机器学习 -- Paddle-OCR 根据垂直类场景自定义数据微调 PP-OCRv4 模型
Paddle-OCR 根据垂直类场景自定义数据微调 PP-OCRv4 模型
python3 kremote.py rebindex code_myocr_data.json
python3 kremote.py rebindex code_myocr_dlf.json
1 文本检测模型微调
数据准备:
- 加入少量真实数据(检测任务 >=500 张,识别任务 >=5000 张),会大幅提升垂类场景的检测与识别效果
- 在模型微调时,加入真实通用场景数据,可以进一步提升模型精度与泛化性能
- 在图像检测任务中,增大图像的预测尺度,能够进一步提升较小文字区域的检测效果
- 在模型微调时,需要适当调整超参数(学习率,batch size 最为重要),以获得更优的微调效果。
- 数据标注:单行文本标注格式,建议标注的检测框与实际语义内容一致。
1-1 数据准备
- 数据量:建议至少准备 500 张的文本检测数据集用于模型微调。
- 数据标注:单行文本标注格式,建议标注的检测框与实际语义内容一致。 如在火车票场景中,姓氏与名字可能离得较远,但是它们在语义上属于同一个检测字段,这里也需要将整个姓名标注为 1 个检测框。
训练集 & 校验集
PaddleOCR 中的文本检测算法支持的标注文件格式如下,中间用 "\t" 分隔:
" 图像文件名 json.dumps 编码的图像标注信息"
ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
json.dumps 编码前的图像标注信息是包含多个字典的 list,字典中的 points 表示文本框的四个点的坐标 (x, y),从左上角的点开始顺时针排列。
transcription 表示当前文本框的文字, 当其内容为“###”时,表示该文本框无效,在训练时会跳过。
公开数据集
| 数据集名称 | 图片下载地址 | PaddleOCR 标注下载地址 |
|---|---|---|
| ICDAR 2015 | https://rrc.cvc.uab.es/?ch=4&com=downloads | train / test |
| ctw1500 | https://paddleocr.bj.bcebos.com/dataset/ctw1500.zip | 图片下载地址中已包含 |
| total text | https://paddleocr.bj.bcebos.com/dataset/total_text.tar | 图片下载地址中已包含 |
| td tr | https://paddleocr.bj.bcebos.com/dataset/TD_TR.tar | 图片下载地址中已包含 |
https://github.com/breezedeus/cnstd ICPR MTWI 2018 ICDAR RCTW-17 ICDAR2019-LSVT https://github.com/PaddlePaddle/PaddleOCR/blob/main/doc/doc_ch/dataset/datasets.md https://github.com/PaddlePaddle/PaddleOCR/blob/main/doc/doc_ch/dataset/ocr_datasets.md
| 数据集名称 | 图片下载地址 | PaddleOCR 标注下载地址 |
|---|---|---|
| ICDAR 2015 | https://rrc.cvc.uab.es/?ch=4&com=downloads | train / test |
| ctw1500 | https://paddleocr.bj.bcebos.com/dataset/ctw1500.zip | 图片下载地址中已包含 |
| total text | https://paddleocr.bj.bcebos.com/dataset/total_text.tar | 图片下载地址中已包含 |
| td tr | https://paddleocr.bj.bcebos.com/dataset/TD_TR.tar | 图片下载地址中已包含 |
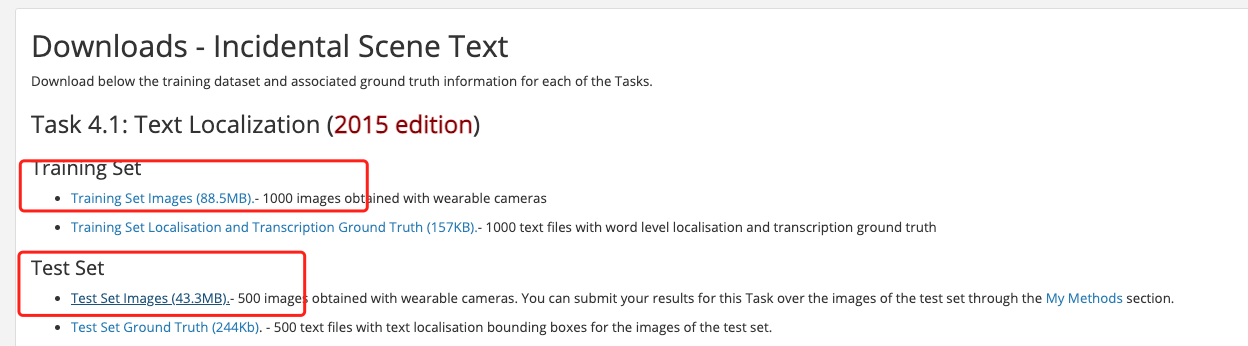
- myocr_dlf.json 自有的 dlf 数据。已经索引完成未上传。
- myocr_data.json 百度上面的几个数据。已经上传并索引完成。
- myocr_dataYCG09.json YCG09 数据。上传中……
- myocr_dataALL.json 大数据集汇总。上传中……
1-2 下载预训练模型
1-3 参数配置
配置文件: configs/det/ch_PP-OCRv4/ch_PP-OCRv4_det_student.yml
Global:
debug: false
use_gpu: true
epoch_num: &epoch_num 500
log_smooth_window: 20
