机器学习 -- OpenAI 启示录
baidu openai 为什么坚定选择了 gpt 路线 在物理上,宇宙的下一状态只与上一状态有关,这是所谓的 locality 和 causality,量子场论遵循这一原则。而 Transformer 是一种 state(KV cache)不断增大的 RNN,它每个字都要和前面的字比对一遍,这相当于“超距作用”,不符合我们这个宇宙的物理。
大模型的涌现能力来自于其不连续的评价指标,这种不连续的评价指标导致了模型性能在到达一定程度后出现“大幅提升”。如果换成更为平滑的指标,会发现相对较小的模型的效果也并非停滞不前,规模在阈值以下的模型,随着规模的提高,生成的内容也在逐渐靠近正确答案。
GPT、DALL·E、Sora,为什么 OpenAI 可以跑通所有 AGI 技术栈? 
从 OpenAI 的愿景和技术底层逻辑推演大模型生态 OpenAI 的 blog 中对 Sora 的定位正是「作为世界模拟器的视频生成模型」。这里是 OpenAI 2016 年一篇文章的 原话:
我们常常会忽略自己对世界的深刻理解:比如,你知道这个世界由三维空间构成,里面的物体能够移动、相撞、互动;人们可以行走、交谈、思考;动物能够觅食、飞翔、奔跑或吠叫;显示屏上能展示用语言编码的信息,比如天气状况、篮球比赛的胜者,或者 1970 年发生的事件。 这样庞大的信息量就摆在那里,而且很大程度上容易获得 —— 不论是在由原子构成的物理世界,还是由数字构成的虚拟世界。挑战在于,我们需要开发出能够分析并理解这些海量数据的模型和算法。 生成模型是朝向这个目标迈进的最有希望的方法之一。要训练一个生成模型,我们首先会在某个领域收集大量的数据(想象一下,数以百万计的图片、文本或声音等),然后训练这个模型去创造类似的数据。这个方法的灵感来自于理查德 · 费曼的一句名言: 「我所无法创造的,我也不能理解。」(即:要真正理解一个事物,你需要去创造它) 这个方法的妙处在于,我们使用的神经网络作为生成模型,其参数的数量远远少于训练它们的数据量,这迫使模型必须发现并有效地吸收数据的精髓,以便能够创造出新的数据。
目标和商业模式明确
不做任何定制。 就是 all in AGI,一切研究围绕着探索通往 AGI 的路径。
而商业模式上也很简单:SaaS,直接给 API,接口设计内部自己决定,付多少钱用多少,不想用就不用, 这样省去了很多产品设计,marketing,BD 的时间,伺候甲方的时间(有比较可靠的消息称即使 Microsoft 的 Copilot 等产品也是直接用的 API,没有花功夫做太多的定制),整个公司可以集中精力开发 AGI。
OpenAI 直接用 prompt 让 GPT-4 调用 bio 这个工具记录需要记忆的内容(「to=xxx」是调用内部工具的语法,比如 "to=python" 是 GPT 调用 code interpreter 的方式)。然后每次新的对话开始时,在 prompt 的最后直接加上所有之前的记录的内容(## Model Set Context)。
这让 OpenAI 将大部分精力都花在模型本身的研发上,同时这也是 OpenAI 的方法论的极致体现,我们下面会提到。 这种方法论让 OpenAI 追求一个大的通用的模型,避免一切定制和特化,就像最近 Sam 说的一样,希望 GPT-5 的出现能让模型微调失去意义; 这样 OpenAI 就变成了完完全全的 SaaS 服务。
公理 1: The bitter lesson。
我认为所有做 AI 的人都应该熟读这篇文章。「The bitter lesson」说的事情是,长期来看,AI 领域所有的奇技淫巧都比不过强大的算力夹持的通用的 AI 算法(这里「强大的算力」隐含了大量的训练数据和大模型)。某种意义上,强大的算力加持的通用的 AI 算法才是 AGI 路径的正道,才是 AI 技术真正进步的方向。 从逻辑主义,到专家系统,到 SVM 等核方法,到深度神经网络,再到现在的大语音模型,莫不过此。 www.cs.utexas.edu/~eunsol/courses/data/bitter_lesson.pdf
纵观过去 70 年的 AI 发展历史,想办法利用更大规模的算力总是最高效的手段。 —— 《The bitter lesson》
OpenAI 极度注重算法的工程化和工程的算法思维。
公理 2: Scaling Law。
这条公理说了,一旦选择了良好且通用的数据表示,良好且通用的数据标注,良好且通用的算法,那么你就能找到一套通用规律,保证数据越多,模型越大,效果越好。 而且这套规律稳定到了可以在训练模型之前就能预知它的效果:
OpenAI 认为:AGI 基础模型本质是实现对最大有效数据集的最大程度无损压缩。 在这个技术理解下,GPT 架构的 LLM 路线是过去 5 年的最优技术路径选择,模型参数量和训练数据量的 Scale 则是必然行为。

ScalingLaw on LLMs 总结与未来
- Scaling Law 这种趋势在无限扩展的情况下是不现实的。因为自然语言本身的熵是有限的。
- Scaling Law 在某个点失效后,这个点代表的可能是 Transformer Language Model 达到了性能极限。
- 也有可能,在达到某个 Loss 后,就会用完所有自然语言的素材。这个 Loss 可能会给语言的熵提供一个估计。
- 2020 年的作者,提出了一个伟大的展望, Our results strongly suggest that larger models will continue to perform better, and will also be much more sample efficient than has been previously appreciated.
