机器学习 -- 吴恩达机器学习 Review(已完成)
- 吴恩达机器学习 19:37:16 142 https://www.bilibili.com/video/BV1Bq421A74G/
- 吴恩达深度学习 27:44:07 183 https://www.bilibili.com/video/BV1FT4y1E74V/
- html2text
机器学习早期版本(岁月觞):吴恩达机器学习系列课程 
吴恩达机器学习
1 1.1 欢迎来到机器学习 ! 02:45
2 1.2 机器学习的应用 04:29
3 2.1 什么是机器学习 05:36
4 2.2 监督学习 part 1 06:57
5 2.3 监督学习 part 2 07:17
6 2.4 非监督学习 part 1 08:54
7 2.5 非监督学习 part 2 03:40
8 2.6 Jupyter Notebooks 04:30
9 3.1 线性回归模型 part 1 10:27
10 3.2 线性回归模型 part 2 06:45
11 3.3 代价函数 09:05
\[J(w, b)=\frac{1}{2 m} \sum_{i=1}^m\binom{\hat{y}^{(i)}-y^{(i)}}{\text { error }}^2\]12 3.4 代价函数的直观理解 15:47
13 3.5 可视化代价函数 08:34
14 3.6 可视化的例子 06:01
15 4.1 梯度下降 08:04
16 4.2 实现梯度下降 10:00
17 4.3 梯度下降的直观理解 07:02
18 4.4 学习率 09:04
19 4.5 线性回归中的梯度下降 06:37
20 4.6 运行梯度下降 05:49
21 5.1 多类特征 09:52
22 5.2 向量化 part 1 06:55
23 5.3 向量化 part 2 06:53
24 5.4 多元线性回归的梯度下降法 07:47
25 6.1 特征缩放 part 1 06:36
26 6.2 特征缩放 part 2 07:35
27 6.3 检查梯度下降是否收敛 05:40
28 6.4 学习率的选择 06:07
29 6.5 特征工程 03:05
30 6.6 多项式回归 05:53
31 7.1 Motivations 09:48
32 7.2 逻辑 (logistic) 回归 09:49
33 7.3 决策边界 10:43
34 8.1 逻辑回归的代价函数 12:00
\[\begin{aligned} & J(\overrightarrow{\mathrm{w}}, b)=\frac{1}{m} \sum_{i=1}^m \underbrace{L\left(f_{\overrightarrow{\mathrm{w}}, b}\left(\overrightarrow{\mathrm{x}}^{(i)}\right), y^{(i)}\right)}_{\operatorname{loss}} \\ & \rightarrow=\left\{\begin{aligned} -\log \left(f_{\overrightarrow{\mathrm{w}}, b}\left(\overrightarrow{\mathrm{x}}^{(i)}\right)\right) & \text { if } y^{(i)}=1 \\ -\log \left(1-f_{\overrightarrow{\mathrm{w}}, b}\left(\overrightarrow{\mathrm{x}}^{(i)}\right)\right) & \text { if } y^{(i)}=0 \end{aligned}\right. \end{aligned}\]变化一下,转成 凸函数(convex function)。