print_batch_step: 100
save_model_dir: ./output/ch_PP-OCRv4
save_epoch_step: 10
eval_batch_step:
- 0
- 1500
cal_metric_during_train: false
checkpoints:
pretrained_model: https://paddleocr.bj.bcebos.com/pretrained/PPLCNetV3_x0_75_ocr_det.pdparams
save_inference_dir: null
use_visualdl: false
infer_img: doc/imgs_en/img_10.jpg
save_res_path: ./checkpoints/det_db/predicts_db.txt
distributed: true
Architecture:
model_type: det
algorithm: DB
Transform: null
Backbone:
name: PPLCNetV3
scale: 0.75
det: True
Neck:
name: RSEFPN
out_channels: 96
shortcut: True
Head:
name: DBHead
k: 50
Loss:
name: DBLoss
balance_loss: true
main_loss_type: DiceLoss
alpha: 5
beta: 10
ohem_ratio: 3
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.001 #(8*8c)
warmup_epoch: 2
regularizer:
name: L2
factor: 5.0e-05
PostProcess:
name: DBPostProcess
thresh: 0.3
box_thresh: 0.6
max_candidates: 1000
unclip_ratio: 1.5
Metric:
name: DetMetric
main_indicator: hmean
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/icdar2015/text_localization/
label_file_list:
- ./train_data/icdar2015/text_localization/train_icdar2015_label.txt
ratio_list: [1.0]
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- DetLabelEncode: null
- CopyPaste: null
- IaaAugment:
augmenter_args:
- type: Fliplr
args:
p: 0.5
- type: Affine
args:
rotate:
- -10
- 10
- type: Resize
args:
size:
- 0.5
- 3
- EastRandomCropData:
size:
- 640
- 640
max_tries: 50
keep_ratio: true
- MakeBorderMap:
shrink_ratio: 0.4
thresh_min: 0.3
thresh_max: 0.7
total_epoch: *epoch_num
- MakeShrinkMap:
shrink_ratio: 0.4
min_text_size: 8
total_epoch: *epoch_num
- NormalizeImage:
scale: 1./255.
mean:
- 0.485
- 0.456
- 0.406
std:
- 0.229
- 0.224
- 0.225
order: hwc
- ToCHWImage: null
- KeepKeys:
keep_keys:
- image
- threshold_map
- threshold_mask
- shrink_map
- shrink_mask
loader:
shuffle: true
drop_last: false
batch_size_per_card: 8
num_workers: 8
Eval:
dataset:
name: SimpleDataSet
data_dir: ./train_data/icdar2015/text_localization/
label_file_list:
- ./train_data/icdar2015/text_localization/test_icdar2015_label.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- DetLabelEncode: null
- DetResizeForTest:
- NormalizeImage:
scale: 1./255.