实验设置
- 优化目标是交叉熵,总共优化 2.5x105 步,batchsize 是 512,context 长度是 1024,优化器是 Adam。
- 数据集是 WebText2,vocabulary size 是 50257(好大啊),包括了 20.3M 个不同的文档,有 96GB 的文本,即 1.62x1010 个词。
杨植麟:“Scaling Law 没有本质问题,只要有更多算力、数据,模型参数变大,模型就能持续产生更多智能。 关键在于如何高效地实现 Scaling Law,如果只是沿着现在的方法,上限是明显的。 Scaling Law 并没有定义模型是什么样的,比如要有多少模态,数据是什么样的,数据是生成出来的还是用网页文本,所以 ScalingLaw 会持续演进, 只是在这个过程中 Scaling Law 的方法可能会发生很大变化。”
OpenAI 的技术底层逻辑
OpenAI 在过去 5 年坚定的选择了用 GPT(Generative Pre-training Transformer)架构持续加注 LLM(Large Language Model)的技术路径。
2018 年 6 月 OpenAI 发布 GPT-1,约四个月后 Google 发布 BERT 。 BERT 在下游理解类任务表现惊人,不仅高于 GPT-1(117M),也推动了“预训练 + 微调”范式在 NLP 中快速普及。
在整个 NLP 领域学者纷纷转向 BERT 研究时, OpenAI 进一步加码并于 2019 年 2 月推出 GPT-2(1.5B)。 GPT-2 虽然在生成任务上表现惊艳,但是在不少理解类基准上的表现仍然落后于 BERT。
在这样的背景下,OpenAI 依然坚持 GPT 路线并且大幅度加大 Scale 速度,于 2020 年 5 月推出了 GPT-3(175B)。 GPT-3 模型参数 175B(百倍于 GPT-2),训练数据量 500B Tokens( 50 倍于 GPT-2)。
OpenAI 到底做对了什么?
note ![]() note
时间拉回到 2015 年,如果 30 岁的 Sam Altman 和 29 岁的 Ilya Sutskever 这两位毛头小子。
note
时间拉回到 2015 年,如果 30 岁的 Sam Altman 和 29 岁的 Ilya Sutskever 这两位毛头小子。
技术路线一:无监督学习
OpenAI 刚成立不久,就在 Ilya Sutskever 的领导下下注“无监督学习”这条道路。 熟悉 AI 研究领域的朋友都知道,今天这个看起来无比正确的决定,在 2015-2016 年,绝对不是那么显而易见。 因为彼时的人工智能领域,通过标注数据方法的“监督学习”大行其道,在很多垂直领域比如推荐系统、机器视觉等,效果也更好。
技术路线二:生成式模型
