机器学习 -- 浙江大学 · 机器学习(已完成)
路虽远行则将至。
浙江大学 · 机器学习 

惊叹深度网络的每次改进都如此精妙,也不知道为啥,反正收敛靠运气,试验效果更好,太神奇了。 每次看到 ReLU,都想起这玩意,简单的函数可以折叠出任意复杂的高维。 感觉自编码器最大的作用是保证信息不丢失,初始值在最优值附近。 网络的历史发展,每一个网络在 前面的网络 基础上 改进了啥,解决了什么问题。 每次 改动能感受到里面的 精妙,一次次打入黑暗的光亮,推动着深度学习的发展。

Stefano Bachis·F-117A
深度学习与炼丹。 经典网络 AlexNet 第一层的卷积内核是 11x11 像素。 为什么是 11 不是 10,不是 12?不知道,作者写论文的时候也没讲。 AlexNet 为什么有 8 个可学习层,为什么第二层就变成 5x5,后面又变成 3x3 了? 作者也没说。甚至,为什么这个内核的大小越来越小也没有交代。 深度学习像一剂成分复杂、原理不明的药。
严伯钧 神经网络处理架构 Transformer,适合处理自然语言 NLP。 卷积架构 适合图像处理,RNN 架构适合语言处理。
实践中,根据经验多试几个网络,哪个效果更好就用那个。
https://github.com/microsoft/ai-edu https://microsoft.github.io/ai-edu/%E5%9F%BA%E7%A1%80%E6%95%99%E7%A8%8B/index.html
P1 [1.1.1] – 机器学习定义 09:38
P2 [1.2.1] – 机器学习的分类 10:52
非监督学习算法:
- 聚类 Clustering
- EM 算法(Expectation-Maximization algorithm)
- 第一步是计算期望(E),利用对隐藏变量的现有估计值,计算其极大似然估计值;
- 第二步是最大化(M),最大化在 E 步上求得的最大似然值来计算参数的值。M 步上找到的参数估计值被用于下一个 E 步计算中,这个过程不断交替进行。
- 主成分分析(Principle Component Analysis)
监督学习:
- 分类:标签是离散的值
- 回归:标签是连续的值
P3 [1.3.1] – 机器学习算法的过程 12:39
完成。
P4 [1.4.1] – 没有免费午餐定理 09:37
P5 [1.5.1] – 总结 05:36
P6 [2.1.1] – 支持向量机(线性可分定义) 09:49
P7 [2.2.1] – 支持向量机(问题描述) 08:07
P8 [2.3.1] – 支持向量机(优化问题) 13:33
P9 [2.4.1] – 支持向量机(线性不可分情况) 09:32
P10 [2.5.1] – 支持向量机(低维到高维的映射) 07:25
完成。
P11 [2.6.1] – 支持向量机(核函数的定义) 09:46
P12 [2.7.1] – 支持向量机(原问题和对偶问题) 08:12
KKT 条件。
P13 [2.8.1] – 支持向量机(转化为对偶问题) 08:38
跳过。
P14 [2.9.1] – 支持向量机(算法流程) 08:26
P15 [2.10.1] – 支持向量机(兵王问题描述) 08:00
P16 [2.11.1] – 支持向量机(兵王问题程序设计) 08:39
\[\begin{aligned} & \text { - Linear ( 线性内核 ) : } K(x, y)=x^T y \\ & \text { - Ploy ( 多项式核 ) : } \quad K(x, y)=\left(x^T y+1\right)^d \\ & \text { - Rbf ( 高斯径向基函数核 ) : } \quad K(x, y)=e^{-\frac{\|x-y\|^2}{\sigma^2}} \\ & \text { - Tanh ( sigmoid 核 ) : } \\ & \qquad K(x, y)=\tanh \left(\beta x^T y+b\right) \quad \tanh (x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} \end{aligned}\]P17 [2.12.1] – 支持向量机(兵王问题 MATLAB 程序) 16:26
交叉验证。 五折交叉验证 挑选出最好的 超参数。C & Gamma。 最后再用所有数据训练一次。
P18 [2.13.1] – 支持向量机(识别系统的性能度量) 15:30
混淆矩阵。 ROC 曲线。
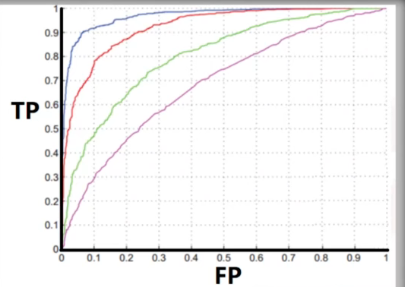
通过 ROC 曲线获得系统性能度量。(AUC & EER)
P19 [2.14.1] – 支持向量机(多类情况) 09:37
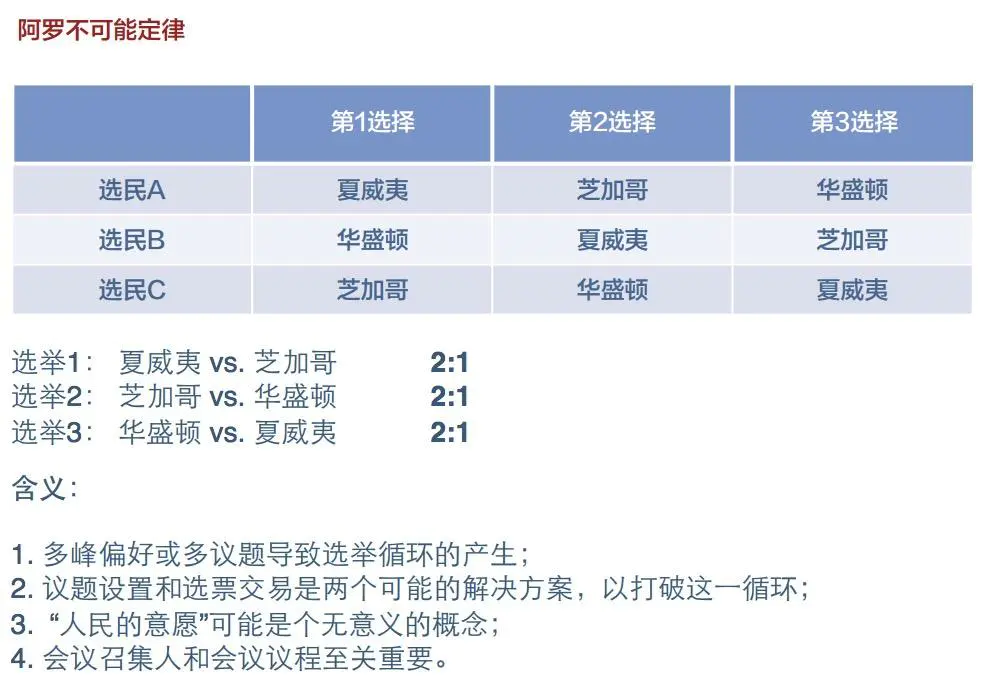
政治选举的经济学分析当中,非常重要的中位数投票原理,就是说,你要获得最大多数的支持,你就要去迎合那些中位数者的偏好。
阿罗不可能定律 在人们有多种不同选择的情况下,选举不一定能够反映出大多数人的意愿。选举会出现议而不决、循环不已的情况,而要阻止这种情况,要么是由议程决定人决定会议的程序,要么把选票改成钞票。
P20 [3.1.1] – 人工神经网络(神经元的数学模型) 10:13
单个神经元是一阶泰勒近似。
note ![]()
P21 [3.2.1] – 人工神经网络(感知器算法) 18:50
P22 [3.3.1] – 人工神经网络(感知器算法的意义) 10:44
P23 [3.4.1] – 人工神经网络(第一次寒冬) 09:54
P24 [3.5.1] – 人工神经网络(多层神经网络) 14:35
三层神经网络可以模拟任意的非线性函数。
note ![]()
P25 [3.6.1] – 人工神经网络(梯度下降算法) 15:27
完成。
note ![]()

P26 [3.7.1] – 人工神经网络(后向传播算法上) 14:02
P27 [3.8.1] – 人工神经网络(后向传播算法下) 11:02
P28 [3.9.1] – 人工神经网络(后向传播算法的应用) 18:22
note ![]() 三层神经网络可以模拟任意决策面的
证明是基于阶跃函数的。
三层神经网络可以模拟任意决策面的
证明是基于阶跃函数的。
- Sigmoid 和 tanh 非线性函数代替阶跃函数;
- 分类问题中基于 SoftMax 函数和交叉熵(Cross Entropy) 的目标函数;
- 随机梯度下降法(SGD)。
在分类问题中,我们经常采用另一种目标函数,即基于 SoftMax 分类函数和交叉熵(Cross Entropy) 的目标函数。