35 8.2 逻辑回归的简化版代价函数 05:46
\[L\left(f_{\bar{w}, b}\left(\mathrm{x}^{(i)}\right), y^{(i)}\right)=-y^{(i)} \log \left(f_{\bar{w}, b}\left(\vec{x}^{(i)}\right)\right)-\left(1-y^{(i)}\right) \log \left(1-f_{\bar{w}, b}\left(\vec{x}^{(i)}\right)\right)\]36 9.1 梯度下降实现 06:32
37 10.1 过拟合的问题 11:53
38 10.2 解决过拟合 08:16
39 10.3 正则化代价函数 09:04

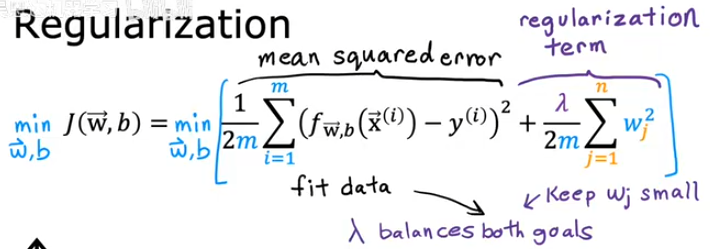
越高阶的,参数越大,平衡后,更趋向于低阶,从而达到正则化的目的。
40 10.4 正则化线性回归 08:53
41 10.5 正则化 logistic 回归 05:33
42 1.1 欢迎来到第二部分 _ 高级学习算法 02:54
43 1.2 神经元和大脑 10:53
44 1.3 需求预测 16:24
45 1.4 例子:图像识别 06:36
46 2.1 神经网络中的层 09:50
47 2.2 更复杂的神经网络 07:19
48 2.3 推理:做出预测(前向传播) 05:24
49 3.1 代码中的推理 07:13
50 3.2 TensorFlow 中的数据 11:20
51 3.3 构建一个神经网络 08:21
52 4.1 在一个单层中的前向传播 05:07
53 4.2 前向传播的一般实现 07:53
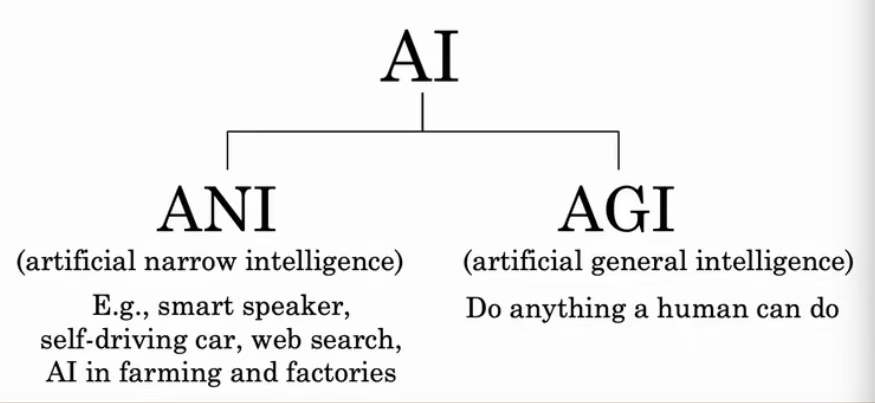
54 5.1 是否有路通向 AGI(通用人工智能) 10:35
看了吴恩达和李飞飞的采访,目前的人工智能距离 AGI 还存在无法逾越的鸿沟。人类目前对大脑的工作原理不得而知,大脑的每个神经元是一个活体细胞,而大模型的每个神经元还是很简陋的函数。宇宙为什么会诞生生命?意识来源是啥?不得而知。
55 6.1 神经网络如何高效实现 04:23
56 6.2 矩阵乘法 09:28
57 6.3 矩阵乘法的规则 09:33
58 6.4 矩阵乘法代码 06:42
59 7.1 TensorFlow 实现 03:38
60 7.2 训练细节 13:41
It's still useful to understand how they work under the hood. So that if something unexpected happends, You have a better chance of knowing how to fix it.
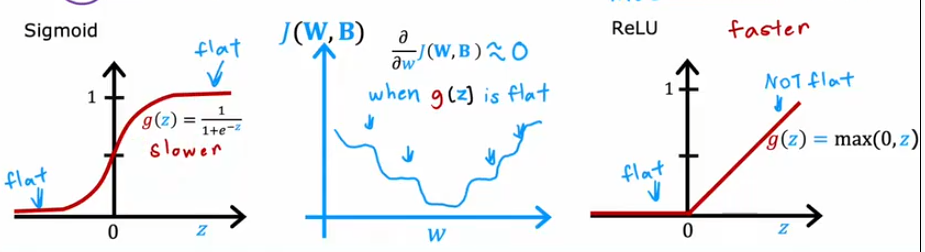
61 8.1 sigmoid 的替代品 05:30
ReLU: rectified linear unit.
62 8.2 选择激活函数 08:25
The relu function kind of goes flat only in one part of the graph, Whereas the sigmoid activation function, It kind of goes flat in two places.
And if you're using gradient descent to train a neural network, Then when you have a function that is flat in a lot of places, Gradient descent will be really slow.
