机器学习笔记 -- 3Blue1Brown 深度学习 Deep Learning(已完成)
深度学习 Deep Learning https://space.bilibili.com/88461692/channel/seriesdetail?sid=1528929 https://www.3blue1brown.com/topics/neural-networks
深度学习之神经网络的结构 Part 1 ver 2.0
https://www.bilibili.com/video/BV1bx411M7Zx/
But what is a Neural Network? An overview of what a neural network is, introduced in the context of recognizing hand-written digits. Chapter 1 2017 年 10 月 5 日
深度学习之梯度下降法 Part 2 ver 0.9 beta
https://www.bilibili.com/video/BV1Ux411j7ri/
Gradient descent, how neural networks learn An overview of gradient descent in the context of neural networks. This is a method used widely throughout machine learning for optimizing how a computer performs on certain tasks. Chapter 2 2017 年 10 月 16 日
Analyzing our neural network Chapter 3 2017 年 10 月 16 日
深度学习之反向传播算法 上 / 下 Part 3 ver 0.9 beta
https://www.bilibili.com/video/BV16x411V7Qg/
What is backpropagation really doing? An overview of backpropagation, the algorithm behind how neural networks learn. Chapter 4 2017 年 11 月 3 日
Backpropagation calculus The math of backpropagation, the algorithm by which neural networks learn. Chapter 5 2017 年 11 月 3 日

GPT 是什么?直观解释 Transformer | 深度学习第 5 章
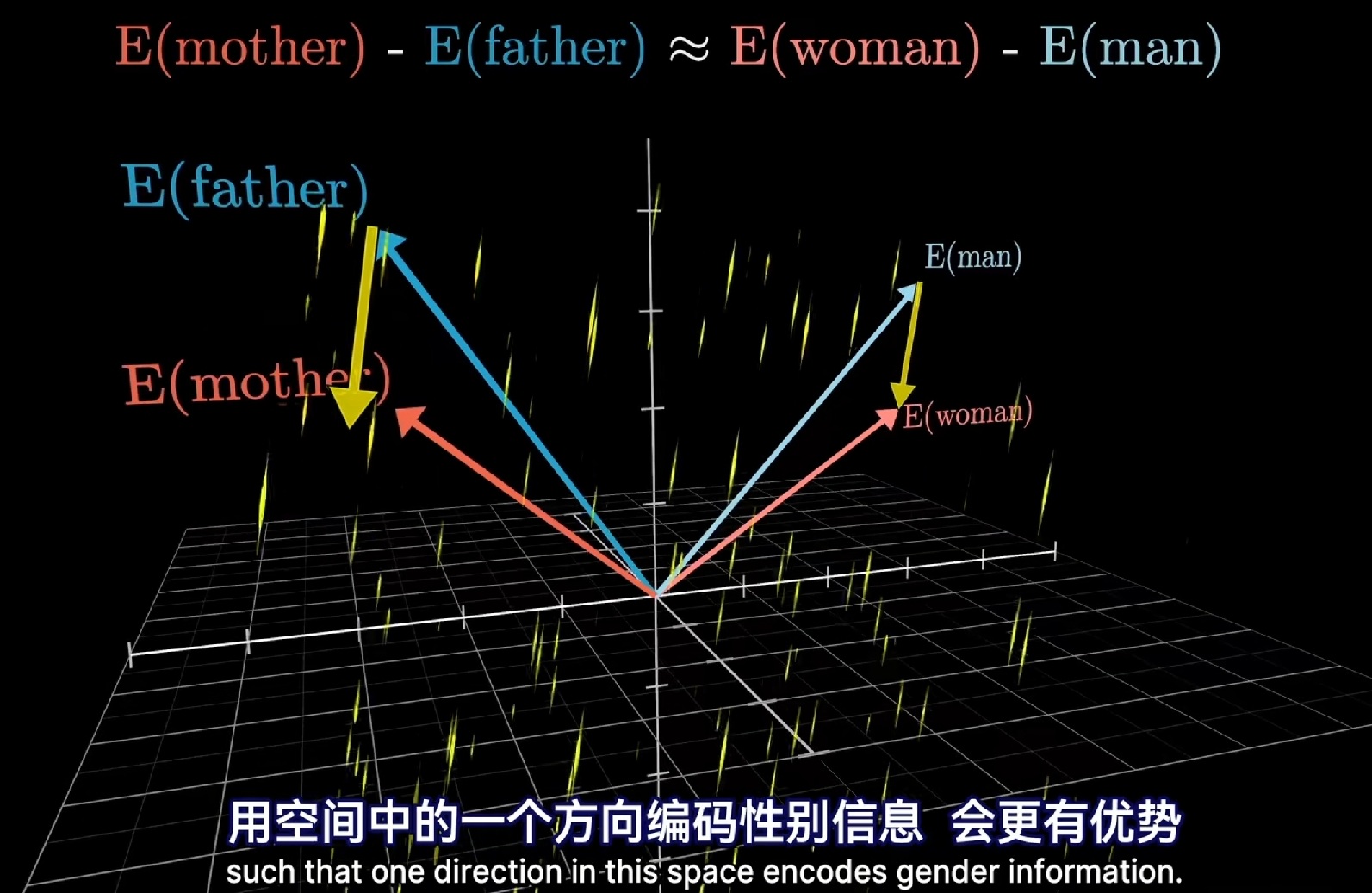
皇帝 - 男人 + 女人 ≈ 皇后 https://www.bilibili.com/video/BV13z421U7cs/
- Embedding
- Key
- Query
- Value
- Output
- Up-projection
