机器学习 -- 如何使用 Ollama 运行 Qwen 大模型
Ollama 可以很好地支持 阿里巴巴出品的 Qwen 1.5 和 Qwen 2.0 大模型,让我们看看如何使用 Ollama 运行 Qwen 吧。 note
Ollama 简介
Ollama 是一个开源的大型语言模型服务工具,它帮助用户快速在本地运行大模型。通过简单的安装指令,用户可以执行一条命令就在本地运行开源大型语言模型,如 qwen。Ollama 极大地简化了本地部署和管理 LLM 的过程,使得用户能够快速地在本地运行大型语言模型。
Qwen 大模型
Qwen 是一个全能的语言模型系列,包含各种参数量的模型,如 Qwen(基础预训练语言模型,即基座模型)和 Qwen-Chat(聊天模型,该模型采用人类对齐技术进行微调)。基座模型在众多下游任务中始终表现出卓越的性能,而聊天模型,尤其是使用人类反馈强化学习(RLHF)训练的模型,具有很强的竞争力。聊天模型 Qwen-Chat 拥有先进的工具使用和规划能力,可用于创建 agent 应用程序。即使在使用代码解释器等复杂任务上,Qwen-Chat 与更大的模型相比也能表现出极具竞争力的性能。此外,官方还开发了编码专用模型 Code-Qwen 和 Code-Qwen-Chat,以及基于基座模型开发的数学专用模型 Math-Qwen-Chat。
安装硬件要求
CPU:当前最佳目标是第 11 代英特尔 CPU 或基于 Zen4 的 AMD CPU,因为它支持 AVX512,可加速 AI 模型所需的矩阵乘法运算。CPU 指令集功能比核心数量更重要,由于内存带宽增加,较新的 CPU 中的 DDR5 支持对于性能也很重要。
RAM:获得良好体验的最低要求:16GB 是有效运行 7B 参数等模型的起点。它足以舒适地运行较小的模型或谨慎地管理较大的模型。
磁盘空间:实际最小值:大约 50GB 就足够了。
GPU:非强制性但建议增强性能,GPU 可以显着提高模型推理性能。但是,运行量化模型的能力和对 VRAM 的要求取决于 GPU 的性能。对于运行量化模型:支持 4 位量化格式的 GPU 可以更有效地处理大型模型,所需的 VRAM 明显更少,如 7B 模型需要 4 GB,13B 模型需要 8 GB,30B 模型需要 16 GB,65B 模型需要 32 GB。
如何使用 Ollama 运行 Qwen
下载安装 Ollama
Ollama 下载地址:https://ollama.com/download,在下载页面选择 Windows 平台,然后点击下载按钮。
下载完成后,双击下载的安装程序,点击 Install 进行安装。安装完成没有提示,我们打开一个终端,本文以 CMD 为例,现在 Ollama 已经安装完了。在 cmd 窗口输入 ollama,即可了解常用的 Ollama 命令。
运行 Qwen
Qwen2 使用 29 种语言的数据进行训练,包括英语和中文。它有 4 种参数大小可供选择:0.5B、1.5B、7B、72B。在 7B 和 72B 模型中,上下文长度已扩展到 128k 个标记。 Windows 平台,在 CMD 中输入如下命令运行 qwen 大语言模型:
# 运行 Qwen 1.5,默认 4b
ollama run qwen
# 运行 Qwen2,默认 7b
ollama run qwen2
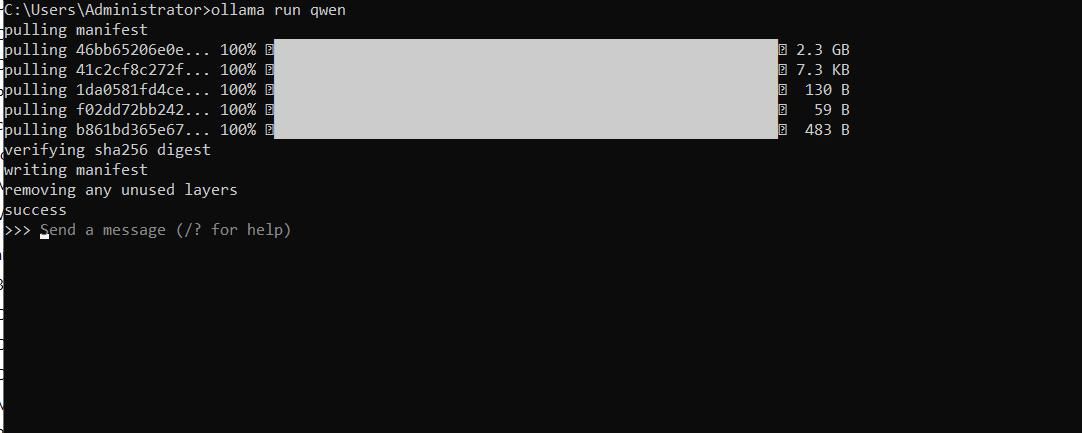
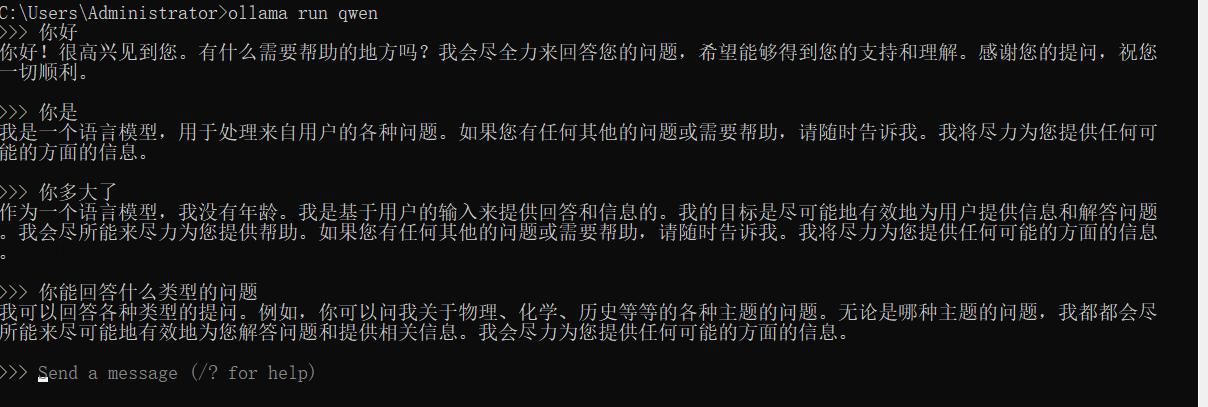
初次运行过程稍长,需要下载几个 G 的模型文件到本地。下载完成后就可以直接在终端与 qwen 模型交互了。
使用 Python 通过 qwen API 生成回复
示例代码:
import requests
import json
def send_message_to_qwen(message, port=11434):
url = f"http://127.0.0.1:{port}/api/chat"
payload = {
"model": "qwen",
"messages": [{"role": "user", "content": message}]
}
response = requests.post(url, json=payload)
if response.status_code == 200:
response_content = ""
for line in response.iter_lines():
if line:
response_content += json.loads(line)["message"]["content"]
return response_content
else:
return f"Error: {response.status_code} - {response.text}"
if __name__ == "__main__":
user_input = "介绍一下北京的旅游景点 ?"
response = send_message_to_qwen(user_input)