63 8.3 为什么我们需要激活函数 05:32
64 9.1 多类 03:29
65 9.2 Softmax 11:33
66 9.3 神经网络的 Softmax 输出 07:25
67 9.4 softmax 的改进实现 09:13
相当于是为了计算更精确,所以把 softmax 函数运算放到了损失函数里面,而此时模型预测出来的值不再是概率, 必须再经过 softmax 函数还原成预测概率。
68 9.5 多个输出的分类 (Optional) 04:20
69 10.1 高级优化方法 06:26
每个维度一个学习率,自动调整。 Adam Algorithm Intuition
Adam: Adaptive Moment estimation
70 10.2 Additional Layer Types 08:56
71 11.1 决定下一步做什么 03:42
搞机器学习最重要的就是分配你的时间。 应该搞数据还是搞算法。
Diagnostic: A test that you run to gain insight into whatis/isn't working with a learning algorithm, to gain guidanceinto improving its performance.
Diagnostics can take time to implement but doing so can bea very good use of your time.
72 11.2 模型评估 10:26
- 70% / 80%
- 30% / 20%
73 11.3 模型选择和训练交叉验证测试集 14:53
- 60% 训练集 training set
- 20% 交叉验证集 cross validation
- 20% 测试集 test set
74 12.1 诊断偏差和方差 11:13
- Jtrain high, Jcv high
- Jtrain low, Jcv low
- Jtrain low, Jcv high

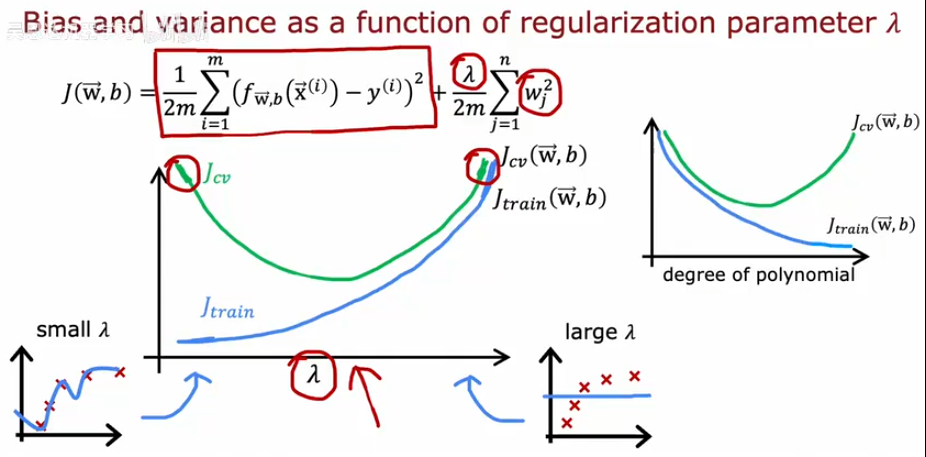
75 12.2 正则化和偏差或方差 10:37
76 12.3 建立表现基准 09:26

77 12.4 学习曲线 12:14

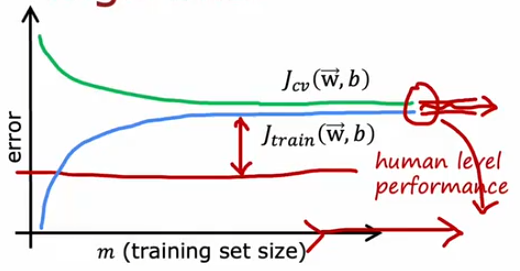
High bias
if a learning algorithm suffersfrom high bias, getting moretraining data will not (byitself) help much.
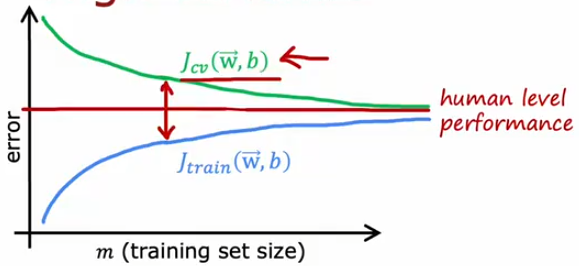
High variance
if a learning algorithm suffersfrom high variance, gettingmore training data is likely tohelp.