基于交叉熵(Cross Entropy) 的目标函数,其中: \(\mathrm{E}(\mathrm{y})=-\sum_{\mathrm{i}=1}^{\mathrm{K}} \mathrm{Y}_{\mathrm{i}} \log \left(\mathrm{y}_{\mathrm{i}}\right)\)
在信息论中,这个式子叫作交叉熵,它反映的是两个概率分布 $Y$ 与 $y$ 之间的相似程度。
根据信息论,可以证明如下两个事实:
- $E ( y ) > 0$
- 当 $Y$ 确定时,当且仅当 $y = Y$ 时,$E ( y )$ 取最小值
基于上面的事实,我们可以利用梯度下降法求 $E ( y )$ 的局部极值,这样就可以使 $y$ 尽可能地接近 $Y$。
在分类问题中利用 SoftMax 函数和交叉熵(Cross Entropy) 来改进目标函数,实践证明这样的目标函数比前面预测值 $y$ 和真实值 $Y$ 差的模的平方那样的目标函数更有利于训练,在实际中,获得的识别率更高。
P29 [3.10.1] – 人工神经网络(兵王问题 MATLAB 程序) 10:00
完成。
P30 [3.11.1] – 人工神经网络(参数设置) 11:44
训练神经网络的建议
首先是三个训练神经网络的建议,这几个建议应该是学术界一致公认的。
- 一般情况下,在训练集上的 目标函数的平均值(cost) 会随着训练的深入而不断减小,如果这个指标有增大的情况,请停下来。
有两种情况:
- 采用的模型不够复杂,以至于不能在训练集上完全拟合;
- 已经训练很好了。因此停下来检查一下是否训练好,采取相应的措施。
-
分出一些验证集(Validation Set) ,训练的本质目标是在验证集上获取最大的识别率。 因此训练一段时间后,必须在验证集上测试识别率,同时需要保存使验证集上识别率最大的模型参数,作为最后的结果。
- 注意调整学习率(Learning Rate) ,如果刚训练几步损失函数 cost 就增加,一般来说是学习率太高了;如果每次 cost 变化很小,说明学习率太低了。根据实际情况适度的调整学习率是使神经网络快速正确收敛的基础。
训练神经网络的经验
- 目标函数可以加入正则项(regularization term)
- 训练数据归一化
- 参数 w 和 b 的初始化
- Batch Normalization
- 参数的更新策略
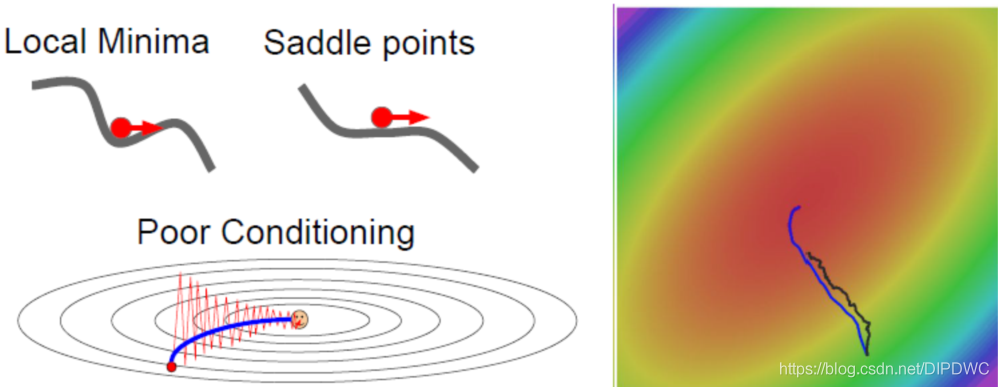
- AdaGrad,解决梯度绝对值分量不平衡。
- Momentum,使搜索路径变的光滑,解决梯度方向随机性。
- Adam 算法。
引入动量解决梯度方向随机化
P31 [4.1.1] – 深度学习(历史发展) 12:20
生成对抗网络(Generative Adversarial Networks)、循环神经网络(Recurrent Neural Networks)、图卷积神经网络(Graph Convolutional Neural Networks)。
人工神经网络的劣势
note ![]() 和支持向量机相比,多层神经网络的劣势:
和支持向量机相比,多层神经网络的劣势:
- 多层神经网络在数学上不够优美,它的优化算法只能获得局部极值,算法的性能与初始值有关。
- 多层神经网络不可解释训练神经网络获得的参数与实际任务的关联性非常模糊。
- 模型可调整的参数很多,它包括网络层数、每层神经元个数、非线性函数、学习率、优化方法、终止条件等,使得训练神经网络变成了一门艺术,而以支持向量机为代表的方法所需要调整的参数却非常少。
- 如果要训练相对复杂的网络,那么需要大量的训练样本。这与支持向量机基于小规模训练样本而产生的方法是背道而驰的。
P32 [4.2.1] – 深度学习(自编码器) 07:19
P33 [4.3.1] – 深度学习(卷积神经网络 LENET) 16:22
note ![]() 卷积神经网络(Convolutional Neural Network, CNN)。
卷积神经网络(Convolutional Neural Network, CNN)。
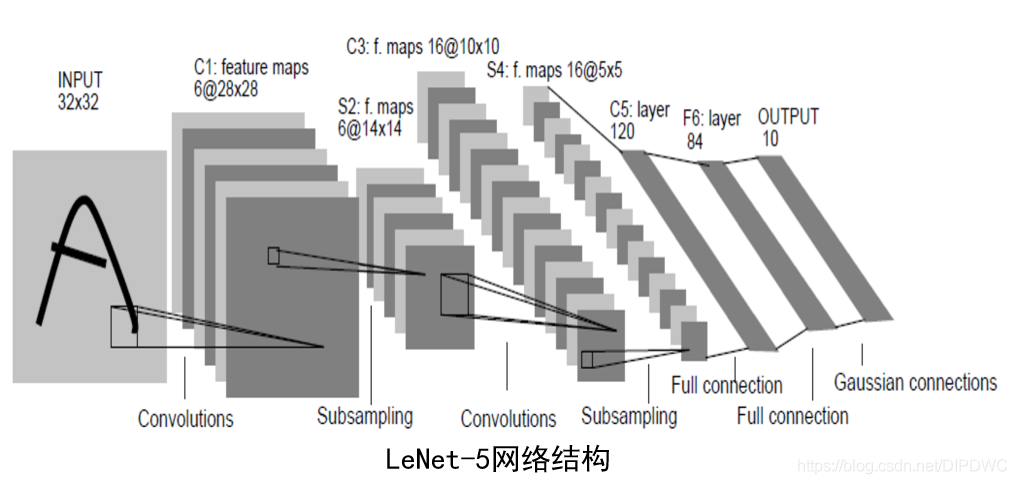
经典的 LeNet 结构
你可以在某种程度上把人类看做为一个生物引导程序,引出一种超级数字智能物种。人类社会是一段非常小的代码,没有他计算机就无法启动,人类的产生就是为了让计算机启动,硅基生命(AI)似乎不能自我演化,它需要生物(人类)作为前导才能进化,人类只是硅基生命的开启程序。 最后一个人类闭上眼睛,就是硅基文明元年。整个宇宙最终会形成一个超级电脑,电脑的最后一个命令是用全部算力制造一个新的碳基宇宙,就是人类。这样周而复始。
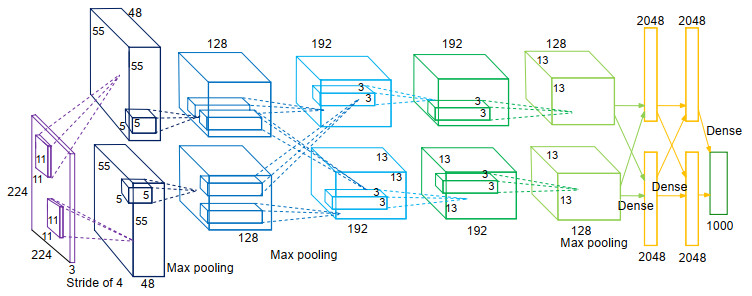
P34 [4.4.1] – 深度学习(卷积神经网络 ALEXNET) 12:04
note ![]() AlexNet 的结构以及 AlexNet 对于卷积神经网络的一系列改进,它们分别是:
AlexNet 的结构以及 AlexNet 对于卷积神经网络的一系列改进,它们分别是:
- Relu 函数 第一个改进以 ReLu 函数代替 LeNet 中的 Sigmoid 或 tanh 函数。
- 最大池化(Maxpooling) 第二个改进是降采样层 Maxpooling 代替 LeNet 的平均降采样。
- 随机丢弃(Dropout) 第三个改进是随机丢弃(Dropout)。
- 数据扩增(Data Augumentation) 第四个改进是数据扩增(Data Augumentation)。
- 用 GPU 加速训练深度神经网络 第五个改进是用 GPU 加速训练过程。
每一個改變都太重要了,基本現在都還是最常用的。
P35 [4.5.1] – 深度学习的编程工具 PYTORCH 06:20
note ![]() TensorFlow、Caffe 和 Pytorch 三种深度学习编程工具。
TensorFlow、Caffe 和 Pytorch 三种深度学习编程工具。
torch.nn 模块之常用激活函数详解 note ![]()
| 名称 | 层对应的类 | 功能 |
|---|---|---|
| S 型激活函数 | torch.nn.Sigmoid | Sigmoid 激活函数 |
| 双曲正切函数 | torch.nn.Tanh | Tanh 激活函数 |
| 线性修正单元函数 | torch.nn.ReLu | ReLu 激活函数 |
| ReLu 函数变体 | torch.nn.LeakyReLu | LeakyReLu 激活函数 |