mean:
- 0.485
- 0.456
- 0.406
std:
- 0.229
- 0.224
- 0.225
order: hwc
- ToCHWImage: null
- KeepKeys:
keep_keys:
- image
- shape
- polys
- ignore_tags
loader:
shuffle: false
drop_last: false
batch_size_per_card: 1
num_workers: 2
profiler_options: null
学习率调整
PaddleOCR 提供的配置文件是在 8 卡训练(相当于总的 batch size 是 8*8=64)、且没有加载预训练模型情况下的配置文件, 因此您的场景中,学习率与总的 batch size 需要对应线性调整,例如
- 如果您的场景中是单卡训练,单卡 batch_size=8,则总的 batch_size=8,建议将学习率调整为 1e-4 左右。
- 如果您的场景中是单卡训练,由于显存限制,只能设置单卡 batch_size=4,则总的 batch_size=4,建议将学习率调整为 5e-5 左右。
1-4 训练
python tools/train.py -c configs/det/ch_PP-OCRv4/ch_PP-OCRv4_det_student.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
1-5 评估
python tools/eval.py -c configs/det/ch_PP-OCRv4/ch_PP-OCRv4_det_student.yml -o Global.checkpoints="{path/to/weights}/best_accuracy"
1-6 推理
python tools/infer_det.py -c configs/det/ch_PP-OCRv4/ch_PP-OCRv4_det_student.yml -o Global.infer_img="./doc/imgs_en/img_10.jpg" Global.pretrained_model="./output/det_db/best_accuracy"
1-7 导出
python3 tools/export_model.py -c configs/det/ch_PP-OCRv4/ch_PP-OCRv4_det_student.yml -o Global.pretrained_model="./output/det_db/best_accuracy" Global.save_inference_dir="./output/det_db_inference/"
2 文本识别模型微调
2-1 数据准备
- 数据量:不更换字典的情况下,建议至少准备 5000 张的文本识别数据集用于模型微调;如果更换了字典(不建议),需要的数量更多。
- 数据分布:建议分布与实测场景尽量一致。如果实测场景包含大量短文本,则训练数据中建议也包含较多短文本,如果实测场景对于空格识别效果要求较高,则训练数据中建议也包含较多带空格的文本内容。
- 数据合成:针对部分字符识别有误的情况,建议获取一批特定字符数据,加入到原数据中使用小学习率微调。其中原始数据与新增数据比例可尝试 10:1 ~ 5:1, 避免单一场景数据过多导致模型过拟合,同时尽量平衡语料词频,确保常用字的出现频率不会过低。
- 特定字符生成可以使用 TextRenderer 工具,合成例子可参考 数码管数据合成 ,合成数据语料尽量来自真实使用场景,在贴近真实场景的基础上保持字体、背景的丰富性,有助于提升模型效果。
- 通用中英文数据:在训练的时候,可以在训练集中添加通用真实数据(如在不更换字典的微调场景中,建议添加 LSVT、RCTW、MTWI 等真实数据),进一步提升模型的泛化性能。
训练集 & 校验集
建议将训练图片放入同一个文件夹,并用一个 txt 文件(rec_gt_train.txt)记录图片路径和标签,txt 文件里的内容如下 :
注意: txt 文件中默认请将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错。
" 图像文件名 图像标注信息 "
train_data/rec/train/word_001.jpg 简单可依赖
train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
...
最终训练集应有如下文件结构:
| -train_data
| -rec
| - rec_gt_train.txt
| - train
| - word_001.png
| - word_002.jpg
| - word_003.jpg
| ...