建立基线作为参考, 这里应该存在三种情况:
- 数据过少。
- 往往高方差。加强正则化。
- 模型过于简单。
- 往往高偏差。减弱正则化。
- 模型过于复杂。等价于数据过少。
sometimes, luck is essential
78 12.5 再次决定下一步做什么 08:47

一时学习,一生去理解。 大体是说,有一个博士生,偏差和方差一生去理解。 07:00 Andrew Ng: One of my phd students form stanford, Many years after he had already graduated from stanford, Once said to be that while he was studying at stanford, He learned about bias and variance, But he understood it, But that susequently, After many years of work experience and a few different companies, He realized that, Bias and variance is one of those concepts that takes a short time to learn, Beut it takes a lifetime to master.
Andrew Ng: “One of my PhD students from Stanford, many years after he had already graduated from Stanford, once said to me that while he was studying at Stanford, he learned about bias and variance. He understood it at the time, but subsequently, after many years of work experience at a few different companies, he realized that bias and variance are concepts that take a short time to learn, but a lifetime to master.”
79 12.6 偏差或方差与神经网络 10:45
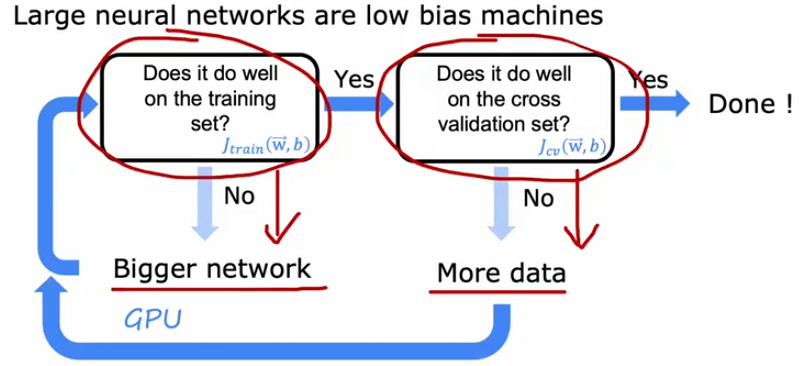
80 13.1 机器学习的迭代发展 07:43
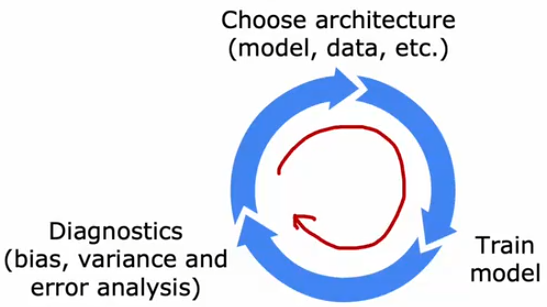
81 13.2 误差分析 08:21
看到 13.2 误差分析 00:24
82 13.3 添加数据 14:24
数据增强,随机噪声意义不大,因为这些情况在测试集里面不会出现。
用于照片 OCR 的人工数据合成 Artificial data synthesis for photo OCR
83 13.4 迁移学习:使用其他任务中的数据 12:11
84 13.5 机器学习项目的完整周期 08:45