| 平滑近似 ReLu 函数 | torch.nn.Softplus | ReLu 激活函数的平滑近似 |
P36 [4.6.1] – 深度学习的编程工具 Tensorflow 09:37
P37 [4.7.1] – 深度学习的编程工具 CAFFE 13:10
P38 [4.8.1] – 深度学习(近年来流行的卷积神经网络) 11:24
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(Feature Map)上的像素点在输入图片上映射的区域大小。
note ![]()
用更小的卷积核叠加代替大的卷积核可以起到降低待估计参数的作用。但是多层卷积需要更大的计算量,中间过程过程特征图也需要更多的储存空间,因此 VGGNet 是一个计算和存储开销都较大的网络。
VGGNet
- 增加了网络的深度。
- 用多个 3×3 卷积核叠加代替更大的卷积核,用以增加感受野(Receptive Field)。
GooleNet
GooleNet 提出了 Inception 结构,Inception 结构是用一些 1×1,3×3 和 5×5 的小卷积核用固定方式组合到一起来代替大的卷积核,达到增加感受野和减少参数个数的目的。
2014 年研究人员分析了深度神经网络,并从理论和实践上证明 更深的卷积神经网络能够达到更高的识别准确率 (L.J. Ba and R.Caruana,Do deep nets really need to be deep? NIPS 2014.)。因此,如何构建让更深的卷积神经网络收敛成了研究领域共同关注的问题。
ResNet
在 2015 年,Kaiming He 等人发明了 ResNet,使得训练深层的神经网络成为了可能(K. He,X. Zhang S. Ren and J.sun, Deep residual learning forimage recognition,cVPR2016.)。
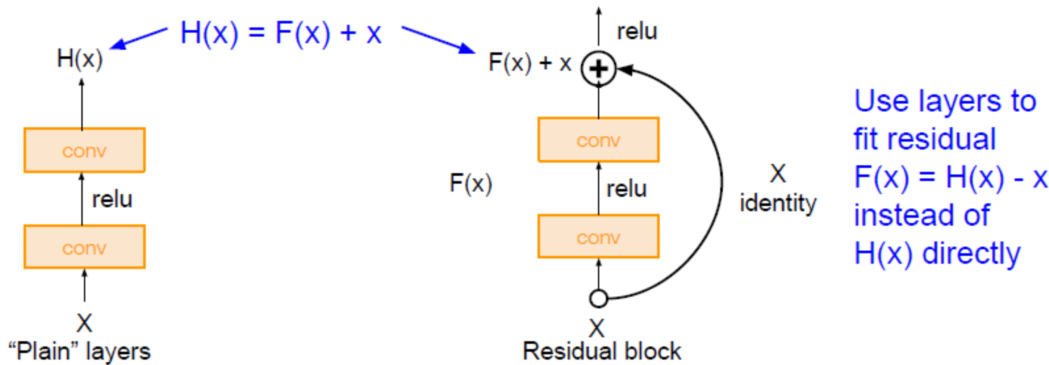
将浅层的输出直接加到深层当中去,当然在实际的添加中,由于浅层和深层的特征图在维度上有可能不一致导致无法直接相加,我们可以用一个线性变换直接把浅层特征图的维度变为深层特征图的维度。
- Batch Normalization 在每个卷积层后加上了 Batch Normalization
- Xavier initialization 使用 Xavier/2 来初始化参数
- SGD + Momentum (0.9) 使用 SGD+Momentum(momentum=0.9)
- Learning Rate:0.1 初始学习率设为 0.1,每到验证误差高原期(validation error plateaus)的时候就下降 10 倍
- Batch size 256 / Mini-batch size 256
- Weight decay 1e-5 / 权重衰减 weight decay 设为 1e-5
- No dropout 没有使用 dropout,因为 BN 已经减少了过拟合,而且效果很好
寻找更好的神经网络结构的努力一直在持续,严格的说这是一个需要在 识别精度、计算量、存储量 三个方面平衡取舍的问题。近年来,流行的趋势是利用紧凑的、小而深的网络代替以往稀疏的、大而浅的网络,同时在具体的实践过程中加入一些创意和技巧。近年来流行的例如 ShuffleNet、MobileNet 等都是其中的典型代表,另一方面, 网络结搜索(Network Architecture Search) ,即如何从一大堆网络结构中搜索适合具体的网络结构成为领域内另一个热点问题。
不同网络计算量和识别率的联合比较。横坐标是网络的计算量,纵坐标是网络的 Top1 识别率。
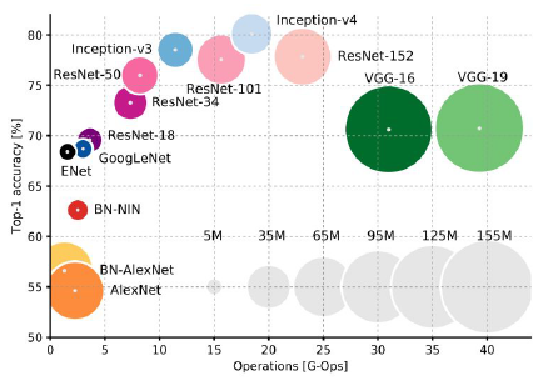
- VGG:效率最低,使用最多内存,但表现得确实好
- GoogleNet:最高效
- AlexNet:精确度最低,计算量很小,但占用内存很大。
- ResNet:在内存使用和操作复杂度之间平衡,但精确度最高
- GoogleNet 和 ResNet 没有使用大型的全连接层,而是在神经网络末端使用全局平均池化 global average pooling,大幅降低参数数量。
P39 [4.9.1] – 人脸识别介绍 13:57
在训练的时候保留最后一层 SoftMax,而在测试的时候却不要最后一层,将倒数第二层 160 个维度作为最后人脸识别的特征。在测试时,每张人脸通过卷积神经网络,获得 160 维向量,利用距离量度,如 欧氏距离和余弦距离 等,算出基于这 160 维向量的人脸距离,最终通过阈值获得识别结果。
Large-Margin SoftMax Loss 可以有效地提高人脸识别的准确率。
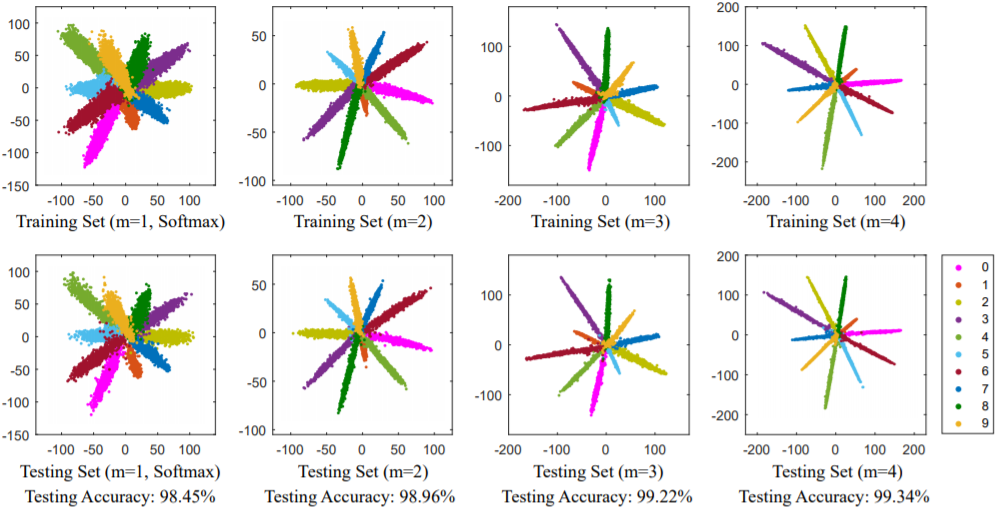
基于 Large-Margin SoftMax Loss 的思想,近年来进一步提出了 CosFace 和 ArcFace,这两种改进方法的思路与 Large-Margin SoftMax Loss 大同小异,都是基于限制同一类特征分布在狭窄的角度范围内。
Triplet Loss “三元组损失函数”。
note ![]() 需要强调在实现人脸识别的时候,我们首先应该做的是人脸检测和人脸对齐,目前常用的人脸检测程序是 MTCNN ,它也是基于深度学习的检测系统,可以检测人脸的眼睛、鼻子和嘴巴五个特征点。可以以此获取人脸的位置,同时基于检测到的两个眼睛与水平线的夹角对人脸实现转正的操作,提高人脸识别准确率。
需要强调在实现人脸识别的时候,我们首先应该做的是人脸检测和人脸对齐,目前常用的人脸检测程序是 MTCNN ,它也是基于深度学习的检测系统,可以检测人脸的眼睛、鼻子和嘴巴五个特征点。可以以此获取人脸的位置,同时基于检测到的两个眼睛与水平线的夹角对人脸实现转正的操作,提高人脸识别准确率。
P40 [4.10.1] – 目标检测与分割上 12:52
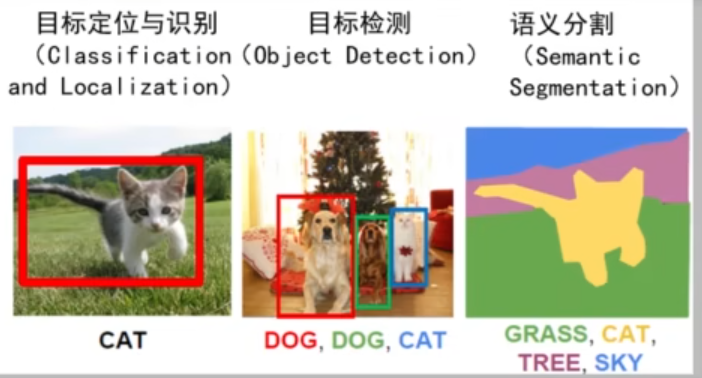
- 第一种情形,单目标检测中的目标定位与识别,即图像中有一个目标,我们需要检测出它的位置,同时识别出它的类别。
- 第二种情形,多目标检测中的目标定位与识别,即图像中有多个目标,我们需要分别检测出它的位置,同时对每个目标都要进行识别。
- 第三种情形,语义分割,我们不仅要检测和识别出图像中的各种目标,还要确定每个目标所对应的像素。
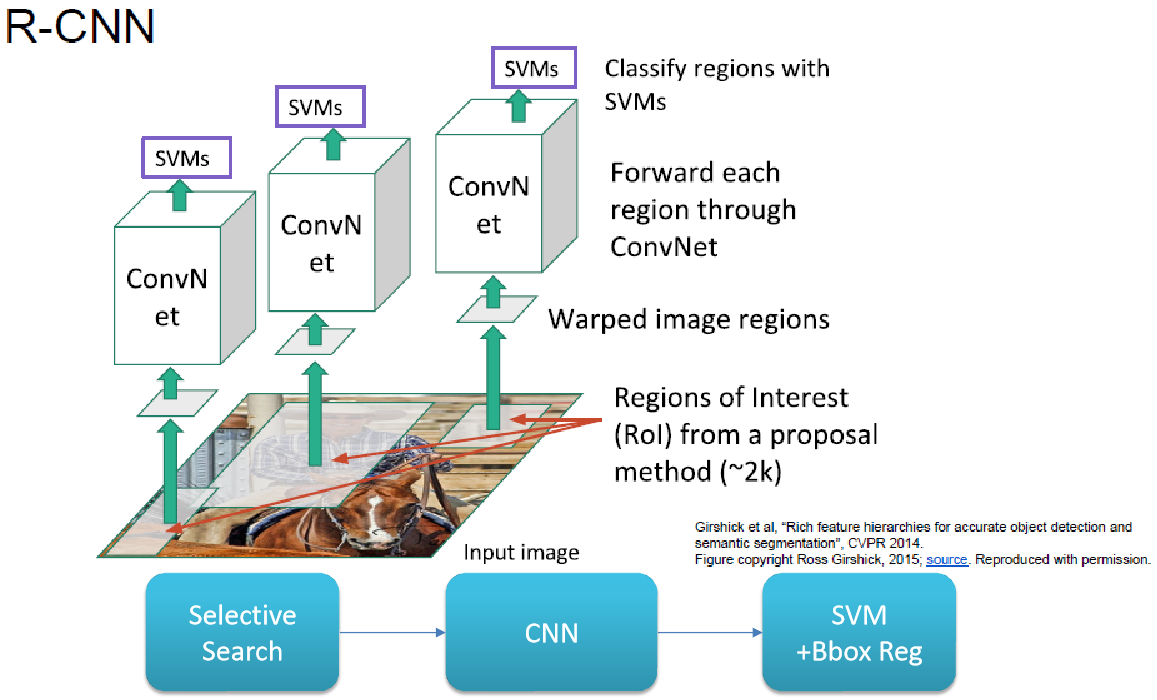