除上述单张图像为一行格式之外,PaddleOCR 也支持对离线增广后的数据进行训练,为了防止相同样本在同一个 batch 中被多次采样, 我们可以将相同标签对应的图片路径写在一行中,以列表的形式给出,在训练中,PaddleOCR 会随机选择列表中的一张图片进行训练。 对应地,标注文件的格式如下。
["11.jpg", "12.jpg"] 简单可依赖
["21.jpg", "22.jpg", "23.jpg"] 用科技让复杂的世界更简单
3.jpg ocr
上述示例标注文件中,"11.jpg" 和 "12.jpg" 的标签相同,都是 简单可依赖 ,在训练的时候,对于该行标注,会随机选择其中的一张图片进行训练。
如果有通用真实场景数据加进来,建议每个 epoch 中,垂类场景数据与真实场景的数据量保持在 1:1 左右。
比如:您自己的垂类场景识别数据量为 1W,数据标签文件为 vertical.txt ,收集到的通用场景识别数据量为 10W,数据标签文件为 general.txt ,
那么,可以设置 label_file_list 和 ratio_list 参数如下所示。
每个 epoch 中, vertical.txt 中会进行全采样(采样比例为 1.0),包含 1W 条数据;
general.txt 中会按照 0.1 的采样比例进行采样,包含 10W*0.1=1W 条数据,最终二者的比例为 1:1 。
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/
label_file_list:
- vertical.txt
- general.txt
ratio_list: [1.0, 0.1]
字典
需要提供一个自定义字典({word_dict_name}.txt),使模型在训练时,可以将所有出现的字符映射为字典的索引。
因此字典需要包含所有希望被正确识别的字符,{word_dict_name}.txt 需要写成如下格式,并以 utf-8 编码格式保存:
l
d
a
d
r
n
word_dict.txt 每行有一个单字,将字符与数字索引映射在一起,“and” 将被映射成 [2 5 1]
内置字典
PaddleOCR 内置了一部分字典,可以按需使用。
ppocr/utils/ppocr_keys_v1.txt是一个包含 6623 个字符的中文字典ppocr/utils/ic15_dict.txt是一个包含 36 个字符的英文字典ppocr/utils/en_dict.txt是一个包含 96 个字符的英文字典
自定义字典
如需自定义 dic 文件,请在实际使用的识别配置文件中添加 character_dict_path 字段,例如本文的 configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml,并指向您的字典路径。
添加空格类别
如果希望支持识别“空格”类别,请将 yml 文件中的 use_space_char 字段设置为 True。
公开数据集
| 数据集名称 | 图片下载地址 | PaddleOCR 标注下载地址 |
|---|---|---|
| en benchmark(MJ, SJ, IIIT, SVT, IC03, IC13, IC15, SVTP, and CUTE.) | DTRB  |
LMDB 格式,可直接用 lmdb_dataset.py 加载 |
| ICDAR 2015 | http://rrc.cvc.uab.es/?ch=4&com=downloads | train / test |
| 多语言数据集 | 百度网盘 提取码:frgi google drive | 图片下载地址中已包含 |
| 数据集名称 | 图片下载地址 | PaddleOCR 标注下载地址 |
|---|---|---|
| en benchmark(MJ, SJ, IIIT, SVT, IC03, IC13, IC15, SVTP, and CUTE.) | DTRB |
LMDB 格式,可直接用 lmdb_dataset.py 加载 |
| ICDAR 2015 | http://rrc.cvc.uab.es/?ch=4&com=downloads | train/ test |
| 多语言数据集 | 百度网盘 提取码:frgi google drive |
图片下载地址中已包含 |
数据集下载: https://aistudio.baidu.com/projectdetail/2448756
数据集链接:百度网盘 data_lmdb_release.zip,提取码:rryk ,下载整个 data_lmdb_release 文件夹。
本项目使用的是原文作者制作的文本识别数据集合集:data_lmdb_release.zip,其中包含以下内容:
- training datasets:MJSynth (MJ) 和 SynthText (ST),总数 12747394 个。
- validation datasets:训练集 IC13、IC15、IIIT 和 SVT 的合集。
- evaluation datasets:基准评估数据集,包括 IIIT、SVT、IC03、IC13、IC15、SVTP 和 CUTE。
2-2 下载预训练模型
2-3 参数配置
配置文件:configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml
Global:
debug: false
use_gpu: true
epoch_num: 200
log_smooth_window: 20
print_batch_step: 10
save_model_dir: ./output/rec_ppocr_v4
save_epoch_step: 10
eval_batch_step: [0, 2000]
cal_metric_during_train: true
pretrained_model:
checkpoints:
save_inference_dir:
use_visualdl: false
infer_img: doc/imgs_words/ch/word_1.jpg
character_dict_path: ppocr/utils/ppocr_keys_v1.txt
max_text_length: &max_text_length 25
infer_mode: false
use_space_char: true
distributed: true