traditional procedure of statistical study, machine learning <-> statistics
85 13.6 公平、偏见与伦理 09:57
86 14.1 倾斜数据集的误差指标 11:36

87 14.2 精确率与召回率的权衡 11:50
F1 score

88 15.1 决策树模型 07:06
89 15.2 学习过程 11:21
90 16.1 测量纯度 07:50
Entropy as a measure of impurity 熵作为杂质的度量

91 16.2 选择拆分信息增益 11:52
92 16.3 整合 09:29
水。
93 16.4 使用分类特征的一种独热编码 (One-Hot) 05:26
热编码 (One-Hot)
94 16.5 连续的有价值特征 06:55
95 16.6 回归树 (optional) 09:52
有点像贪心算法,不断的按照方差减少最多的选择持续分裂。
96 17.1 使用多个决策树 03:57
ensemble of trees 学习是一件很困难的事情,特别是那种纯英文的,稍不留意一走神,就不知道在讲啥了。 需要集中精力 ++。
97 17.2 放回抽样 04:00
98 17.3 随机森林算法 06:23
随机森林使用一种名为 Bagging 的技术,通过数据集的随机自助抽样样本并行构建多棵决策树。回归任务通常取各树预测的平均值,分类任务通常采用多数投票或平均类别概率。
整个过程有点像正则化的过程。 和 dropout 思想有相似性。
99 17.4 XGBoost 07:26
和残差网络有点像,把那些分类不好的重点关注重新分类。
eXtreme Gradient Boosting https://www.nvidia.cn/glossary/data-science/xgboost/
如何向 10 岁小孩解释 XGBoost 回归算法  极端梯度提升(XGBoost)的理论基础
极端梯度提升(XGBoost)的理论基础
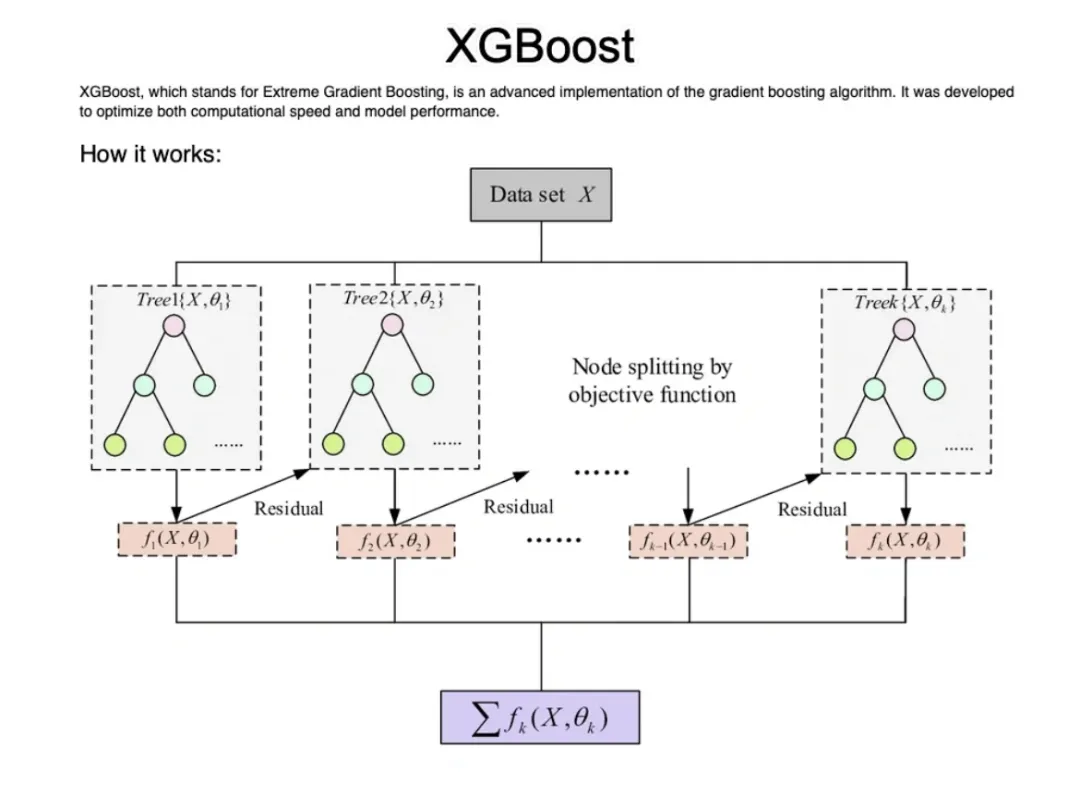
XGBoost 是一种提升树模型,即将许多树模型集成在一起形成一个很强的分类器。
算法思想是不断地添加树,不断地进行特征分裂生成一棵树,每次添加一棵树,就是学习一个新函数,去拟合上次预测的残差,当训练完成就得到了 k 棵树。
根据样本特征在每棵树中会落到对应的一个叶子节点,每个叶子节点对应的一个分数就是该样本的预测分数,将每棵树对应的分数加起来就是该样本的预测值。
XGBoost 工作原理:
- 初始模型:从一个简单的模型开始(比如一个只输出平均值的模型)。
- 计算残差:计算该简单模型的“残差”(即模型预测值与实际值之间的差异)。
- 训练新决策树模型:训练一个新的决策树模型来预测该残差,目标是尽量减小残差。
- 更新模型:把新决策树模型加入现有模型,使得新的模型可以更好地预测目标值。
- 重复步骤:重复上述过程,不断加入新的树,每次都使模型的预测更准确,直到达到预定的树的数量或者误差降到可以接受的范围。
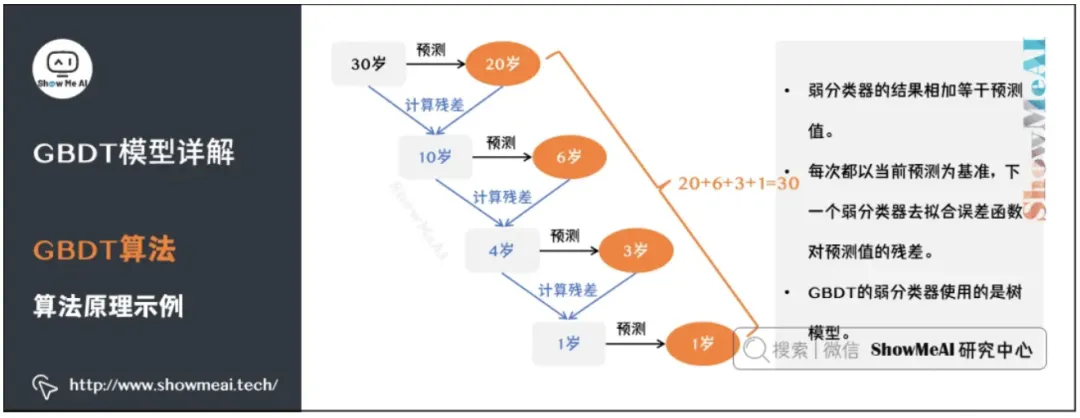