- Down-projection
- Unembedding
GPT 的第一层:词嵌入为向量(embedding) 初始词嵌入本身主要代表 token;经过 Transformer 各层之后,隐藏状态才会逐步融合上下文信息 GPT 的最后一层:向量解码为词(Unembedding) 带温度的 Softmax 函数
But what is a GPT? Visual intro to Transformers | Deep learning, chapter 5 A visual introduction to transformers. This chapter focusses on the overall structure, and word embeddings 2024 年 4 月 1 日
直观解释注意力机制,Transformer 的核心 | 深度学习第 6 章
https://www.bilibili.com/video/BV1TZ421j7Ke/
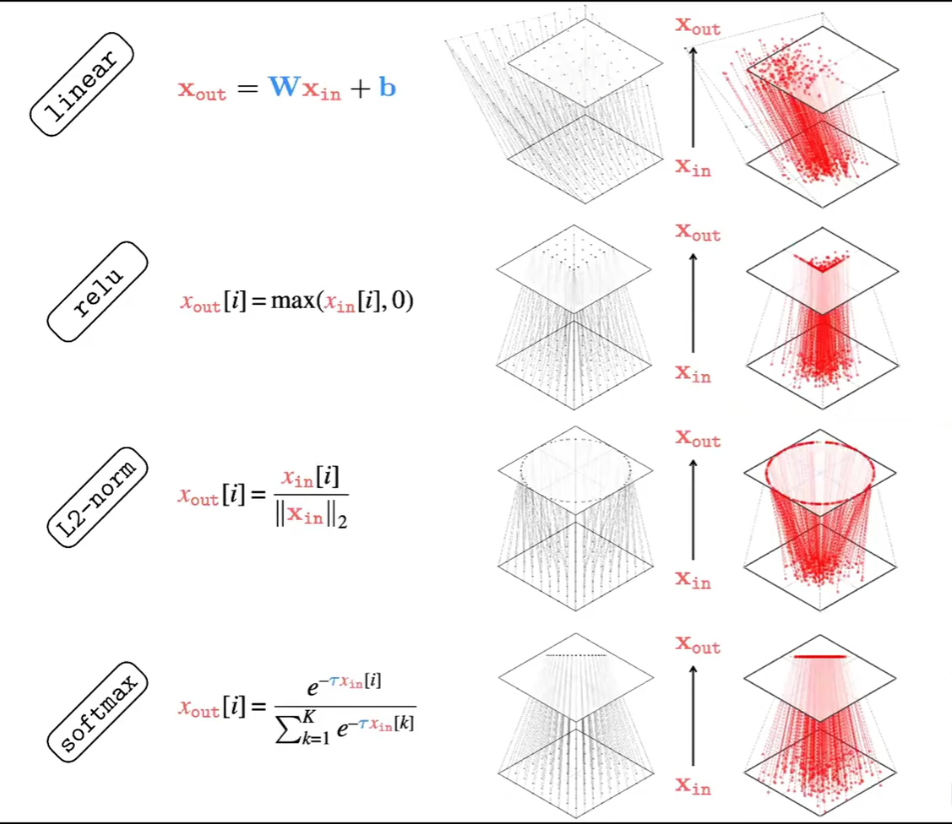
朴素的理解两个词的注意力可能会理解为计算是两个词嵌入的直接的相似度, 但是其实是计算两个词分别在 QK 空间上的投影的相似度,因为如果不这么做,那么两个一样的词永远最相似。
因此 QK 两个矩阵其实表征了两个空间。即:查询空间 Q 和被查空间 K, Q 用来映射每一个词 x 的方向,K 用来映射其他每个词的方向,一旦两个空间的映射结果一致则表示两个词匹配。
想真正弄清楚 Transformer 内部的大网络在做什么,推荐 Anthropic 的网页博文: https://transformer-circuits.pub/2021/framework/index.html 我就是读了他的一篇文章后开始想,输出矩阵乘以值矩阵,其实就是嵌入空间到自身的一个低秩映射。 这样想之后,至少我的概念变得更清晰了。
Visualizing Attention, a Transformer's Heart | Chapter 6, Deep Learning Demystifying attention, the key mechanism inside transformers and LLMs. 2024 年 4 月 7 日 © 2024 Grant Sanderson
何恺明 MIT 第一课 - 卷积神经网络
https://www.bilibili.com/video/BV1sW421c7SK/

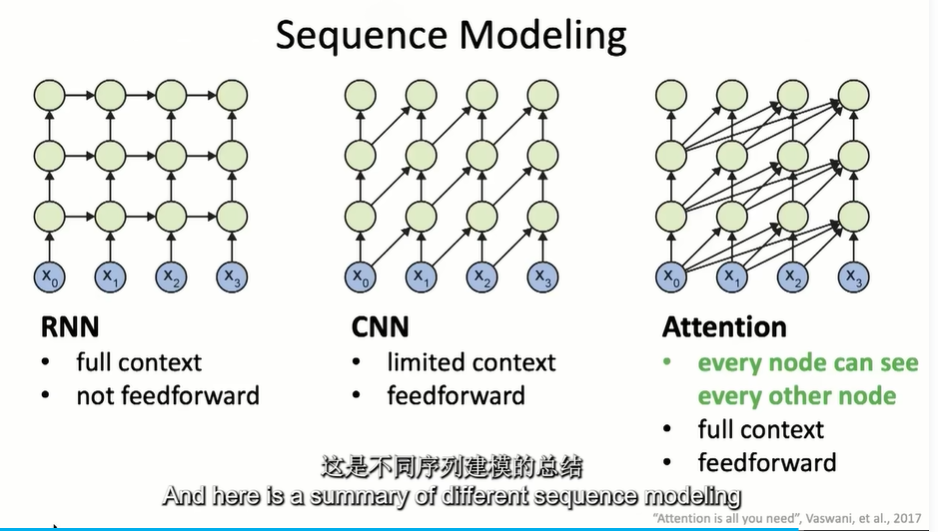
every node can see every other node
2017 Transformer 提出,到 2020 年 ViT(Vision Transformer)把 Transformer 引入通用视觉骨干,是一次很明显的范式切换;后续更多是在架构、训练范式和生成模型上继续演进。
- GPT
- AlphaFold
- ViT
Towards End-to-End Generative Modeling(走向端到端生成建模)
Flow Matching