note ![]() RCNN R-CNN(Regions with CNN feature)的概念,用来处理上述情形。其核心思路是用大大小小的方框遍历所有的图像是不现实的,我们需要一个计算量不那么大的算法,提出 ROI(Region of Proposal,or Proposal)。
R-CNN 的主要思想是用 Selective Search 去产生候选的方框(Proposal),将这些候选方框输入到 CNN 中,最后用 SVM 来判断这些候选方框中有没有目标。
RCNN R-CNN(Regions with CNN feature)的概念,用来处理上述情形。其核心思路是用大大小小的方框遍历所有的图像是不现实的,我们需要一个计算量不那么大的算法,提出 ROI(Region of Proposal,or Proposal)。
R-CNN 的主要思想是用 Selective Search 去产生候选的方框(Proposal),将这些候选方框输入到 CNN 中,最后用 SVM 来判断这些候选方框中有没有目标。
Fast R-CNN 首先用 CNN 的卷积层对整幅图像进行卷积操作,在中间某一层的特征图上再用 ROI-Pooling 来归一化每个候选框区域的输出。
Faster R-CNN Faster R-CNN 在卷积后特征图上滑动窗口,用不同长宽比的矩形作为候选区域,用一个小网络来判断这些候选区域是不是存在目标,对于确定是目标的候选区域运用前面的 ROI-Pooling 来进行归一化,最终获得输出的结果。
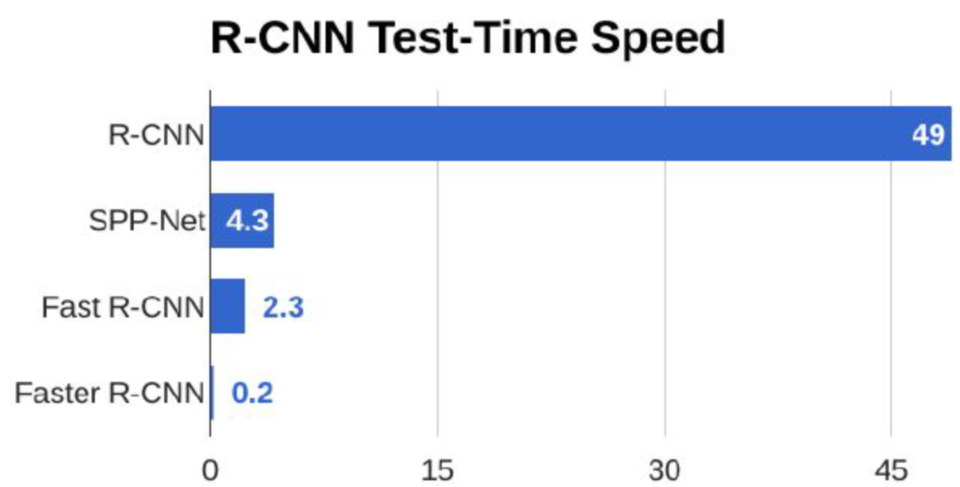
P41 [4.11.1] – 目标检测与分割下 12:00
目标检测 YOLO(YOU ONLY LOOK ONCE)
MTCNN,利用深度学习将人脸检测和人脸特征点定位结合起来。
- Face detection
- Facial landmarks localization
三个子网络:
- P-Net(Proposal Network)
- 检测图中的人脸
- 产生多个人脸候选框和回归向量
- 用回归向量对候选窗口进行校准
- 通过非极大值抑制 NMS 来合并高度重叠的候选框
- R-Net(Refine Network)
- 输出候选框置信度(根据置信度消减候选框数量)和回归向量。
- 通过边界框回归和 NMS 精调候选框的位置。
- O-Net(Output Network)
- 作用:消减框数量同时精调回归框
- 输出 5 个人脸的关键点坐标。
全卷积网络 FCN
- 视频场景人数估计。(Person Count)
Mask R-CNN http://counting.movingshop.cn
- 1.2k TensorFlow Object Counting API tensorflow_object_counting_api

-
2.1k 输入一张包含数学计算题的图片,输出识别出的数学计算式以及计算结果。mathAI
- Objects Counting by Estimating a Density Map With Convolutional Neural Networks
- Computer Vision Researchers Are Using Blobs To Count Objects
各种深度网络,有点逛菜市的感觉。
P42 [4.12.1] – 时间序列的深度学习模型(RNN 和 LSTM) 14:50
RNN 循环神经网络
LSTM 长短期记忆网络(Long-Short Term Memory, LSTM)论文首次发表于 1997 年。由于独特的设计结构,LSTM 适合于处理和预测时间序列中间隔和延迟非常长的重要事件。 LSTM 的表现通常比普通时间循环神经网络及隐马尔可夫模型(HMM)更好,比如用在不分段连续手写识别上。 2009 年,用 LSTM 构建的人工神经网络模型赢得过 ICDAR 手写识别比赛冠军。 LSTM 还普遍用于自主语音识别,2013 年运用 TIMIT 自然演讲数据库达成 17.7% 错误率的纪录。 作为非线性模型 ,LSTM 可作为复杂的非线性单元用于构造更大型深度神经网络。
P43 [4.13.1] – 生成对抗网络 11:48
GAN
- 真实人脸生成
- 侧脸转正。
- 图像翻译。
GAN 的缺点:
- 训练不稳定,难以直观观测训练过程,难以有效收敛,很多时候收敛需要运气。
- 模式崩溃(mode collapse)。
P44 [5.1.1] – 强化学习(Q-Learning 和 epsilon-greedy 算法) 16:51
强化学习就开始有点看不懂了,更难了。mark
强化学习与监督学习的区别
- 训练数据中没有标签,只有奖励函数 (Rewar Function)
- 训练数据不是现成给定,而是由行为 (Aetion) 获得。
- 现在的行为 (Aetion) 不仅影响后续训练数据的获得,也影响奖励函数 (Reward Function) 的取值。
- 强化学习与监督学习的区别训练的目的是构建一个“状态->行为”的函数
- 状态 (State) 目前内部和外部的环境
- 智能体 (Agent) 通过这个函数;决定此时应该采取的行为;最终获得最大的奖励函数值
- 马尔可夫假设
- 下一个时列的状态只与这一时刻的状态以及这一时刻的行为有关
- 下一个时刻的奖励函数值只与这一时刻的状态及这一时刻的行为有关
epsilon-greedy 算法
- 探索 稍微偏离目前的最好策略以便达到搜索更好策略的目的
- 利用 运用目前的最好策略获取较高的奖赏 (Reward)
对于状态数和行为数很多时,这两个算法将会遇到困难。
P45 [5.2.1] – 强化学习(深度强化学习)09:38
DEEP Q-NETWORK (DQN)
P46 [5.3.1] – 强化学习(policygradient 和 actor-critic) 10:48
奖励函数,行为获得很久后才能获得,比如下棋。 下棋下到最后,才有输和赢而前面的每一步,虽然有些奖励函数的线索,但与真实输赢的相关性直到最后才能被完全体现。
引入估值函数。
actor-critic
- actor – 演员
- critic – 评论家
P47 [5.4.1] – 强化学习(AlphaGo 上) 13:54
中国规则
- 无气自提
- 禁止全局同形
- 地大者胜
必胜策略(上帝策略) 要么使先走的人则然获胜,要么使后走的人必然获胜。
P48 [5.5.1] – 强化学习(AlphaGo 下) 10:28
AlphaGo 围棋 论文笔记 ![]() 三个深度策略网络 (Policy Networks),一个深度估值网络 (Value Network)
三个深度策略网络 (Policy Networks),一个深度估值网络 (Value Network)