XGBoost 跟 ResNet 还有点像,不断计算模型的“残差”,相对模型的黑盒,这个更偏向于可解释的白盒。 每次都以当前预测为基准,下一个弱分类器去拟合误差函数对预测值的残差(预测值与真实值之间的误差)。 损失函数的泰勒展开:XGBoost 利用损失函数的二阶泰勒展开进行优化,提升计算效率。
100 17.5 什么时候使用决策树 06:55
Decision Trees and Tree ensumbles
- Works well on tabular (structured) data
- Not recommended for unstructured data (images, audio, text)
- Fast
- Small decision trees may be human interpretable
Neural Networks
- Works well on all types of data, including tabular (structed) and unstructured data
- May be slower than a decision tree
- Works with transfer learning
- When building a system of multiple models working together, is might be easier to string together multiple neural networks
在表格数据上,基于树的模型仍然优于深度学习方法。 表格数据具有特征不均匀、样本量小、极值较大等特点,因此很难找到相应的不变量。 基于树的模型不可微,不能与深度学习模块联合训练。 在表格数据上,使用基于树的方法比深度学习(甚至是现代架构)更容易实现良好的预测。
越来越感觉随机森林算法是一种变相的正则化,而 XGBoost 算一种残差算法。
101 1.1 欢迎来到第三部分 无监督学习、推荐系统和强化学习 03:23
102 2.1 什么是聚类 04:13
103 2.2 K-means 的直观理解 06:50
104 2.3 K-means 算法 09:51
105 2.4 优化目标 11:14
106 2.5 初始化 K-means 08:54
107 2.6 选择聚类的个数 07:58
手肘法 缺陷:大部分情况,可能并不存在明确的肘部。
108 3.1 发现异常事件 11:55
109 3.2 高斯(正态)分布 10:51
m-1 是样本方差,m 是二阶中心矩。
110 3.3 异常检测算法 12:09
多元正态分布。
111 3.4 开发和评估异常检测系统 11:39
112 3.5 异常检测 vs. 监督学习 08:09
| Anomaly detection | Supervised learning |
|---|---|
| Very small number of positive examples (y=1). (0-20 is common). Large number of negative (y=0) examples. 数据量非常小的时候 | Large number of positive and negative examples. 20 positive examples |
