机器学习 -- 大型语言模型简史:从 Transformers (2017) 到 DeepSeek-R1 (2025)
大型语言模型简史:从 Transformers (2017) 到 DeepSeek-R1(2025) AI 发展太快了,以至于我们称:几个月前的技术为古代,2022 年 ChatGPT 诞生前是上古时代,BERT 之前是史前时代,Transformer 之前则是旧石器时代。 系统化知识传授(监督学习),实践探索(强化学习),监督学习只能从冗余的信息里面学习到知识,强化学习才是人工智能的未来。
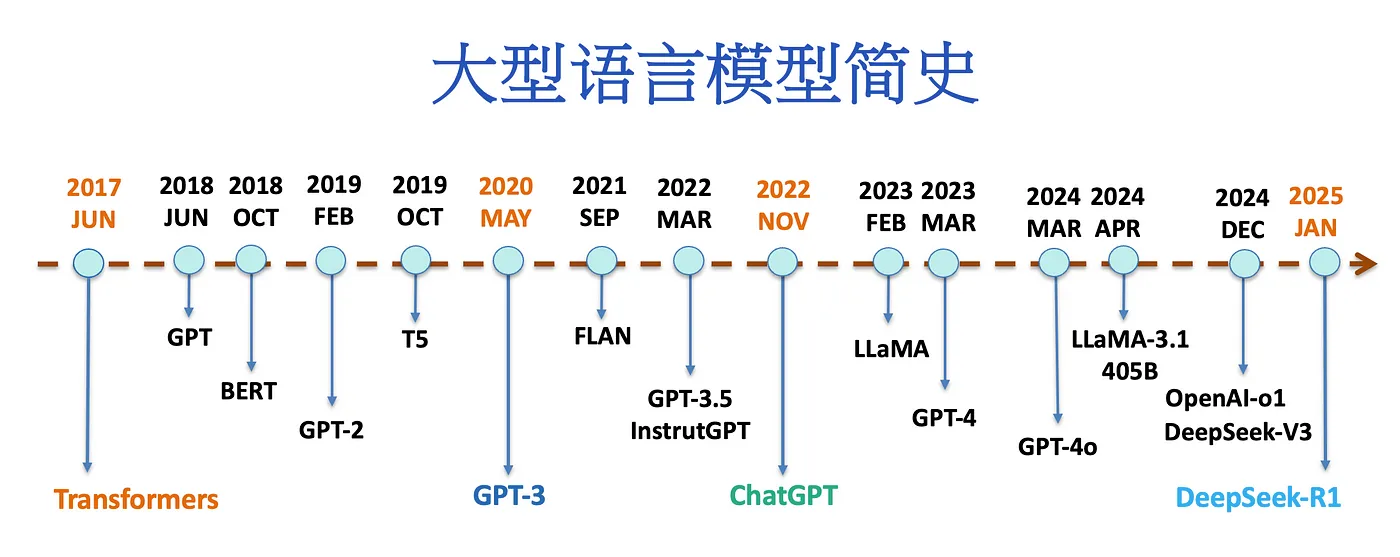
GRPO 人工智能的每次发展,基本原理感觉都很简单,那些完成严格数学表达,完整代码实现的人,应该都是天才。 在尝试了大量可能后,找到了那条最优美的路。简洁的像诗歌,璀璨如星辰。 每当深夜阅读这些文章,总会令人惊叹与震撼,感受那纯粹的美妙。高雅又优雅! 不管什么奇奇怪怪的模型结构,不管多少维度的 Tensor 都能算梯度,并完成正向反向传播。 这些极度聪明的人推动了人工智能的发展。而我,不够聪明,无法参与其中。
杨立昆坚持认为现在的 LLM 路线是错误的,基本到头了,下一代架构是模仿婴儿建立世界模型 AMI。 难度在于怎么完成梯度反向传播,怎么完成多个子系统的对齐。 那些复杂的生物行为,都和语言无关,它肯定不会是在 token 空间里完成的,而是在心智空间当中。 目前 LLM 有点像是在边边角角上做改进,想办法搞更多数据,更多算力,或者搞点合成数据什么的。
抖音算法公开了。基于特征向量的数学统计。 算法会围绕用户的反馈建模,有没有点赞、看到了第几秒、写了什么评论、是否点开了作者主页……等等, 这些互动都会让算法对一个用户的了解逐渐加深,最终越来越准确的「预测」他会感兴趣的下一条视频。
- GPT-1 的论文题目是 Improving Language Understanding by Generative Pre-Training,旨在论证语言模型的发展应该朝着生成式预训练这个方向发展;
- GPT-2 的论文题目是 Language models are unsupervised multitask learners,旨在论证语言模型的学习应该仅依赖于无监督的学习过程;