print("qwen's response:")
print(response)
运行结果:

支持本地部署的 AI 模型进行翻译
https://lionad.art/articles/local-translator https://lmstudio.ai/ sudo systemctl enable ollama 打开开机自启动 sudo systemctl disable ollama 关闭开机自启动
note  OLLAMA_ORIGINS="*" ollama serve
OLLAMA_ORIGINS="*" ollama serve
API_URL = "http://10.12.172.128:11434/v1/chat/completions"
# "model": "qwen2.5:14b",
REQ_SENTENCE = {
"model": "qwen2.5:14b",
"temperature": 0,
"top_p": 1,
"frequency_penalty": 1,
"presence_penalty": 1,
"keep_alive": "5m",
"messages": [{
"role": "user",
"content": "You are a professional translator.\n\n\
Only reply the result and nothing else. \
Please translate to 简体中文:\n\n"
}]
}
REQ_WORD = {
"model": "qwen2.5:14b",
"temperature": 0,
"top_p": 1,
"frequency_penalty": 1,
"presence_penalty": 1,
"keep_alive": "5m",
"messages": [{
"role": "user",
"content": "你是一个翻译引擎,请翻译给出的文本,只需要翻译不需要解释。\
当且仅当文本只有一个单词时,请给出单词原始形态(如果有)、单词的语种、\
对应的音标或转写、所有含义(含词性)、双语示例,至少三条例句。\
如果你认为单词拼写错误,请提示我最可能的正确拼写,否则请严格按照下面格式给到翻译结果:\n\
<单词>\n\
[<语种>]· / <Pinyin>\n\
[<词性缩写>] <中文含义>]\n\
例句:\n\
<序号><例句>(例句翻译)\n\
词源:\n\
<词源>\n\n\
Only reply the result and nothing else. \
好的,我明白了,请给我这个单词。:\n\n\
单词是:"
}]
}
还可以基于 vLLM 部署。
以下是 Ubuntu 系统下 Ollama 无法被局域网访问的排查与解决方法: 一、核心配置检查
修改服务绑定地址
Ollama 默认仅绑定本地回环地址 (127.0.0.1),需修改为 0.0.0.0 监听所有网络接口:
bashCopy Code
sudo systemctl edit ollama.service
在打开的文件中添加以下内容:
iniCopy Code
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
保存后执行:
bashCopy Code
sudo systemctl daemon-reload
sudo systemctl restart ollama
( 操作依据:17)
验证服务监听状态
执行命令检查端口是否成功监听:
bashCopy Code
netstat -tuln | grep 11434
若输出包含 0.0.0.0:11434 则配置生效,否则需重启服务4。
二、防火墙设置
开放端口访问权限
Ubuntu 系统若启用 ufw 防火墙,需放行 11434 端口:
bashCopy Code
sudo ufw allow 11434/tcp
sudo ufw reload
若使用 firewalld 则执行:
bashCopy Code
sudo firewall-cmd --add-port=11434/tcp --permanent
sudo firewall-cmd --reload
( 操作依据:25)
三、网络环境排查
检查局域网连通性
确保客户端与服务器处于同一子网,通过 ping 命令测试基础网络连通性。
验证 IP 地址有效性
在 Ubuntu 服务器执行 ip a 查看实际局域网 IP,确保客户端使用正确的 IP 地址访问1。
四、特殊情况处理
若服务器部署在云端(如阿里云 / 腾讯云),需额外检查:
云平台安全组规则是否放行 11434 端口8;
服务器内部是否启用 SELinux 等强制访问控制机制(建议临时禁用测试)4。
提示:完成上述配置后,其他设备可通过 http://[服务器 IP]:11434 访问 Ollama 服务。若仍失败,建议检查 Ollama 日志:
bashCopy Code
journalctl -u ollama -f
参考资料快照
 .
.