Stable Diffusion 的三个主要部分:VAE、CLIP text encoder、U-net。
- VAE 其作用是将图像转换为低维表示形式,从而使得扩散过程是在这个低维表征中进行的,扩散完成之后,在通过 VAE 解码器,将其解码成图片。
- U-Net 网络 U-Net 是扩散模型的主干网络,其作用是对噪音进行预测,从而实现反向去噪过程。
- 文本编码器 CLIP 主要负责将文本转换为 U-Net 可以理解的表征形式,从而引导 U-Net 进行扩散。
Stable Diffusion 采用了 Classifier free guidance ,分别在有文本提示、没有文本提示时预测噪声,把有文本提示时的预测当作引导。
Fast.ai 有一门关于 Stable Diffusion 的课程。基于 Hugging Face 的 diffusers 库,调用预训练好的 Stable Diffusion 模型,借助源码,了解 负提示(Negative prompts)、图生图(Image to Image)、Textual inversion、Dreambooth 等方法和概念。
一点思考
如果只看生成结果,我们会惊叹于 Midjourney 生成图像的逼真与创造性,会讶异于 chatGPT 的应答如流,似乎它就要通过图灵测试了。在我看来,AI 还有很长的路要走。首先是可解释性。“知其然,不知其所以然”是深度学习的最大痛点。其次是高昂的训练成本,大模型需要大数据,一个模型的训练成本能达到几千万美元。另外,真正的智能需要具备持续的学习能力,但现在的模型还不行,像是 chatGPT 并不知晓 2022 年发生的新闻。
问题是有,同时也要看到 AI 技术的迭代速度之快。2012 年 Alexnet 的提出引领了计算机视觉的潮流;到 2017 年,Transformer 的发表让 NLP 获得了极大的发展,并促进了(多模态)图像、文本领域的交融发展;2022 年,一系列大规模的生成模型震撼着大众。深度学习已经完成了两个五年计划,不知道下一个五年计划里我们会有怎样的惊喜呢?
说到这里,在满怀期待的同时,我也有一丝隐忧。现在深度学习逐渐趋向于“靠算力取胜”。很多时候不是方法不行,而是算力不够。谷歌和 OpenAI 之所以能够引领潮流,大家想想是为什么呢?且不论“算力霸权”,就单说“算力取胜”这条路能走多远,恐怕还是要看基础物理的脸色。如果能取得突破性的进展,大幅提升硬件性能和计算能力,相信那个时候的 AI 才会真正令人感到可怕。
参考资料快照
- 机器学习 -- 大型语言模型简史:从 Transformers (2017) 到 DeepSeek-R1 (2025) | 20 Feb 2025
- 机器学习 -- DALL·E 2 & 扩散模型 | 21 Dec 2024
- 机器学习 -- 学术论文解读系列(进行中) | 04 Oct 2024
- 机器学习 -- 经典论文 ViT (Vision Transformer) | 24 Jul 2024
- 机器学习 -- 跟李沐学 AI【论文精读】(进行中) | 09 Jul 2024
- 机器学习 -- Attention is all you need | 30 Jun 2024
- 机器学习笔记 -- 3Blue1Brown 深度学习 Deep Learning(已完成) | 29 Jun 2024
- 机器学习 -- 李宏毅 2021/2022 春机器学习课程(进行中) | 31 Aug 2023
- 机器学习 -- 实用机器学习 李沐(进行中) | 31 Aug 2023
- 机器学习 -- ChatGPT Prompt 提示词 吴恩达(进行中) | 28 Jul 2023
- 机器学习 -- 浙江大学 · 机器学习(已完成) | 12 Feb 2023
- 机器学习 -- 人工智能学习路线(进行中……) | 10 Feb 2023
- 机器学习 -- 北交 · 图像处理与机器学习(已完成) | 03 Dec 2022
- 机器学习笔记 -- 人工智能 机器学习 算法概览(已完成) | 13 Oct 2022
- 机器学习笔记 -- 神经网络内部发生了什么?深度学习可视化 | 13 Oct 2022
- 机器学习 -- 吴恩达机器学习 Review(已完成) | 31 Aug 2022
- 机器学习 -- 吴恩达深度学习(进行中) | 31 Aug 2022
- 机器学习 -- 吴恩达机器学习(已完成) | 31 Aug 2022
- 机器学习笔记 -- 神经网络和深度学习简史 | 26 Dec 2020
 .
.