- GPT-3 的论文题目是 Language models are few-shot learners,旨在论证语言模型可以像人一样通过简单的样例来学习每个下游任务的行为模式,而这也是我们人类解决问题的方式;
- InstructGPT 的论文题目是 Training language models to follow instructions with human feedback,旨在论证整个语言模型的训练流程范式。
交叉熵、信息熵、相对熵、KL 散度
Amount of Information for an event:
- small probability –> large amount of information
- large probability –> small amount of information
- amount of information of independent events can be summed
for a probability distribution:
- pdf more uniform –> more random –> larger entropy
- pdf more condensed –> more certain –> smaller entropy
KL 散度(也叫相对熵)公式:
\[D_{K L}(p \| q)=\sum_{i=1}^n p\left(x_i\right) \log \left(\frac{p\left(x_i\right)}{q\left(x_i\right)}\right)\]交叉熵 交叉熵主要应用:主要用于度量同一个随机变量 $X$ 的预测分布 $Q$ 与真实分布 $P$ 之间的差距。 差距可理解为:距离、误差、失望值、困难程度、混乱程度、一辆车、一套房。
\[\begin{aligned} & H(P, Q)=-\sum_{i=1}^n p\left(x_i\right) \log q\left(x_i\right) \\ & H(P, Q)=\sum_x p(x) \cdot \log \left(\frac{1}{q(x)}\right) \end{aligned}\]CrossEntropyLoss