参考资料快照
- https://space.bilibili.com/88461692/channel/seriesdetail?sid=1528929
- https://www.3blue1brown.com/topics/neural-networks
- https://www.bilibili.com/video/BV1bx411M7Zx/
- https://www.bilibili.com/video/BV1Ux411j7ri/
- https://www.bilibili.com/video/BV16x411V7Qg/
- https://www.bilibili.com/video/BV13z421U7cs/
- https://www.bilibili.com/video/BV1TZ421j7Ke/
- https://transformer-circuits.pub/2021/framework/index.html
- https://www.bilibili.com/video/BV1sW421c7SK/
- 机器学习 -- 大型语言模型简史:从 Transformers (2017) 到 DeepSeek-R1 (2025) | 20 Feb 2025
- 机器学习 -- DALL·E 2 & 扩散模型 | 21 Dec 2024
- 机器学习 -- 学术论文解读系列(进行中) | 04 Oct 2024
- 机器学习 -- 经典论文 ViT (Vision Transformer) | 24 Jul 2024
- 机器学习 -- 跟李沐学 AI【论文精读】(进行中) | 09 Jul 2024
- 机器学习 -- Attention is all you need | 30 Jun 2024
- 机器学习笔记 -- 3Blue1Brown 深度学习 Deep Learning(已完成) | 29 Jun 2024
- 机器学习 -- 李宏毅 2021/2022 春机器学习课程(进行中) | 31 Aug 2023
- 机器学习 -- 实用机器学习 李沐(进行中) | 31 Aug 2023
- 机器学习 -- ChatGPT Prompt 提示词 吴恩达(进行中) | 28 Jul 2023
- 机器学习 -- 浙江大学 · 机器学习(已完成) | 12 Feb 2023
- 机器学习 -- 人工智能学习路线(进行中……) | 10 Feb 2023
- 机器学习 -- 北交 · 图像处理与机器学习(已完成) | 03 Dec 2022
- 机器学习笔记 -- 人工智能 机器学习 算法概览(已完成) | 13 Oct 2022
- 机器学习笔记 -- 神经网络内部发生了什么?深度学习可视化 | 13 Oct 2022
- 机器学习 -- 吴恩达机器学习 Review(已完成) | 31 Aug 2022
- 机器学习 -- 吴恩达深度学习(进行中) | 31 Aug 2022
- 机器学习 -- 吴恩达机器学习(已完成) | 31 Aug 2022
- 机器学习笔记 -- 神经网络和深度学习简史 | 26 Dec 2020
 .
.