save_res_path: ./output/rec/predicts_ppocrv3.txt
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.001
warmup_epoch: 5
regularizer:
name: L2
factor: 3.0e-05
Architecture:
model_type: rec
algorithm: SVTR_LCNet
Transform:
Backbone:
name: PPLCNetV3
scale: 0.95
Head:
name: MultiHead
head_list:
- CTCHead:
Neck:
name: svtr
dims: 120
depth: 2
hidden_dims: 120
kernel_size: [1, 3]
use_guide: True
Head:
fc_decay: 0.00001
- NRTRHead:
nrtr_dim: 384
max_text_length: *max_text_length
Loss:
name: MultiLoss
loss_config_list:
- CTCLoss:
- NRTRLoss:
PostProcess:
name: CTCLabelDecode
Metric:
name: RecMetric
main_indicator: acc
Train:
dataset:
name: MultiScaleDataSet
ds_width: false
data_dir: ./train_data/
ext_op_transform_idx: 1
label_file_list:
- ./train_data/train_list.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- RecConAug:
prob: 0.5
ext_data_num: 2
image_shape: [48, 320, 3]
max_text_length: *max_text_length
- RecAug:
- MultiLabelEncode:
gtc_encode: NRTRLabelEncode
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_gtc
- length
- valid_ratio
sampler:
name: MultiScaleSampler
scales: [[320, 32], [320, 48], [320, 64]]
first_bs: &bs 192
fix_bs: false
divided_factor: [8, 16] # w, h
is_training: True
loader:
shuffle: true
batch_size_per_card: *bs
drop_last: true
num_workers: 8
Eval:
dataset:
name: SimpleDataSet
data_dir: ./train_data
label_file_list:
- ./train_data/val_list.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- MultiLabelEncode:
gtc_encode: NRTRLabelEncode
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_gtc
- length
- valid_ratio
loader:
shuffle: false
drop_last: false
batch_size_per_card: 128
num_workers: 4
学习率调整
PaddleOCR 提供的配置文件是在 8 卡训练(相当于总的 batch size 是 8*128=1024)、且没有加载预训练模型情况下的配置文件,因此您的场景中,学习率与总的 batch size 需要对应线性调整,例如:
- 如果您的场景中是单卡训练,单卡 batch_size=128,则总的 batch_size=128,在加载预训练模型的情况下,建议将学习率调整为 [1e-4, 2e-5] 左右(piecewise 学习率策略,需设置 2 个值,下同)。
- 如果您的场景中是单卡训练,因为显存限制,只能设置单卡 batch_size=64,则总的 batch_size=64,在加载预训练模型的情况下,建议将学习率调整为 [5e-5, 1e-5] 左右。
2-4 训练
python tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
2-5 评估
python tools/eval.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.checkpoints={path/to/weights}/best_accuracy
2-6 推理
python tools/infer_rec.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/ch/word_1.jpg
2-7 导出
python tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.save_inference_dir=./inference/ch_PP-OCRv4_rec/
3 文本方向分类器微调
3-1 数据准备
训练集 & 校验集
首先建议将训练图片放入同一个文件夹,并用一个 txt 文件(cls_gt_train.txt)记录图片路径和标签。
注意: 默认请将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错
0 和 180 分别表示图片的角度为 0 度和 180 度
" 图像文件名 图像标注信息 "
train/cls/train/word_001.jpg \t 0
train/cls/train/word_002.jpg \t 180
最终训练集应有如下文件结构:
| -train_data
| -cls
| - cls_gt_train.txt
| - train
| - word_001.png
| - word_002.jpg
| - word_003.jpg
| ...