\[\operatorname{loss}(x, \operatorname{class})=-\log \left(\frac{\exp (x[\operatorname{class}])}{\sum_j \exp (x[j])}\right)=-x[\operatorname{class}]+\log \left(\sum_j \exp (x[j])\right)\]程序算交叉熵:
entroy = nn.CrossEntropyLoss()
input = torch.Tensor([[-0.7715, -0.6205, -0.2562]])
target = torch.tensor([0])
output = entroy(input, target) # 打印输出:1.3447
为什么在很多的网络模型中,使用交叉熵做损失函数而不使用 KL 散度做损失函数呢?
- \(D_{KL}(P\|Q)=H(P,Q)-H(P)\),其中 \(H(P)\) 与模型参数无关,所以优化交叉熵等价于优化 KL 散度。
- 对普通分类任务的 one-hot 标签,\(H(P)=0\),交叉熵数值上等于 KL 散度;如果是软标签或两个完整分布之间的约束,再直接写 KL 散度会更清楚。
GRPO(Group Relative Policy Optimization)
DeepSeek-R1 GRPO 算法揭秘 https://www.bilibili.com/video/BV15zNyeXEVP/
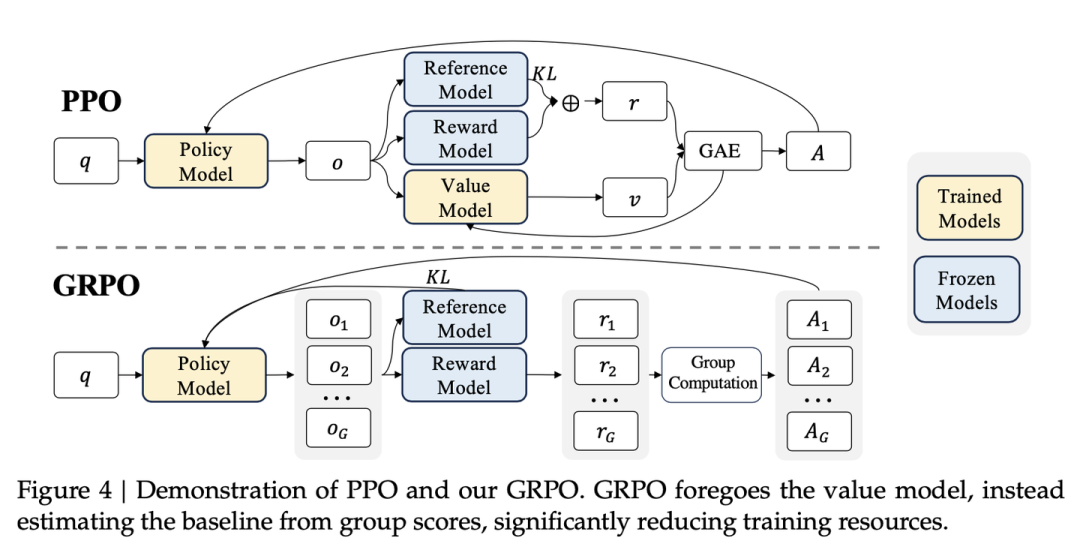
https://blog.csdn.net/v_JULY_v/article/details/136656918
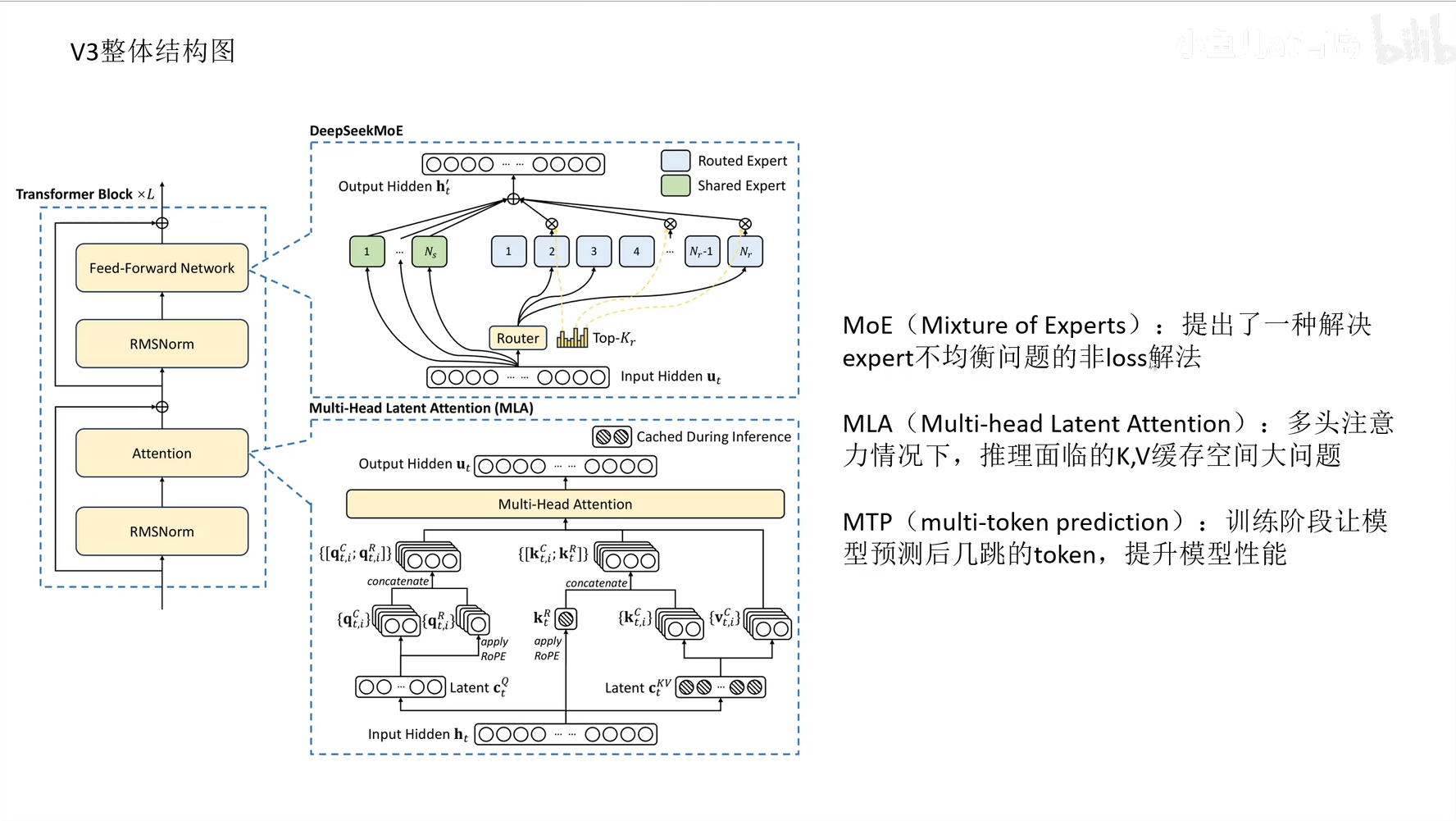
DeepSeek V3 & R1
https://space.bilibili.com/288748846
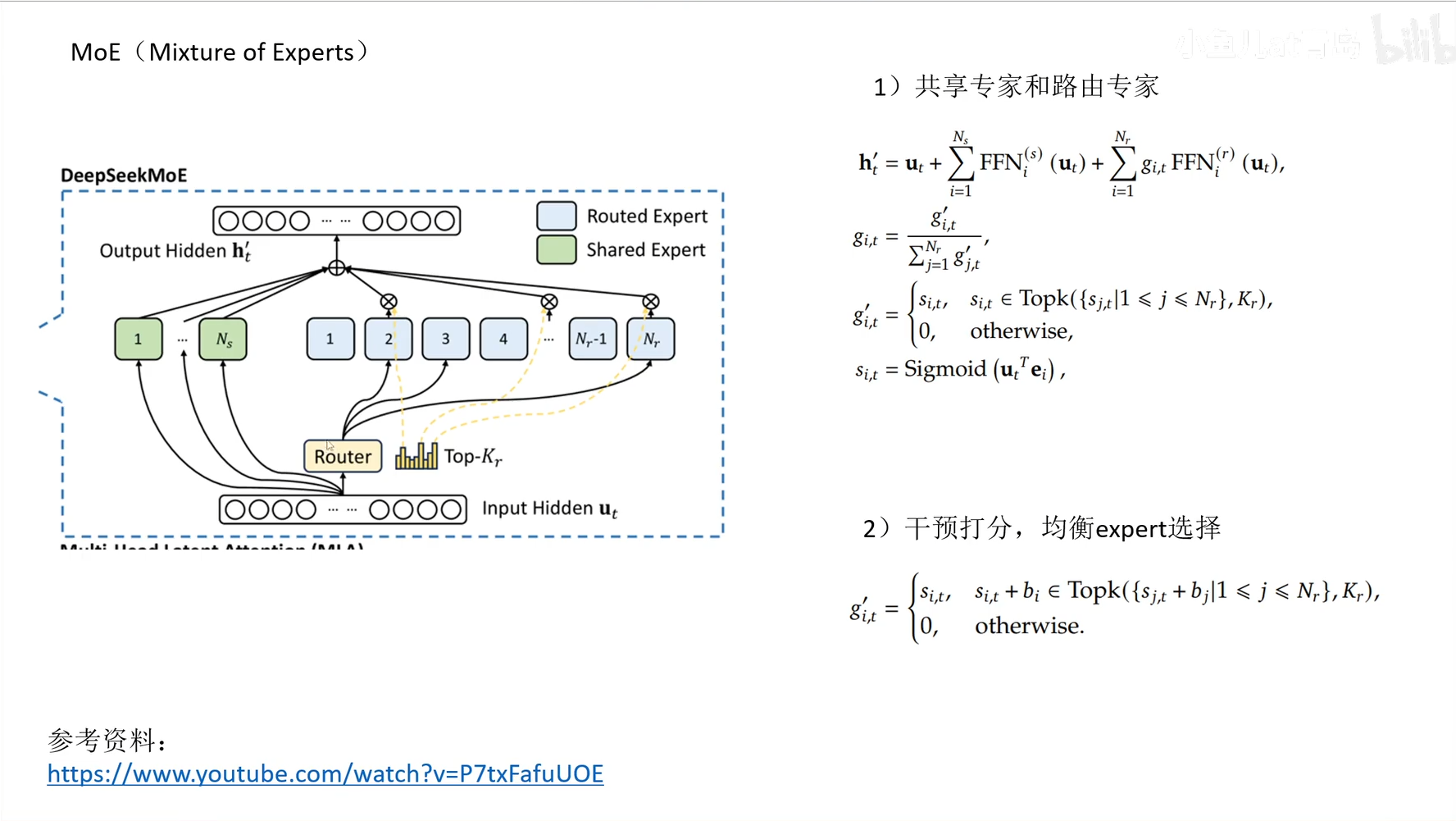
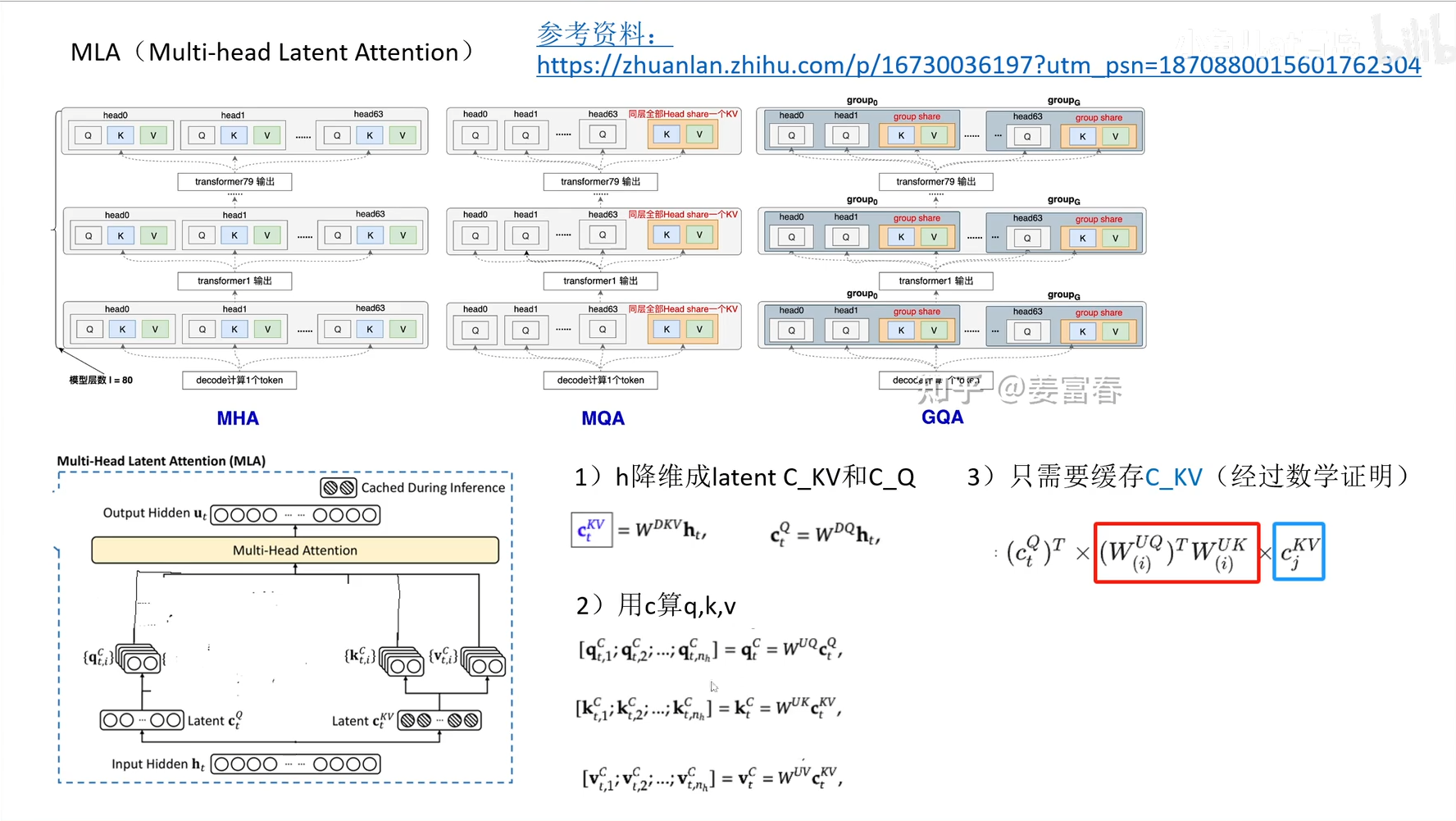
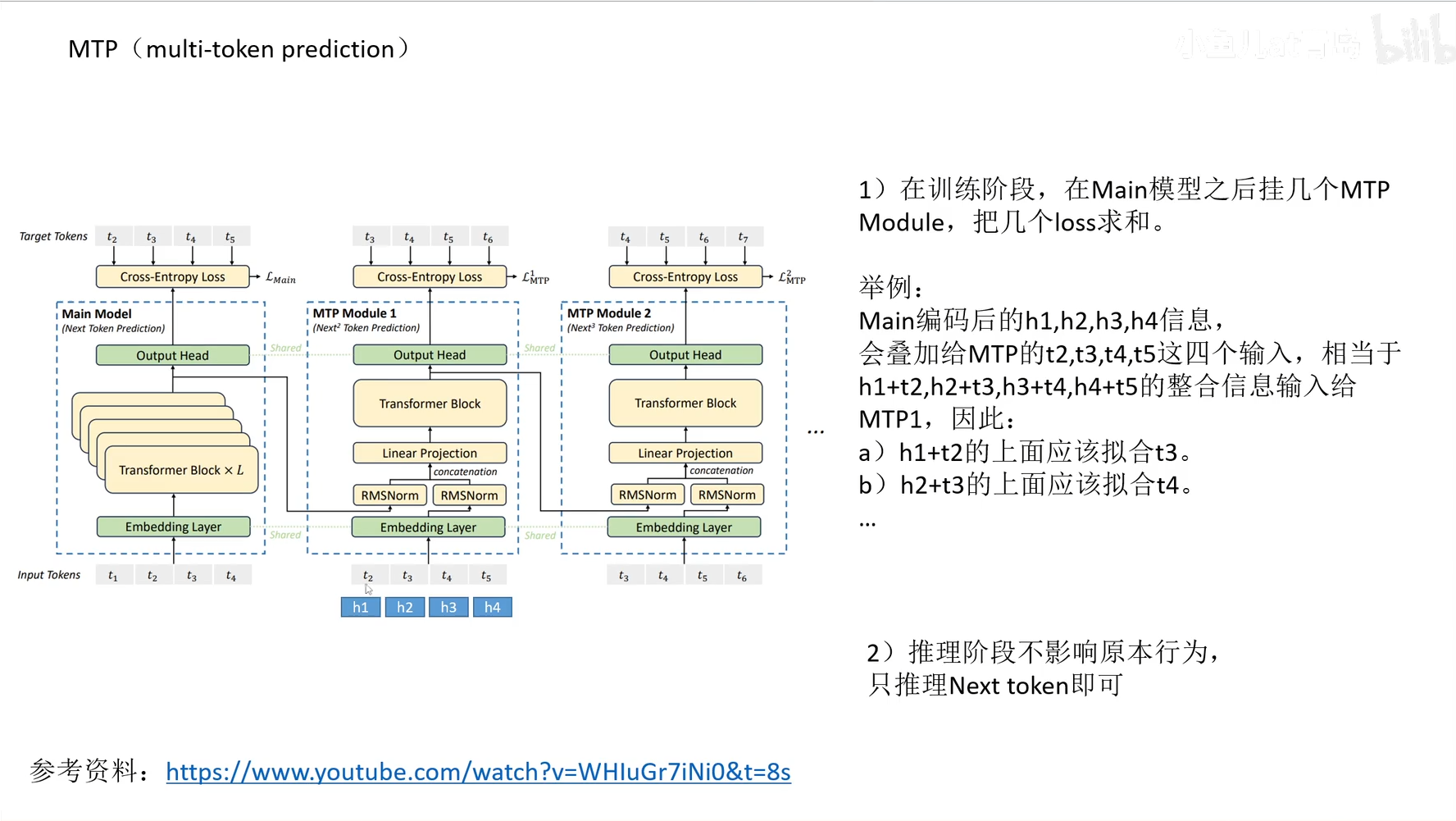