| Many different "types" of anomalies. Hard for any algorithm to learn from positive examples what the anomalies look like; future anomalies may look nothing like any of the anomalous examples we've seen so far. 可以处理没见过的错误 Fraud | Enough positive examples for algorithm to get a sense of what positive examples are like, future positive examples likely to be similar to ones in training set. Spam |
| Fraud detection | Email spam classification |
| Manufacturing - Finding new previously unseen defects in manufacturing. (e.g. aircraft engines) | Manufacturing - Finding known, previously seen defects |
| Monitoring machines in a data center | Weather prediction (sunny / rainy / etc.) |
| … | Diseases classification |
113 3.6 选择要使用的特征 14:58
这里有点 SVM 的思想。
114 4.1 提出建议 05:33
115 4.2 使用每项特征 11:23
116 4.3 协同过滤算法 13:56
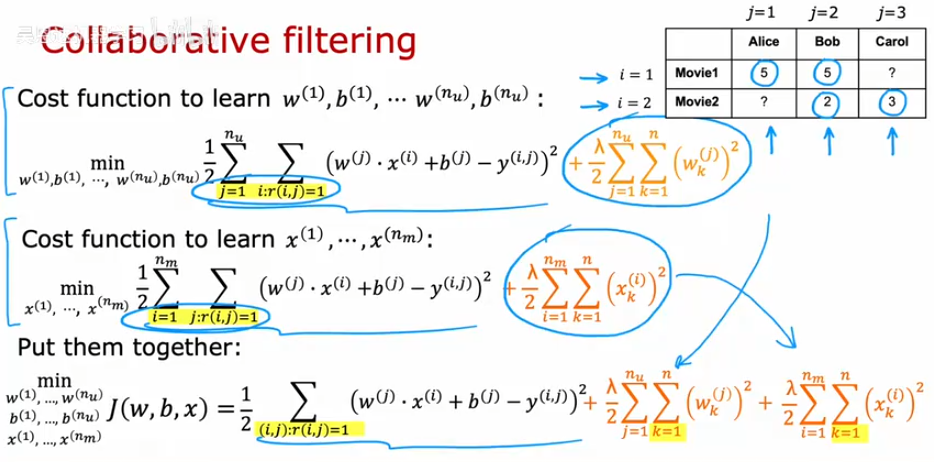
117 4.4 Binary labels- favs, likes and c 08:28
二分类问题。
118 5.1 均值归一化 08:46
119 5.2 协同过滤的 TensorFlow 实现 11:39
120 5.3 查找相关项目 06:34
121 6.1 协同过滤 vs. 基于内容的过滤 09:46
Collaborative filtering:
- Recommend items to you based on rating of users whogave similar ratings as you.
Content-based filtering:
- Recommend items to you based on features of user and itemto find good match.
有点 CLIP 的思想。
122 6.2 Deep learning for content-based 09:43
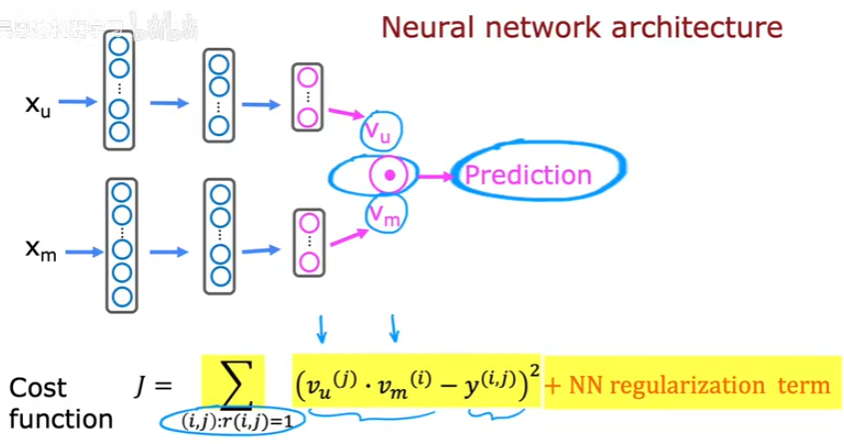
123 6.3 从大目录中推荐 07:53
CLIP & FAISS!!