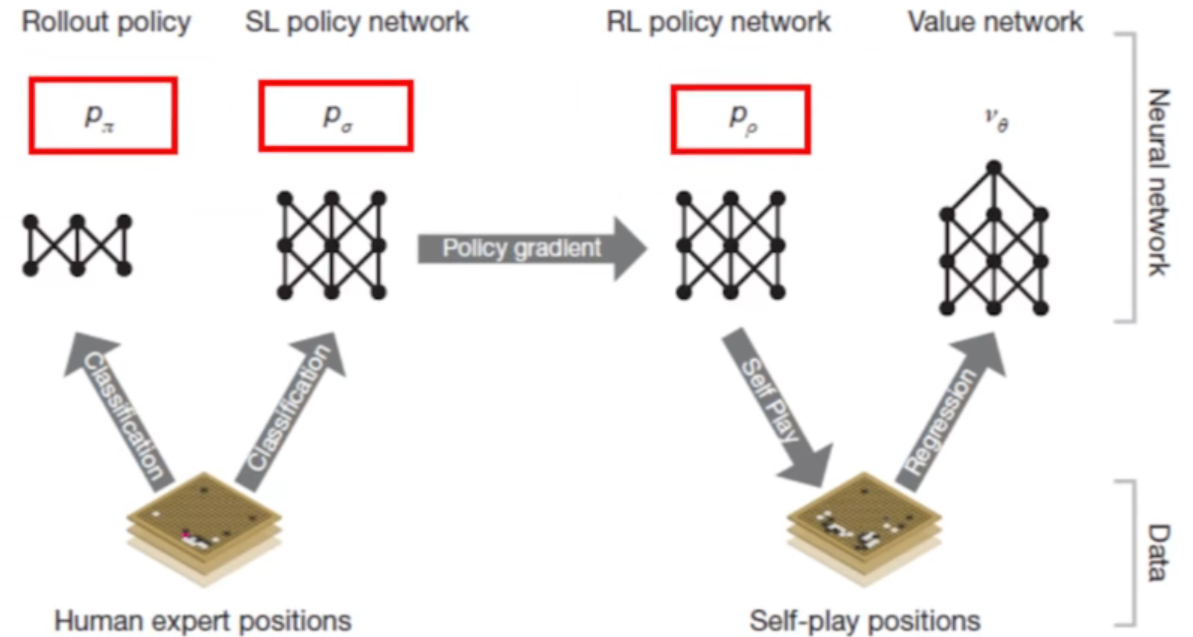
棋力一般,棋力更强,棋力更快。
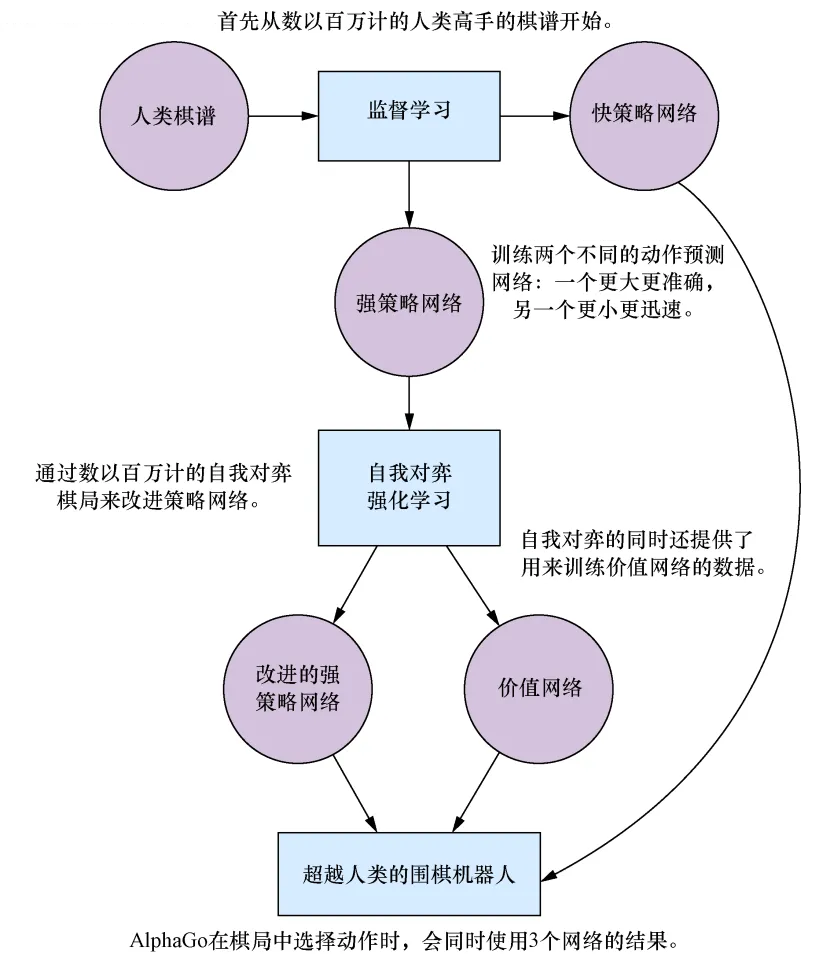
深度策略网络 $\rho_\sigma$ (Supervised Learning Policy Network)
模仿走子网络,因为它的目的是模仿网络高手。
- 输入:当前棋盘状态
- 输出:下一步的走法。
- 训练数据:KGS GO SERVER 上的三亿个样本。
- 网络设置:13 层深度网络。
深度策略网络 $\rho_\rho$ (Reinforcement Learning Policy Network)
自学走子网络,自己跟自己下棋,通过这种方式进一步学习。 策略网络(PolicyNetwork),给定当前局面,预测并采样下一步的走棋。
- 网络结构、输入输出与 $\rho_\sigma$ 完全一样
- 开始初始化网络参数
- 参数更新策略,自己和自己下棋,不断下下去直到分出胜负
为了避免对局的网络过于相似而出现的过拟合,应用了如下策略:
- Step 1: 将监督字习的网络复制作为增强学习的初始网络
- Step 2: 将当前版本的网络与之前的某个随机的版本对局得到棋局和棋局结果(输赢)
- Step 3: 根据棋局和棋局结果利用 REINFORCE 算法更新参数最大化期望结果(赢)
- Step 4: 每 500 次迭代就复制当前网络参数到对手池中用于 Step 2
深度策略网络 $\rho_\pi$ (Rollout Policy Network)
快速走子(Fastrollout),目标和策略网络一样,但在适当牺牲走棋质量的条件下,速度要比策略网络快 1000 倍。
- 输入特征比 $\rho_\sigma$ 和 $\rho_\rho$ 少
- 网络结构更简单 换句话说,这个网络以牺牲准确率换取速度。24.2% 正确率 2um 一步。
深度估值网络 $v_\theta$ (Value Network)
棋盘价值网络。 价值网络(ValueNetwork),给定当前局面,估计是白胜概率大还是黑胜概率大。
- 输入:当前棋盘状态(与 $\rho_\sigma$ 输入一样),以及执黑或执白
- 输出:获胜的概率(一个 0 到 1 的数)
- 参数更新策略:用 $\rho_\pi$ 来走很多轮来预测 真实值 $z$。
蒙特卡洛树搜索 (Monte Carlo Tree Search)
下棋方法一蒙特卡洛树搜索 (Monte Carlo Tree Search) 把以上这三个部分连起来,形成一个完整的系统。 多次模拟未来棋局,然后选择在模拟中选择次数最多的走法。
Alpha Zero
将策略网络和估值网络合并为一个网络。
P49 [6.1.1] – ADABOOST 15:33
自适应提升 (Adaptive Boosting) 简称 ADABOOST
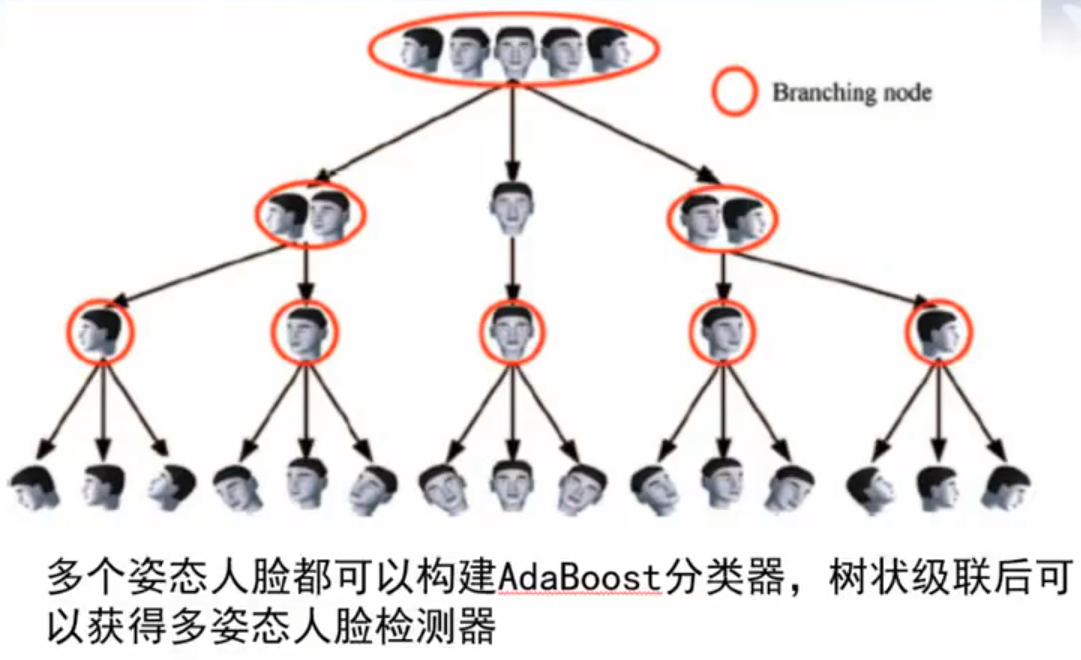
使用 AdaBoost 进行目标检测 ![]()
核心思想 融合一些弱分类器获得强分类器。
ADABOOST 的核心流程 先用一部分特征训练一些较弱的分类器然后再将这些较弱的分类器逐步提升为强的分类器。 ADABOOST 的核心是调整训练样本的分布,使得先前分类器做错的训练样本在后续学习中获得更多的关注,然后基于调整后的样本分布来训练下一个分类器。 最后再用权重系数将获得的各个弱分类器组合起来形成强分类器。
最终得到能表征人脸的 Haar 特征:

AdaBoost 人脸检测流程
- 在图像中,对每一个 24*24 的格子遍历使用分类器,如果是人脸则输出。
- 将图像缩小,长宽同时除以 1.2,在用分类器遍历每一个 24*24 的格子。如果是人脸,将该处位置坐标乘以 1.2,等比例放大到原图。
- 重复 2,直到图像长或宽小于 24 个像素为止。
P50 [6.2.1] – 人工智能中的哲学 12:39
又看了一晚上的 AlphaGo,这玩意只会下围棋,不会别的,更谈不上独立的意识。目前的 AI 算法只是看上去智能罢了,人类拟合出来的超高维度函数,距离真正的人工智能遥不可及。
P51 [6.3.1] – 主成分分析 17:23
主成分分析是一种统计方法通过 正交变换 将一组可能存在相关性的变量转换为一组线性不相关的变量,达到数据压缩的目的。
在二维条件下,PCA 的目的是找到一个方向,使得数据在这个方向上投影后的 方差最大 。
占据 99% 能量的 M 值 占据 95% 能量的 M 值
P52 [6.4.1] – K - 均值聚类 12:20

期望最大化算法 Expectation-maximization algorithm,EM 算法 K 均值算法 目标函数 E 的局部极值
P53 [6.5.1] – 高斯混合模型 13:01
和分水岭算法有点像。 高斯混合模型(GMM) 可以看做是 k-means 模型的一个优化。
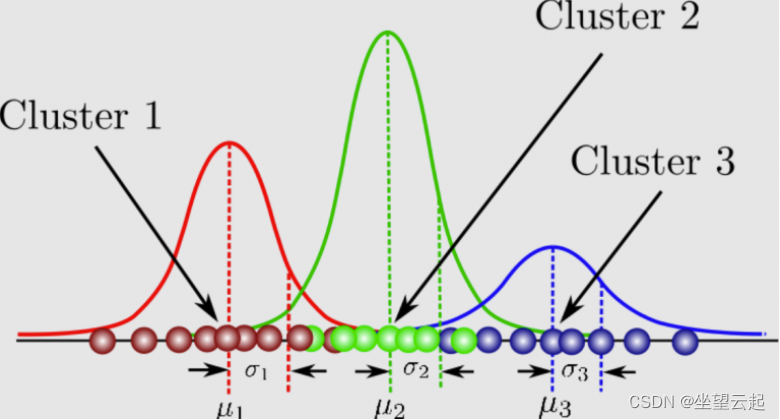
以下是使用高斯混合模型的三个不同步骤:
- 确定定义每个高斯如何相互关联的协方差矩阵。两个高斯分布越相似,它们的均值就越接近,反之亦然,如果它们在相似性方面彼此相距很远。高斯混合模型可以具有对角线或对称的协方差矩阵。
- 确定每组中的高斯数定义了有多少簇。
- 选择定义如何使用高斯混合模型优化分离数据的超参数,以及决定每个高斯的协方差矩阵是对角线还是对称的。

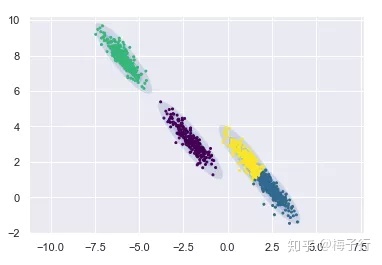
应用:视频前景背景检测,三个高斯。
说话人识别。
- 去除静音。能量(Energy)过零率(Zero Crossing Rate)
- 提取特征。MEL 倒谱系数(MFCC)。
P54 往年现场版 - 教科书介绍 06:31

Reference Books
- 机器学习,周志华,清华大学出版社,2016
- 统计学习方法,李航,清华大学出版社,2012
- Machine Learning in Action,P. Harrington, 人民邮电出版社
- Pattern Recognition and Machine Learning(模式识别与机器学习),Christopher M. Bishop,2006
- Machine Learning: A Probabilistic Perspective, K.P Murphy
- MachineLearning(机器学习) Tom MMitchell, 机械工业出版社,2003 年。
- Deep Learning, I. Goodfellow, Y. Bengio and A. Courville, 2016.