- DeepSeek V3 模型架构创新点
- MoE(Mixture of Experts): 提出了一种解决 expert 不均衡问题的非 loss 解法
- MLA(Multi-head Latent Attention): 多头注意力情况下,推理面临的 K,V 缓存空间大问题
- MTP(multi-token prediction): 训练阶段让模型预测后几跳的 token,提升模型性能
- DeepSeek-R1 GRPO 算法揭秘
下面是 GRPO 的简化笔记;完整目标函数通常还包含 PPO-style 的 clip ratio 项,不能把它理解成只使用未裁剪的概率比值。
\[\begin{aligned} & \hat{A}_{i, t}=\frac{r_i-\operatorname{mean}(\mathbf{r})}{\operatorname{std}(\mathbf{r})} \\ & \mathbb{D}_{\mathrm{KL}}\left[\pi_\theta \| \pi_{\mathrm{ref}}\right]=\frac{\pi_{\mathrm{ref}}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_\theta\left(o_{i, t} \mid q, o_{i,<t}\right)}-\log \frac{\pi_{\mathrm{ref}}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_\theta\left(o_{i, t} \mid q, o_{i,<t}\right)}-1 \\ & \mathcal{L}_{\mathrm{GRPO}}(\theta)=-\frac{1}{G} \sum_{i=1}^G \frac{1}{\left|o_i\right|} \sum_{t=1}^{\left|o_i\right|}\left[\frac{\pi_\theta\left(o_{i, t} \mid q, o_{i,<t}\right)}{\left[\pi_\theta\left(o_{i, t} \mid