当 2016 年,各种“识别”类任务(如视觉识别、语音识别等)大行其道时,OpenAI 在 2016 年 6 月发表《生成式模型(Generative Models)》 中开篇就引用著名物理学家费曼的名言 “What I cannot create, I do not understand. 如果不能创造,就无法理解”。 也将 OpenAI 的研究重心放在生成式任务上。
技术路线三:自然语言
为什么 OpenAI 选择押注自然语言?套用著名哲学家维特根斯坦“语言的边界就是世界的边界”。 如果用 Ilya Sutskever 的话来说 “语言是世界的映射,GPT是语言的压缩”。 就人类智能而言,自然语言是核心中的核心,而其他视觉、语音等都不过是自然语言的辅助佐料。
技术路线四:解码器
在 Transformer 打开了大语言模型的理论窗口之后,大语言模型发展出了三种路线。 第一种,以 Google BERT、ELECTRA 为代表的 Encoder-Only(编码器)路线; 第二种,以 Google T5、BART 为代表的 Encoder- Decoder(编解码器)路线; 第三种,以 OpenAI GPT 为代表的 Decoder-Only(解码器)路线。
这三种路线,Encoder-Only 路线适合理解类任务,很难应对生成式任务,也不具有好的扩展性和适应性, 虽然被 Google BERT 在个别子领域一度带火,但现在几乎处于被主流抛弃的地步。 Encoder- Decoder 路线适合特定场景任务,但通用性和扩展性也比较差。 Decoder-Only 路线首先非常适合生成类任务,同时对各类任务都具有很好的通用性,在工程上也具有很高的可扩展性(scale),非常适合将模型规模做大。
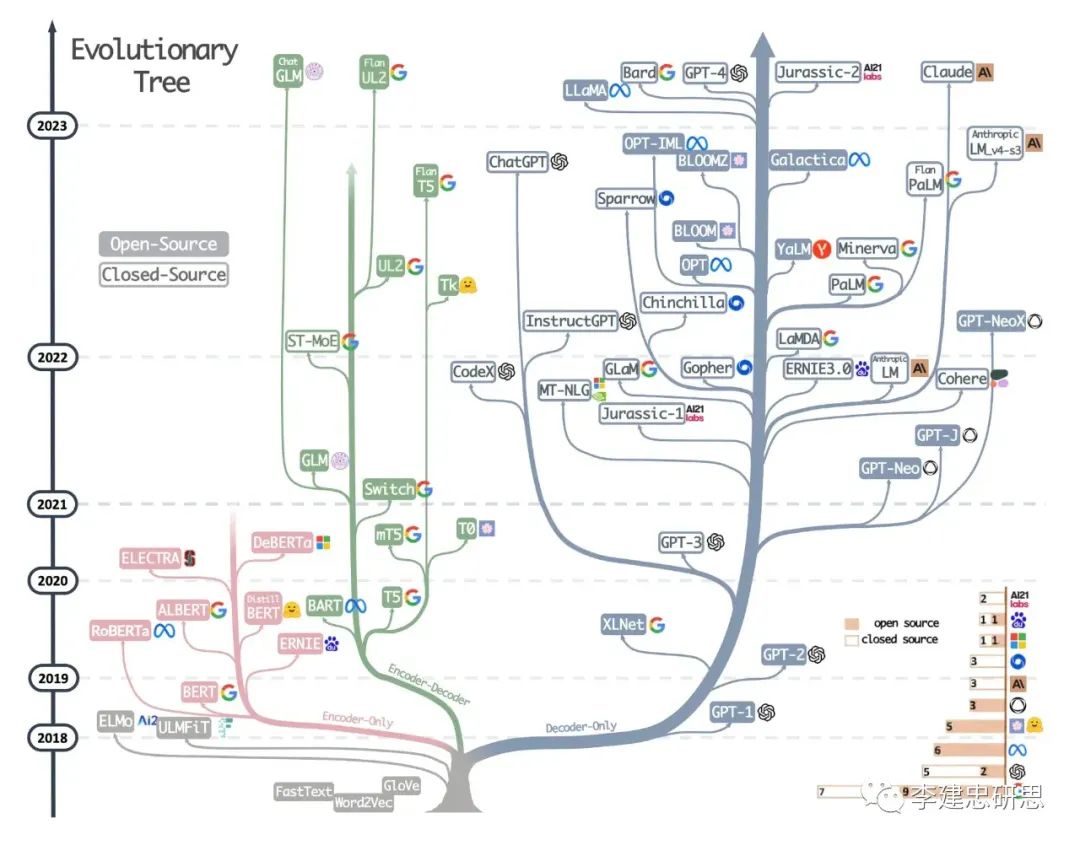
基于这些特点来看,要以 AGI 通用人工智能为目的地的话,那么 Decoder-Only 路线显然是不二选择。 从上面的大语言模型进化树来看,可以看出 GPT 选择的 Decoder-Only 路线显然引领了大语言模型的发展和繁荣。
参考资料快照
- https://mp.weixin.qq.com/s/Trlbl0RF1umCi_FeSKJI4w
- https://new.qq.com/rain/a/20230419A058FH00
- https://openai.com/research/generative-models
- https://new.qq.com/rain/a/20230417A0332A00
- https://baijiahao.baidu.com/s?id=1770459534019883480&wfr=spider&for=pc
- https://blog.csdn.net/dQCFKyQDXYm3F8rB0/article/details/131566157
- https://mp.weixin.qq.com/s/Mh9VayHdOYjaEwEtukPk_g
 .
.