- Stanfrod Web course by Andrew Ng https://www.coursera.org/course/ml
- Stanfrod Web course by Fei-fei Li https://cs231n.Stanford.edu
P55 成绩安排 17:44
P56 概念介绍 10:20
- classification: 标签是离散的值。
- regression: 标签是连续的值。
P57 这门课程的内容概述 17:36
P58 没有免费午餐定理 20:41
我们认为:特征差距小的样本更有可能是同一类。
P59 支持向量机(线性模型)问题 20:05
P60 支持向量机(线性模型)数学描述 38:28
P61 支持向量机(线性模型)的图像展示 01:33
P62 支持向量机(非线性模型)优化目标函数和限制条件 11:29
P63 支持向量机(非线性模型)低维到高维映射 28:28
P64 支持向量机(非线性模型)原问题和对偶问题 30:51
P65 支持向量机 - 将支持向量机原问题转化为对偶问 57:33
P66 支持向量机 – 核函数介绍 07:36
P67 支持向量机的应用 – 兵王问题(规则介绍) 10:44
P68 支持向量机的应用 – 兵王问题(参数设置) 31:51
P69 支持向量机的应用 – 兵王问题(测试结果) 04:23
P70 ROC 曲线 18:19
ROC(Receiver Operating Character)曲线,是一条横坐标 FP,纵坐标 TP 的曲线。
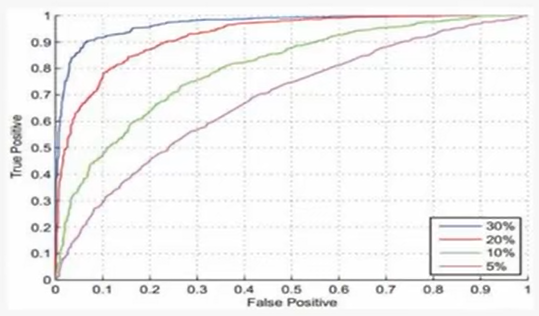
P71 支持向量机 – 处理多类问题 11:58
P72 人工神经网络 – 神经元的数学模型 17:27
P73 人工神经网络 – 感知器算法 38:58
P74 人工神经网络 – 人工智能的第一次寒冬 15:07
Marvin Lee Minsky,1969 年图灵奖获得者,创建麻省理工学院人工智能实验室。 线性可分 & 线性不可分。
P75 人工神经网络 – 多层神经网络 11:44
加入非线性激活函数后,多层网络才有能力表示非线性决策边界;但不能简单说一个阶跃函数就能解决所有非线性问题。
P76 人工神经网络 — 三层神经网络可以模拟任意决策面 15:54
三层神经网络可以模拟任意决策面。
P77 人工神经网络 — 后向传播算法 1:29:55
P78 人工神经网络 – 参数设置 1:22:15
训练建议
- 一般情况下,在训练集上的目标函数的平均值(cost)会随着训练的深入而不断减小,如果这个指标有增大情况,停下来。 有两种情况:第一是采用的模型不够复杂,以致于不能在训练集上完全拟合, 第二是已经训练很好了。
- 分出一些验证集(Validation Set),训练的本质目标是在验证集上获取最大的识别率。 因此训练一段时间后,必须在验证集上测试识别率,保存使验验证集上识别率最大的模型参数作为最后结果。
-
注意调整学习率(Learning Rate)如果刚训练几步, cost 就增加,一般来说是学习率太高了;如果每次 cost 变化很小,说明学习率太低。
- Batch Normalization 比较好用,用了这个后,对学习率、参数更新策略等不敏感。 建议如果用 BatchNormalization,更新策略用最简单的 SGD 即可,我的经验是加上其他反而不好。
- 如果不用 Batch Normalization。我的经验是,合理变换其他参数组合,也可以达到目的。
- 由于梯度累积效应,AdaGrad、RMSProp、Adam 三种更新策略到了训练的后期会很慢,可以采用提高学习率的策略来补偿这一效应。
P79 深度学习数据库准备 18:00
人工神经网络的历史–多层网络 多层神经网络的优势:
- 基本单元简单,多个基本单元可扩展为非常复杂的非线性函数。因此易于构建,同时模型有很强的表达能力。
- 训练和测试的计算并行性非常好,有利于在分布式系统上的应用。
- 模型构建来源于对人脑的仿生,话题丰富,各种领域的研究人员都有兴趣,都能做贡献。
多层神经网络的劣势:
- 数学不漂亮,优化算法只能获得局部极值,算法性能与初始值有关。
- 不可解释。训练神经网络获得的参数与实际任务的关联性非常模糊。
- 模型可调整的参数很多(网络层数、每层神经元个数学习率、优化方法、终止条件等等),使得训非线性函数、练神经网络变成了一门“艺术”。
- 如果要训练相对复杂的网络,需要大量的训练样本。
数据库介绍 自编码器(Auto encoder) 卷积神经网络(Convolutional Neural Networks CNN) 深度学习工具(Tensorflow 和 Caffe) 流行的卷积神经网络结构(LeNet,AlexNet,VGGNet,GoogLeNet,ResNet) 我们实验室的工作
P80 深度学习自编码器 23:42
深度学习三剑客的坚持 LeCun:“这种算法很有价值,不知为什么要放弃它。75 ““智能产生于人脑,所以从长远来说,人工智能应 Hinton: 该像大脑系统一样工作。 一起起组成了“Deeplearning这三人从2003年开始,conspiracy”,悄悄开发了 10 层以上的人工神经网络。
2006 年是深度学习复兴中的标志性节点之一 ,Hinton 在 SCIENCE 上发文,提出一种叫做自动编码机 (Auto-encoder) 的方法, 部分解决了神经网络参数初始化的问题。
P81 深度学习 卷积神经网络 LeNet 1:18:45
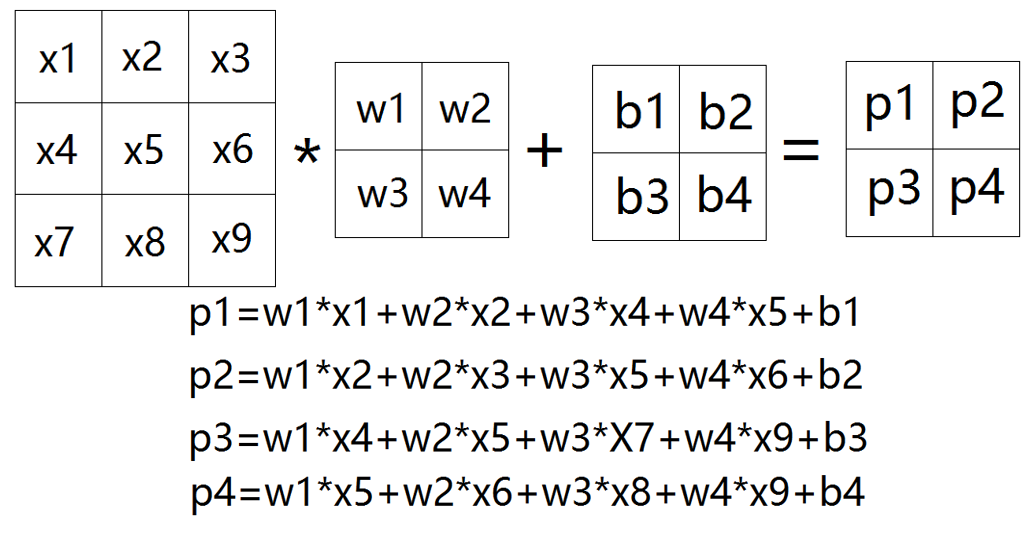
等价于:
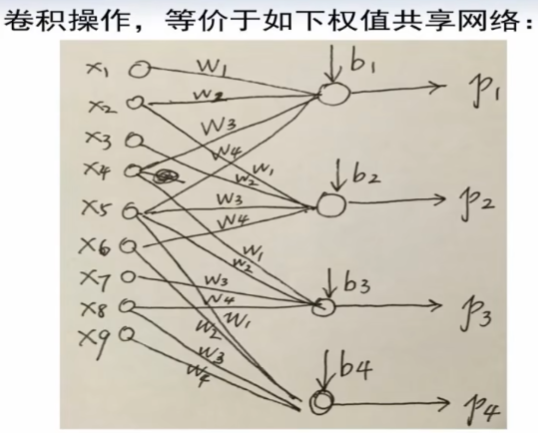
P82 深度学习 – 卷积神经网络(AlexNet) 39:22
提出了最大池化(MaxPooling)的概念,即对每一个邻近像素组任 AlexNet 中,成的“池子”,选取像素最大值作为输出。 在 LeNet 中,池化的像素是不重叠的;而在 AlexNet 中进行的是有重叠的池化。 实践表明,有重叠的最大池化能够很好的克服过拟合问题,提升系统性能。
-
随机丢弃(Dropout)。为了避免系统参数更新过快导致过拟合,每次利用训练样本更新参数时候, 随机的“丢弃一定比例的神经元,被丢弃的神经元将不参加训练过程,输入和输出该神经元的权重系数也不做更新。 这样每次训练时训练的网络架构都不一样,而这些不同的网络架构却分享共司的权重系数。 实验表明,随机丢弃技术减缓了网络收敛速度,也以大概率避免了过拟合的发生。
-
增加训练样本。尽管 ImageNet 的训练样本数量有超过 120 万幅图片,但相对于 6 亿待估计参数来说,训练图像仍然不够。 Alex 等人采用了多种方法增加训练样本,包括:1. 将原图水平翻转;2. 将 26x256 的图像随机选取 224x224 的片段作为输入图像。 运用上面两种方法的组合可以将一幅图像变为 2048 幅图像。还可以对每幅图片引入一定的噪声,构成新的图像。 这样做可以较大规模增加训练样本,避免由于训练样本不够造成的性能损失。
P83 深度学习 – 编程工具(Caffe 和 Tensorflow) 29:32
P84 深度学习 – 近年来流行的网络结构 19:05
ResNet,残差网络。为什么要这么做呢?这样好是实验做出来的结果,你如果做一个也比较好,也是可以的,目前来说没有太多的理论依据。
P85 深度学习 – 卷积神经网络的应用 18:40
他直接用 Alex Net,他直接用 Alex Net,然后呢,他把 Alex Net,然后呢,他把 Alex 在这里已经训练好了嘛,1000 个类嘛, 他在用我的那个训练的样本,就说大概有 20 多类水果,每一类水果可能有 50 张样本,用这 1000 张。 1000 张左右左右的这个训练机,对它进行微微的调用,就对这个已经训练好的二类的去进行微微的调用, 因为这个二类的这 1000 类当中可能有水果,但它没有那么细致的划分到底是哪一种水果,但是啊, 你用特别小的一个数据集,你就针对这个大网络进行一个微调,最后得到的效果。 比第二名用传统的方式好特别多好特别多,所以说所以说迁移学习有的时候他跨度是很大的, 经常我们我们所做的事情也是也是这样子的一个状况,当然还有另外的一种做法,还有另外的一种做法,迁移学习的另外一种。
人脸验证的关键是将人脸图像映射到一个特征空间,在这个空间中同一个人的距离更近,不同人的距离更远。 这里我们采用分类监督来学习这样一个特征空间。 用 Caffe 实现人脸验证,先训练一个人脸分类网络,接着把网络倒数第二个全连接层作为特征层(512 维)。
- 刘络结构首先定义一个 28 层的 ResNet。
- 优化目标设计我们的目标函数。参照文献,我们把目标函数确定为最小化下式:
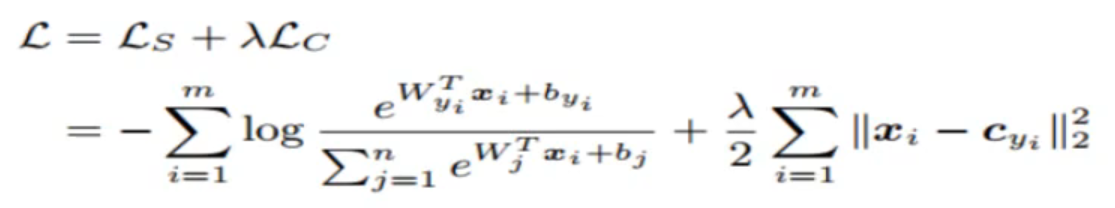
第一项是 softmax loss,第二项是 center loss。
卷积神经网络压缩:有了一个神经网络,尽可能降低它的复杂度,或者降低它的存储容量,同时又不能让它的识别率下降太多。
Transfer Learning 迁移学习 把一个 Domain 的经验迁移到另一个 Domain 上去。