q, o_{i,<t}\right)\right]_{\mathrm{no} \text { grad }}} \hat{A}_{i, t}-\beta \mathbb{D}_{\mathrm{KL}}\left[\pi_\theta \| \pi_{\mathrm{ref}}\right]\right. \end{aligned}\]- Ref 是原版冻结住的 LLM,存在的目的是:无论 Policy 怎么训练,都不能和 Ref 的 next token prob 偏离太夸张(KL 散度)
- 同一组答案 RL 会拿来 train N 次,会把 train 之前 policy 的 next token prob 记下来作为基准。 在每次 train 后 policy 会更新,下次出的 next token prob 除以基准,就形成了给 adv 加权效果,好的 adv 得到放大。
https://huggingface.co/docs/trl/main/en/grpo_trainer
DeepSeek-R1 GRPO 原理 .pptx  单卡 20G 显存,复现 DeepSeek R1 顿悟时刻
单卡 20G 显存,复现 DeepSeek R1 顿悟时刻
生成模型综述
马尔可夫链清楚解释
https://www.bilibili.com/video/BV1XYRJYWE6A
- Markov Chains Clearly Explained! Part - 1
- Markov Chains: Recurrence, Irreducibility, Classes | Part - 2
-
Markov Chains: n-step Transition Matrix | Part - 3
- 动画讲解马尔可夫链(一):基本概念

- 动画讲解马尔可夫链(二):马尔可夫链的属性
- 动画讲解马尔可夫链(三):高阶转移矩阵与稳态的关系
- 动画讲解马尔可夫链(四):生成福尔摩斯探案集
- 动画讲解马尔可夫链(五):隐马尔可夫模型
- 动画讲解马尔可夫链(六):前向算法
回收这块,SpaceX 也就一乐,真回收还得是转转。