124 6.4 推荐系统的道德使用 10:49
125 6.5 基于内容过滤的 TensorFlow 实现 04:49
126 7.1 什么是强化学习 08:49
127 7.2 火星探测器示例 06:42
128 7.3 The Return in reinforcement lear 10:19
129 7.4 强化学习中的决策与策略制定 02:38
130 7.5 回顾关键概念 05:35
131 8.1 状态动作值函数定义 10:37
132 8.2 状态动作值函数示例 05:23
经典,。
133 8.3 Bellman 方程 12:53
\[Q(s, a)=R(s)+\gamma \max _{a^{\prime}} Q\left(s^{\prime}, a^{\prime}\right)\]134 8.4 随机环境(可选) 08:25
135 9.1 连续状态空间应用示例 06:25
136 9.2 月球着陆器 05:55
137 9.3 学习状态值函数 16:51
138 9.4 算法优化-改进的神经网络结构 03:02
139 9.5 算法优化ϵ-贪婪策略 09:00
140 9.6 算法优化-小批量和软更新(可选) 11:44
141 9.7 强化学习的状态 02:55
142 10.1 总结与感谢 03:12
- Supervised Machine Learning:
- Regression and Classification
- Linear regression, logistic regression, gradient descent
- Advanced Learning Algorithms
- Neural networks, decision trees, advice for ML
- Unsupervised Learning, Recommenders, Reinforcement Learning
- Clustering, anomaly detection, collaborative filtering,
- content-based filtering, reinforcement learning
参考资料快照
- https://www.bilibili.com/video/BV1Bq421A74G/
- https://www.bilibili.com/video/BV1FT4y1E74V/
- https://www.a.tools/Tool.php?Id=469
- https://www.bilibili.com/video/BV164411b7dx/
- https://www.nvidia.cn/glossary/data-science/xgboost/
- https://mp.weixin.qq.com/s/BJozV5rPJLrynuT1mvbFGQ
- https://mp.weixin.qq.com/s/Rf2uczXi2JG43Y-utH7YZg
- 机器学习 -- 大型语言模型简史:从 Transformers (2017) 到 DeepSeek-R1 (2025) | 20 Feb 2025
- 机器学习 -- DALL·E 2 & 扩散模型 | 21 Dec 2024
- 机器学习 -- 学术论文解读系列(进行中) | 04 Oct 2024
- 机器学习 -- 经典论文 ViT (Vision Transformer) | 24 Jul 2024
- 机器学习 -- 跟李沐学 AI【论文精读】(进行中) | 09 Jul 2024
- 机器学习 -- Attention is all you need | 30 Jun 2024
- 机器学习笔记 -- 3Blue1Brown 深度学习 Deep Learning(已完成) | 29 Jun 2024
- 机器学习 -- 李宏毅 2021/2022 春机器学习课程(进行中) | 31 Aug 2023
- 机器学习 -- 实用机器学习 李沐(进行中) | 31 Aug 2023
- 机器学习 -- ChatGPT Prompt 提示词 吴恩达(进行中) | 28 Jul 2023
- 机器学习 -- 浙江大学 · 机器学习(已完成) | 12 Feb 2023
- 机器学习 -- 人工智能学习路线(进行中……) | 10 Feb 2023
- 机器学习 -- 北交 · 图像处理与机器学习(已完成) | 03 Dec 2022
- 机器学习笔记 -- 人工智能 机器学习 算法概览(已完成) | 13 Oct 2022
- 机器学习笔记 -- 神经网络内部发生了什么?深度学习可视化 | 13 Oct 2022
- 机器学习 -- 吴恩达机器学习 Review(已完成) | 31 Aug 2022
- 机器学习 -- 吴恩达深度学习(进行中) | 31 Aug 2022
- 机器学习 -- 吴恩达机器学习(已完成) | 31 Aug 2022
- 机器学习笔记 -- 神经网络和深度学习简史 | 26 Dec 2020
 .
.