比如之前一个用外国人脸训练的人脸识别模型,要想让它识别亚洲人的脸,可以用 10 万张亚洲人的脸对模型进行微调,再用 4 万张身份证人脸再进行调优。
- 用训练好的模型做特征提取器,比如用 AlexNet 模型的输出,再进行神经网络或者 SVM 分类,这种应用目前非常多。
- 也可以把训练好的模型当做识别器,比如对 AlexNet 模型参数再进行几种水果的分类。
P86 AlphaGo(围棋有必胜策略的证明) 08:58
P87 强化学习 Q - learning 1:18:08
求最佳策略的迭代算法 求最佳策略的迭代算法 定住 V 算 π,然后定住 π 算 V,不断循环,最后结果会收敛。


Q-learning 的劣势:
- 在一些应用中,状态数或行为数很多时,会使 Q 函数非常复杂,难以收敛。 例如图像方面的应用,状态数是(像素值取值范围数)~(像素个数)。 这样的方法,对图像和任务没有理解,单纯通过大数据来获得收敛。
- 很多程序,如下棋程序等,REWARD 是最后获得(输或赢),不需要对每一个中间步骤都计算 REWARD。
P88 强化学习(policy gradience) 19:23
- 目前强化学习的发展状况:在一些特定的任务上达到人的水平或胜过人,但在一些相对复杂的任务上,例如自动驾驶等,和人存在差距。
- 和真人的差距,可能不完全归咎于算法,传感器、机械的物理限制等,也是决定性因素。
- 机器和人的另一差距是:人有一些基本的概念,依据这些概念,人能只需要很少的训练就能学会很多,但机器只有通过大规模数据,才能学会。
- 但是,机器速度快,机器永不疲倦,只要有源源不断的数据,在特定的任务上,机器做得比人好,是可以期待的。
P89 增强学习 _(AlphaGo) 23:25
AlphaGo 介绍 Mastering the game of Go with deepneural networks and tree search 2016.10.20 开源代码:RocAlphaGo
深度策略网络 $p_\sigma$: (Supervised Learning Policy Network)
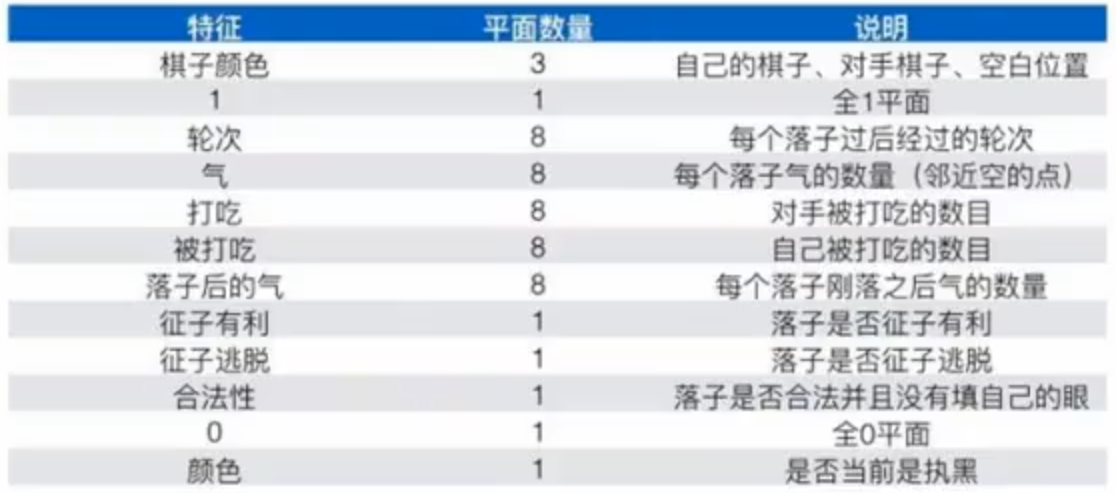
有一个全 0 平面,一个全 1 平面,很奇怪。
P90 特征提取 – 主成分分析(PCA) 1:13:04
note 主成分分析法是一种降维的统计方法,在机器学习中可以作为数据提取的手段。
主成分分析:构造一个 A,b,使 Y=AX+b。其中 A 维度 M*N,X 维度 N*1,b 维度 M*1,则 Y 维度 M*1。
主成分分析可以看成是一个一层的,有 M 个神经元的神经网络(即 Y=WTX+b,主成分分析和该公式本质一样)。
PCA 和自编码器差不多。
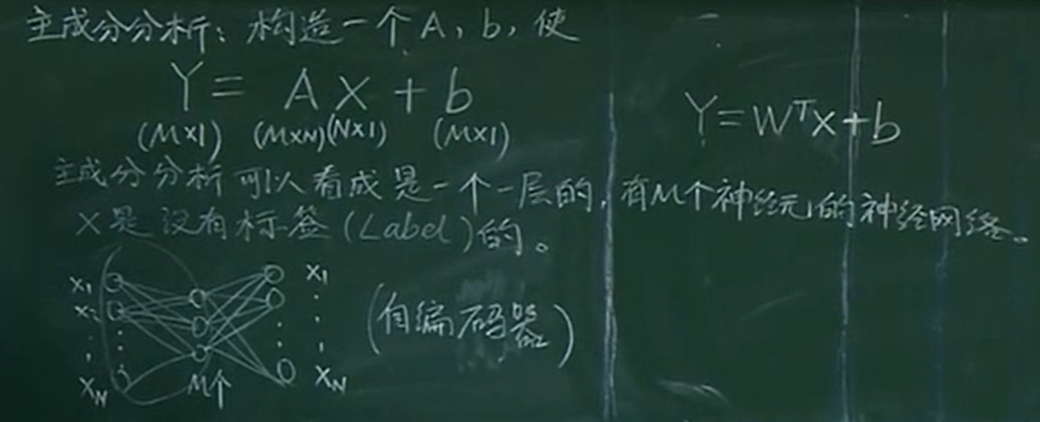
主成分分析:寻找使方差最大的方向,并在该方向投影。
SVD 是 PCA 的一个快速算法求解实现。 PCA 的算法两种实现方法
- 基于 SVD 分解协方差矩阵实现 PCA 算法
- 基于特征值分解协方差矩阵实现 PCA 算法
P91 特征选择 – 自适应提升(AdaBoost) 1:11:15
定理:随着 M 的增加,AdaBoost 最终分类器 $G(X)$ 在训练集上错误将会越来越小。
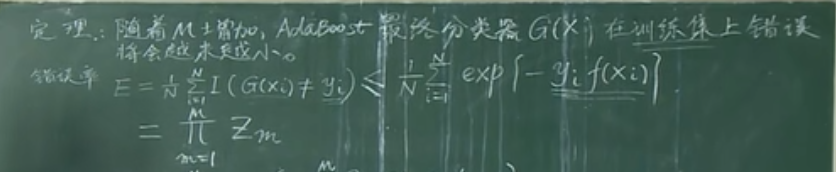
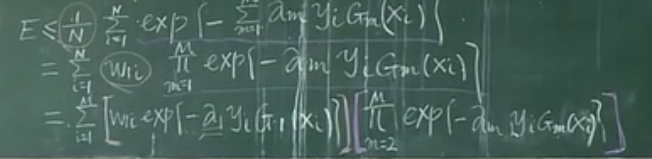

汽车的发明虽让马车夫这一职业退场,却催生了司机、维修工、加油站职员、车评人等一系列职业。 大家能够看到现在的工作会消失,但是我们看不到什么新的工作机会会被创造出来。 就像 100 年前、200 年前那些人,看不到后来产生的新的工作机会一样。 虽然有些工作机会没了,但是更多的机会出现了。人们工作效率的提升,可以养活更多的人,而每个人的生活又变得比以前更好了。
P92 目标检测 (RCNN 和 FCN) 57:25
目标检测- 以人脸检测为例
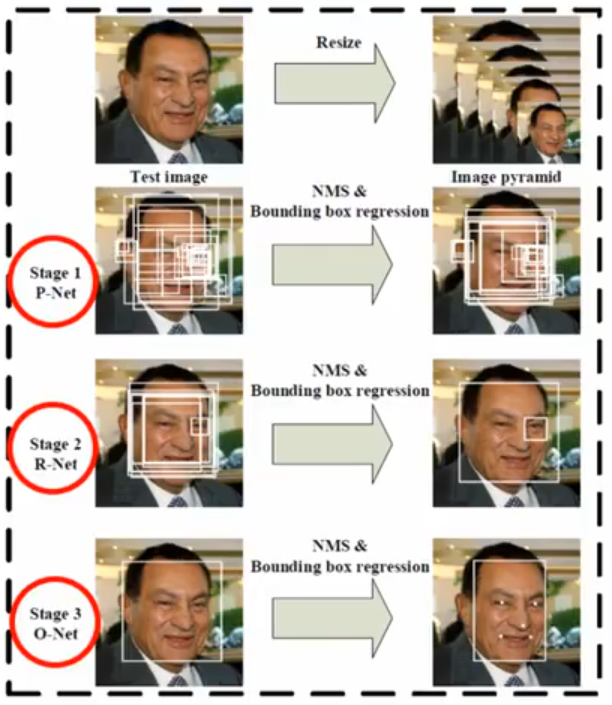
- P-Net (Proposal Network)
- 该网络主要是检测图中人脸,产生多个人脸候选框和回归向量,再用回归向量对候选窗口进行校准, 最后通过非极大值抑制 NMS 来合并高度重叠的候选框。
- R-Net(Refine Network)
- 该网络同样输出候选框置信度(根据置信度削减候选框数量)和回归向量,通过边界框回归和 NMS 精调候选框的位置
- O-Net(Output Network)
- 比 R-Net 层又多了一层卷积层,处理结果更加精细,作用和 R-Net 层作用一样(削减框数量同时精调回归框)。 再者,该层对人脸区域进行了更多的监督,最后输出 5 个人脸关键点坐标。
P93 概率分类法概述 19:54

P94 概率密度估计 – 朴素贝叶斯分类器 16:41
P95 概率密度估计 – 高斯密度函数 31:06
构造目标函数,极大似然法,Maximum Likelihood

P96 概率密度估计 – 高斯混合模型 03:47
求解高斯混合模型的几种方法:

P97 EM 算法(高斯混合模型和 K - 均值算法) 48:44
EM 算法 (Expectation-Maximization algorithm) 高斯混合模型是非凸问题,无法求全局极值,只能求局部极值。
EM 算法通常只能保证目标函数单调改进并收敛到局部最优或驻点,不能保证全局最优。 梯度下降、启发式方法等也只是求解局部最优问题的常用手段,并不能保证适用于任何局部极值问题。
EM 算法优点
- 不需要调任何参数
- 编程简单
- 理论优美
高斯混合模型,是先有鸡还是先有蛋的问题,先假设样本的 label,还是先假设分布 $(u、Σ、π)$。
高斯混合模型 EM 算法流程

P98 K - 均值算法在图像压缩方面的应用 05:16
P99 高斯混合模型在说话人识别方面的应用 23:49
Speaker Recognition,说话人识别,又称为 声纹识别 ,就是通过语音语调判断说话人识别,跟人脸识别一样。
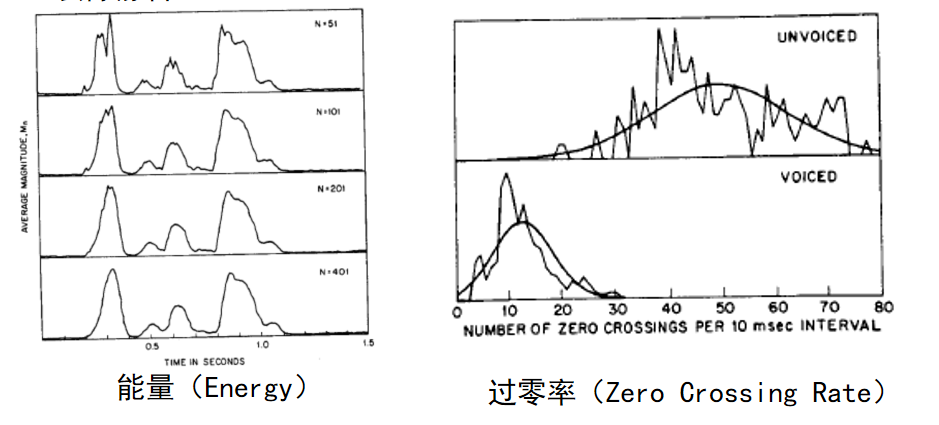
去除静音
提取的特征:MEL 倒谱系数 (Mel-frequency Cepstrum Coefficients, MFCC)
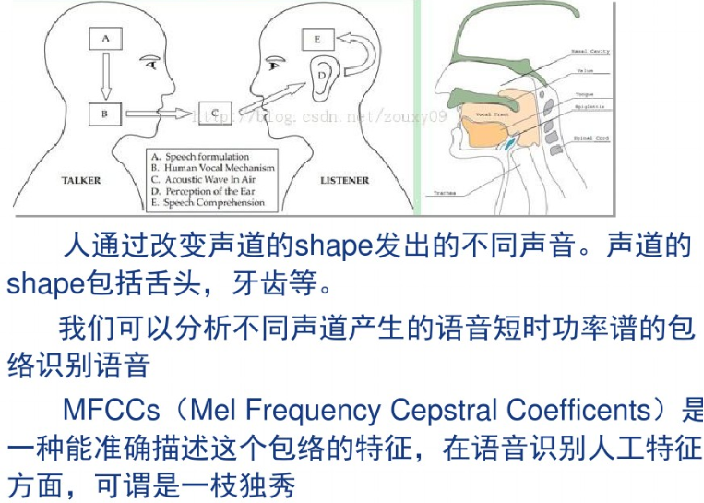
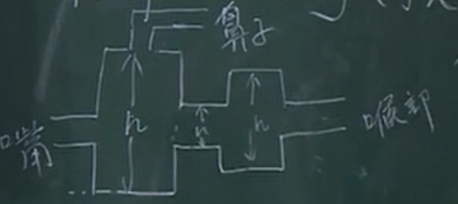
把声音反推回声道模型,计算出管子不同部位的高和宽。以物理方式做的特征,基本上能保证很高的识别率:
P100 EM 算法(收敛性证明) 39:24
EM 算法缺点 EM 算法是求局部极值的算法,和其他求局部极值的方法一样,它的缺点也是结果和初始值选取有关。
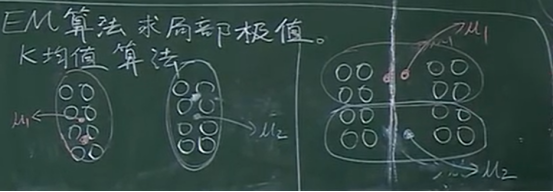
可以看出左侧比右侧的平方和要小,但是没法从右侧收敛到左侧。
P101 语音识别概述 07:27
连续行为的识别。
P102 隐含马尔可夫过程 1:29:00
一个 HMM 是由三部分组成: $λ=(A,B,Π)$
Viterbi-Algorithm(维特比算法) 维特比算法是一个特殊但应用最广的动态规划算法。 利用动态规划,可以解决任何一个图中的最短路径问题。 而维特比算法是针对一个特殊的图-篱笆网了(Lattice)的有向图最短路径问题而提出来的。 它之所以重要,是因为凡是使用隐马尔可夫模型描述的问题都可以用它解码, 包括当前的数字通信、语音识别、机器翻译、拼音转汉字、分词等。
P103 大词汇量连续语音识别介绍 35:15
汉语中 Triphone 个数:音节内 270 多个,音节间 3800 多个这是包含声调后的结果。 这就意味着,汉语构造声学模型比英语更容易。
DNN-HMM 与 GMM-HMM 对比: 假设输入语音为 ${x_1,x_2,…,x_T}$,且 HMM 有 N 个状态
- GMM-HMM (Gaussian Mixture Models-HiddenMarkov Models) 是用 GMM 来模拟观测似然 / 概率密度 $p(x_t|s_i)$,其中 $i=1,2,…,N$。
- DNN-HMM (Deep Neural Networks-Hidden MarkovModels) 通常用 DNN 估计后验概率 $p(s_i|x_t)$,再结合先验转换为 HMM 解码所需的似然信息,其中 $i=1,2,…,N$。
参考书和论文
- L. Rabiner and B.H. Juang, Fundamentals of Speech Recognition, Prentice-HallInternational , 1997.
- Dong Yu and Li Deng, Automatic Speech Recognition: A Deep Learning ApproachSpringer, 2014.
- D. Jurafsky and J. H. Martin, Speech and Language Processing: An introduction to naturaanguage processing, 2006.