低代码编程全军覆没。 低代码的本意是想让不懂编程的人,像搭乐高积木那样建造自己的屋子。但现实中的楼房需要完备的设计图纸和专业的施工人员,只靠积木是搭不了几层的。实践证明,代码就是人机逻辑交互最好的语言。 这个世界是为人类设计的,所以人形机器人才是现阶段的最优解;电脑也是为人类设计的,像人一样使用电脑,才是现阶段 AI 的最优解。
端到端是大势所趋。 早期的自动驾驶采用流水线式的 workflow(pipeline)架构,后来逐步演变为端到端。如今,Agent 也面临类似的问题,并将经历相同的演进,实现端到端的降维打击。人类预设的 workflow 对于模型而言,更像是一种束缚,只有让其自由发挥,才能展现更强大的能力。 模型即应用,这一趋势愈发明显。 监督学习和半监督学习都受到人类知识的约束,只有强化学习才是未来,AI 自己去找规律。
杨立昆坚持认为现在的 LLM 路线是错误的,基本到头了,下一代架构是模仿婴儿建立世界模型 AMI。难度在于怎么完成梯度反向传播,怎么完成多个子系统的对齐。
“为什么医生养孩子都比较佛系,老师养孩子却比较严厉?” “因为老师见过最优秀的孩子,而医生见过最后悔的家长。” 我把这个观点和主任说了,主任说,“一开始我也是这样想的,只要孩子开心快乐就好了,后来五年级六年级,成绩垫底,慌得不行!还是得拼一下。”
好美想拉屎 这种地方最适合拉屎了 微凉的风吹拂着屁股,草叶轻刮着你的肌肤,远方的小路随时可能有人走来,亮而圆的太阳为这次冒险增加几分心安。 在这光的照射下有了便意,于是躲进草地里畅快的拉起野屎来。
具身智能(Embodied AI)
- 具身智能(Embodied AI):通过物理 / 虚拟身体(机器人、传感器、仿真环境)与真实世界交互,生成“第一手感知经验”(如触觉、力觉),补足语言仅靠“二手描述”的感知盲区。
- 让模型与真实世界交互(机器人、传感器、虚拟环境),补足语言的盲区。
- 混合推理系统(Neuro-Symbolic AI):融合大模型的模式识别能力与符号逻辑的精确推理(如知识图谱、数学规则),使 AI 从“会说话”升级为“会因果思考”。
- 结合大模型的模式识别能力 + 符号推理的精确逻辑,让 AI 不只是“会说”,而是真的“会想”。
- 终身学习(Continual Learning):让模型持续通过新交互(对话、任务、数据)更新知识,避免“静态冻结”,形成动态演化的“个性化世界模型”。