3-2 下载预训练模型
ch_ppocr_mobile_v2.0_cls_train
3-3 参数配置
将准备好的 txt 文件和图片文件夹路径分别写入配置文件的 Train/Eval.dataset.label_file_list 和
Train/Eval.dataset.data_dir 字段下, Train/Eval.dataset.data_dir 字段下的路径和文件里记载的图片名构成了图片的绝对路径。
3-4 训练
python tools/train.py -c configs/cls/cls_mv3.yml
3-5 评估
python tools/eval.py -c configs/cls/cls_mv3.yml -o Global.checkpoints={path/to/weights}/best_accuracy
3-6 推理
python tools/infer_cls.py -c configs/cls/cls_mv3.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.load_static_weights=false Global.infer_img=doc/imgs_words/ch/word_1.jpg
Windows 重装 Ubuntu 22.04.4 LTS 单系统
https://blog.csdn.net/qq_41833455/article/details/117882535
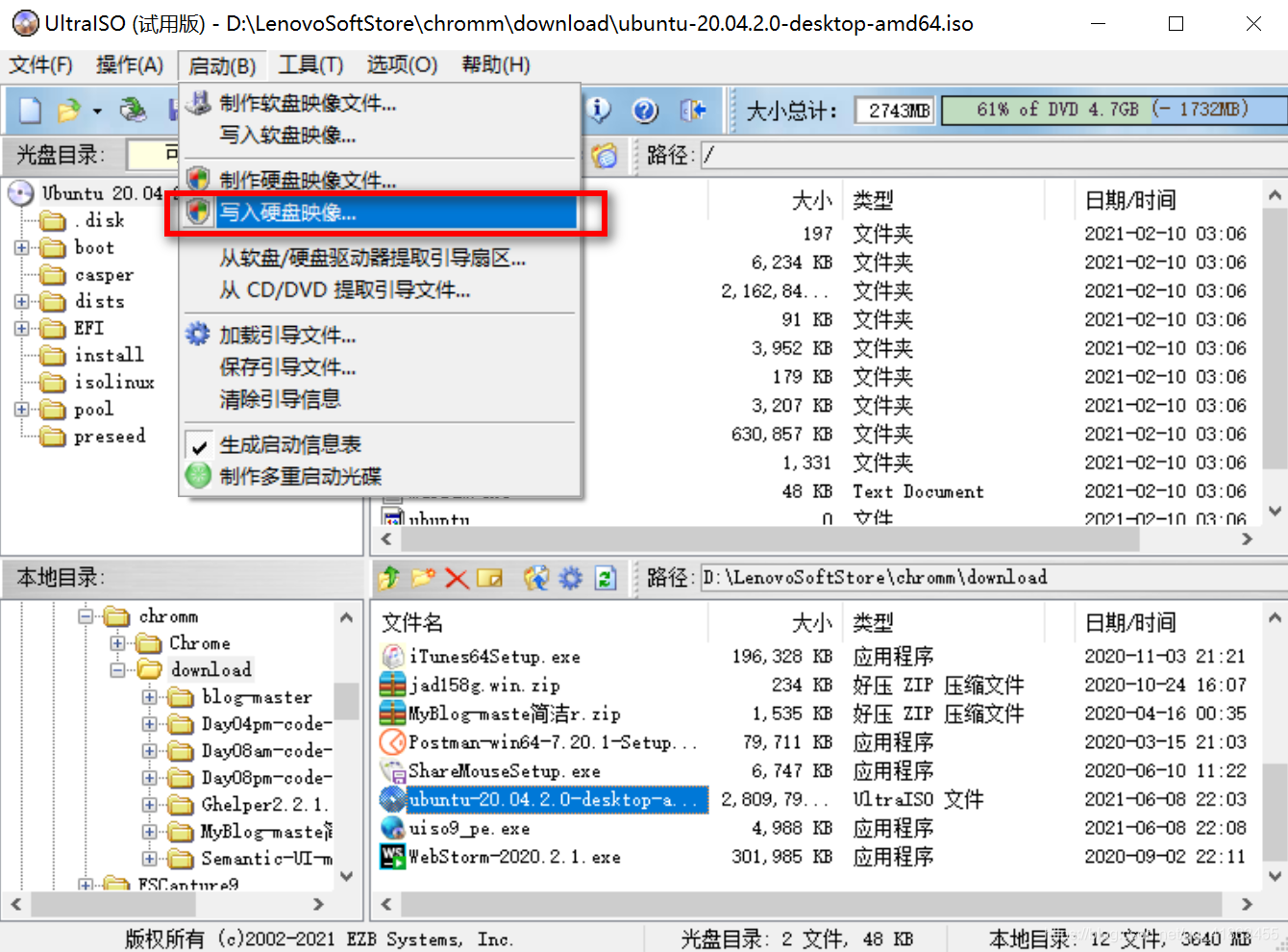
便捷启动 —— > 写入新的硬盘引导记录 (MBR) —— > USB-HDD+:
Windows 远程登陆 Ubuntu 图形桌面
在 windows 上使用 windows 自带的远程工具(mstsc)远程登陆 Ubuntu 的图形界面窗口。
https://www.cnblogs.com/conefirst/articles/15401996.html
- sudo apt-get install tightvncserver xrdp
mstsc
设置完以上参数记得重启一下系统。 https://baijiahao.baidu.com/s?id=1787763689020400650&wfr=spider&for=pc
G:\work\pythonx\myocr\mydata\rec\data_lmdb_release\evaluation.zip G:\work\pythonx\myocr\mydata\rec\data_lmdb_release\README.txt G:\work\pythonx\myocr\mydata\rec\data_lmdb_release\ST_spe.zip G:\work\pythonx\myocr\mydata\rec\data_lmdb_release\validation.zip
Detect the device changes. Support hotplug event for win and linux now. https://github.com/wang-bin/qdevicewatcher
Refs
- https://liumin.blog.csdn.net/article/details/134423832
- https://blog.csdn.net/cyj972628089/article/details/136444512
- https://gitcode.csdn.net/662a077716ca5020cb59861a.html
distlib/PC/launcher.c
参考资料快照
- https://rrc.cvc.uab.es/?ch=4&com=downloads