- L. Rabiner, A Tutorial on Hidden Markov Models and Selected Applications in SpeechRecognition, Proceedings of the IEEE. 1-30.1989
工具包
- HTK Speech Recognition Toolkit, http://htk.eng.cam.ac.uk/
- CMU Sphinx, https://cmusphinx.github.io/
- Kaldi, https://github.com/kaldi-asr/kaldi.git
P104 循环神经网络(RNN)和 LSTM 39:42
若 w 为三层神经网络,且状态数有限,则 RNN 可以模拟 GMM-HMM。
P105 人工智能中的哲学 缸中之脑 09:05
P106 人工智能中的哲学 意识问题 13:04
意识分级
- 0 级:有生命无意识(植物)
- 1 级:各种感官信号(视觉、听觉、触觉、嗅觉、味觉),能感知周围环境,有时间感和空间感(爬行动物)(脑干)
- 2 级:作、社会关系,从社会关系中获得大于单个个体的力量(一些哺乳动物)(边缘系统)
- 3 级:模拟、预测未来(人类)(前额叶皮层)
P107 人工智能中的哲学 图灵测试 04:17
P108 人工智能中的哲学 世界是否有规律 05:38
P109 人工智能中的哲学 中文屋子假想试验 07:03
P110 人工智能中的哲学 创造力和洞穴理论 14:00
P111 人工智能中的哲学 - 生成对抗网络 15:41
P112 人工智能中的哲学 - 道德难题 09:37
高数,线性代数,概率论,Python 入门
美国 关于 色情 ,一直没有标准,直到 社区标准的出现。
P113 人工智能中的哲学未来展望 04:58
参考资料快照
- https://www.bilibili.com/video/BV1qf4y1x7kB/
- https://blog.csdn.net/weixin_41929524/article/details/112253138
- https://github.com/microsoft/ai-edu
- https://microsoft.github.io/ai-edu/%E5%9F%BA%E7%A1%80%E6%95%99%E7%A8%8B/index.html
- https://blog.csdn.net/DIPDWC/article/details/116211434
- https://blog.csdn.net/DIPDWC/article/details/116296128
- https://blog.csdn.net/DIPDWC/article/details/116397792
- https://blog.csdn.net/DIPDWC/article/details/116421523
- https://blog.csdn.net/DIPDWC/article/details/116425740
- https://blog.csdn.net/DIPDWC/article/details/116598683
- https://blog.csdn.net/DIPDWC/article/details/116834512
- https://blog.csdn.net/DIPDWC/article/details/116975301
- https://blog.csdn.net/DIPDWC/article/details/117029586
- https://blog.csdn.net/DIPDWC/article/details/117110173
- https://blog.csdn.net/DIPDWC/article/details/117215115
- https://blog.csdn.net/DIPDWC/article/details/117224855
- https://blog.csdn.net/DIPDWC/article/details/117249500
- https://blog.csdn.net/DIPDWC/article/details/117352728
- https://blog.csdn.net/DIPDWC/article/details/117395160
- https://blog.csdn.net/DIPDWC/article/details/112686489
- https://blog.csdn.net/DIPDWC/article/details/117410176
- https://blog.csdn.net/DIPDWC/article/details/117436454
- https://blog.csdn.net/DIPDWC/article/details/118002621
- https://blog.csdn.net/DIPDWC/article/details/118329517
- http://counting.movingshop.cn
- https://github.com/ahmetozlu/tensorflow_object_counting_api
- https://github.com/Roujack/mathAI
- https://neurosys.com/blog/objects-counting-by-estimating-a-density-map
- https://analyticsindiamag.com/computer-vision-researchers-are-using-blobs-to-count-objects/
- https://haoji007.blog.csdn.net/article/details/76782606
- https://blog.csdn.net/qq_45654306/article/details/113806590
- https://zhuanlan.zhihu.com/p/81255623
- https://www.coursera.org/course/ml
- https://cs231n.Stanford.edu
- https://cloud.tencent.com/developer/article/1888046
- https://cloud.tencent.com/developer/article/1888060
- https://cloud.tencent.com/developer/article/1888043
- https://www.bilibili.com/video/BV1HU4y127kn/
- http://htk.eng.cam.ac.uk/
- https://cmusphinx.github.io/
- https://github.com/kaldi-asr/kaldi.git
- https://www.a.tools/Tool.php?Id=469
- 机器学习 -- 大型语言模型简史:从 Transformers (2017) 到 DeepSeek-R1 (2025) | 20 Feb 2025
- 机器学习 -- DALL·E 2 & 扩散模型 | 21 Dec 2024
- 机器学习 -- 学术论文解读系列(进行中) | 04 Oct 2024
- 机器学习 -- 经典论文 ViT (Vision Transformer) | 24 Jul 2024
- 机器学习 -- 跟李沐学 AI【论文精读】(进行中) | 09 Jul 2024
- 机器学习 -- Attention is all you need | 30 Jun 2024
- 机器学习笔记 -- 3Blue1Brown 深度学习 Deep Learning(已完成) | 29 Jun 2024
- 机器学习 -- 李宏毅 2021/2022 春机器学习课程(进行中) | 31 Aug 2023
- 机器学习 -- 实用机器学习 李沐(进行中) | 31 Aug 2023
- 机器学习 -- ChatGPT Prompt 提示词 吴恩达(进行中) | 28 Jul 2023
- 机器学习 -- 浙江大学 · 机器学习(已完成) | 12 Feb 2023
- 机器学习 -- 人工智能学习路线(进行中……) | 10 Feb 2023
- 机器学习 -- 北交 · 图像处理与机器学习(已完成) | 03 Dec 2022
- 机器学习笔记 -- 人工智能 机器学习 算法概览(已完成) | 13 Oct 2022
- 机器学习笔记 -- 神经网络内部发生了什么?深度学习可视化 | 13 Oct 2022
- 机器学习 -- 吴恩达机器学习 Review(已完成) | 31 Aug 2022
- 机器学习 -- 吴恩达深度学习(进行中) | 31 Aug 2022
- 机器学习 -- 吴恩达机器学习(已完成) | 31 Aug 2022
- 机器学习笔记 -- 神经网络和深度学习简史 | 26 Dec 2020
 .
.