- 让模型不只是离线训练后冻结,而是长期更新、记忆、适应,形成个性化世界模型。
- 统一世界模型(World Model):整合多模态(语言、视觉、触觉)与推理能力,构建“世界模拟器”,直接预测现实演化(如“推桌子→杯子掉落”),实现多模态与逻辑的统一表征。
- 不只理解语言,而是学会预测现实世界的演化,像 DeepMind 的 Gato、Google 的 Gemini Ultra 的设想一样,把多模态和推理整合到一个统一空间。
参考资料快照
- https://medium.com/@lmpo/%E5%A4%A7%E5%9E%8B%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%E7%AE%80%E5%8F%B2-%E4%BB%8Etransformer-2017-%E5%88%B0deepseek-r1-2025-cc54d658fb43
- https://www.bilibili.com/video/BV1JY411q72n/
- https://www.bilibili.com/video/BV15zNyeXEVP/
- https://blog.csdn.net/v_JULY_v/article/details/136656918
- https://space.bilibili.com/288748846
- https://huggingface.co/docs/trl/main/en/grpo_trainer
- https://github.com/owenliang/qwen2.5-0.5b-grpo
- https://www.bilibili.com/video/BV1AW9QYoEoo/
- https://www.bilibili.com/video/BV1XYRJYWE6A
- https://www.bilibili.com/video/BV1ih4y1W7i7/
- https://www.bilibili.com/video/BV1go4y1h7s8
- https://www.bilibili.com/video/BV14o4y1h7me
- https://www.bilibili.com/video/BV12m4y1C7qv