- https://github.com/breezedeus/cnstd
- https://github.com/PaddlePaddle/PaddleOCR/blob/main/doc/doc_ch/dataset/datasets.md
- https://github.com/PaddlePaddle/PaddleOCR/blob/main/doc/doc_ch/dataset/ocr_datasets.md
- https://github.com/clovaai/deep-text-recognition-benchmark#download-lmdb-dataset-for-traininig-and-evaluation-from-here
- https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/ppocr/data/lmdb_dataset.py
- http://rrc.cvc.uab.es/?ch=4&com=downloads
- https://pan.baidu.com/s/1bS_u207Rm7YbY33wOECKDA
- https://drive.google.com/file/d/18cSWX7wXSy4G0tbKJ0d9PuIaiwRLHpjA/view
- https://aistudio.baidu.com/projectdetail/2448756
- https://pan.baidu.com/s/1KSNLv4EY3zFWHpBYlpFCBQ
- http://www.robots.ox.ac.uk/~vgg/data/text/
- http://www.robots.ox.ac.uk/~vgg/data/scenetext/
- http://rrc.cvc.uab.es/?ch=2
- http://rrc.cvc.uab.es/?ch=4
- http://cvit.iiit.ac.in/projects/SceneTextUnderstanding/IIIT5K.html
- http://www.iapr-tc11.org/mediawiki/index.php/The_Street_View_Text_Dataset
- http://www.iapr-tc11.org/mediawiki/index.php/ICDAR_2003_Robust_Reading_Competitions
- http://openaccess.thecvf.com/content_iccv_2013/papers/Phan_Recognizing_Text_with_2013_ICCV_paper.pdf
- http://cs-chan.com/downloads_CUTE80_dataset.html
- https://blog.csdn.net/qq_41833455/article/details/117882535
- https://www.cnblogs.com/conefirst/articles/15401996.html
- https://baijiahao.baidu.com/s?id=1787763689020400650&wfr=spider&for=pc
- https://github.com/wang-bin/qdevicewatcher
- https://liumin.blog.csdn.net/article/details/134423832
- https://blog.csdn.net/cyj972628089/article/details/136444512
- https://gitcode.csdn.net/662a077716ca5020cb59861a.html
 .
.