- https://www.bilibili.com/video/BV19a4y1P7Tc
- https://www.bilibili.com/video/BV1yX4y127ub
- 机器学习 -- 大型语言模型简史:从 Transformers (2017) 到 DeepSeek-R1 (2025) | 20 Feb 2025
- 机器学习 -- DALL·E 2 & 扩散模型 | 21 Dec 2024
- 机器学习 -- 学术论文解读系列(进行中) | 04 Oct 2024
- 机器学习 -- 经典论文 ViT (Vision Transformer) | 24 Jul 2024
- 机器学习 -- 跟李沐学 AI【论文精读】(进行中) | 09 Jul 2024
- 机器学习 -- Attention is all you need | 30 Jun 2024
- 机器学习笔记 -- 3Blue1Brown 深度学习 Deep Learning(已完成) | 29 Jun 2024
- 机器学习 -- 李宏毅 2021/2022 春机器学习课程(进行中) | 31 Aug 2023
- 机器学习 -- 实用机器学习 李沐(进行中) | 31 Aug 2023
- 机器学习 -- ChatGPT Prompt 提示词 吴恩达(进行中) | 28 Jul 2023
- 机器学习 -- 浙江大学 · 机器学习(已完成) | 12 Feb 2023
- 机器学习 -- 人工智能学习路线(进行中……) | 10 Feb 2023
- 机器学习 -- 北交 · 图像处理与机器学习(已完成) | 03 Dec 2022
- 机器学习笔记 -- 人工智能 机器学习 算法概览(已完成) | 13 Oct 2022
- 机器学习笔记 -- 神经网络内部发生了什么?深度学习可视化 | 13 Oct 2022
- 机器学习 -- 吴恩达机器学习 Review(已完成) | 31 Aug 2022
- 机器学习 -- 吴恩达深度学习(进行中) | 31 Aug 2022
- 机器学习 -- 吴恩达机器学习(已完成) | 31 Aug 2022
- 机器学习笔记 -- 神经网络和深度学习简史 | 26 Dec 2020
 .
.