编程与调试 -- 代码精进之路:从码农到工匠
代码精进之路 从码农到工匠.pdf
- 技艺部分(第 1~7 章)
- 思想部分(第 8~11 章)
- 实践部分(第 12、13 章)
“Talk is cheap, show me the code”
第 1 章 命名
代码即文档,可读性好的代码应该有一定的自明性,也就是不借助注释和文档,代码本身就能显性化地表达开发者的意图。
方法名约定
| CRUD 操作 | 方法名约定 |
|---|---|
| 新增 | create |
| 添加 | add |
| 删除 | remove |
| 修改 | update |
| 查询(单个结果) | get |
| 查询(多个结果) | list |
| 分页查询 | page |
| 统计 | count |
使用对仗词
- add/remove
- increment/decrement
- open/close
- begin/end
- insert/delete
- show/hide
- create/destroy
- lock/unlock
- source/target
- first/last
- min/max
- start/stop
- get/set
- next/previous
- up/down
- old/new
中间变量
我们要通过 Regex 来获得字符串中的值,并放到 map 中。
Matcher matcher = headerPattern.matcher(line);
if (matcher.find()) {
headers.put(matcher.group(1), matcher.group(2));
}
用中间变量,可以写成如下形式:
Matcher matcher = headerPattern.matcher(line);
if (matcher.find()) {
String key = matcher.group(1);
String value = matcher.group(2);
headers.put(key, value);
}
第 2 章 规范
埋点规范
在阿里巴巴有一个超级位置模型(Super Position Model,SPM)的埋点规范,用于统计分析各种场景的用户行为数据。 比如,淘宝社区电商业务(xTao)为外部合作伙伴(外站)提供的一套跟踪引导成交效果数据的解决方案,其中就用到了 SPM。
例如,一个跟踪点击到宝贝详情页的引导成交效果数据的 SPM 示例,其导购链接为 http://detail.tmall.com/item.htm?id=3716461318&spm=2014.123456789.1.2。
2014.123456789.1.2 叫作 SPM 编码,是用于跟踪页面模块位置的编码,标准 SPM 编码由 4 段组成,采用 a.b.c.d 的格式。
- a 代表站点类型,对于 xTao 合作伙伴(外站),a 为固定值,a=2014。
- b 代表外站 ID(即外站所使用的 TOP appkey),比如你的站点使用的 TOP appkey=123456789,则 b=123456789。
- c 代表 b 站点上的频道 ID,比如外站某个团购频道、某个逛街频道、某个试用频道等。
- d 代表 c 频道上的页面 ID,比如某个团购详情页、某个宝贝详情页、某个试用详情页等。
通过基于这套规范采集的数据,我们可以利用 SPM 编码的不同层次来做不同维度的导购效果跟踪分析。
- 单独统计 spm 的 a 部分,我们可以知道某一类站点的访问和点击情况,以及后续引导和成交情况。
- 单独统计 spm 的 a.b 部分,我们可以评估某一个站点的访问和点击效果,以及后续引导和成交情况。
- 单独统计 spm 的 a.b.c 部分,我们可以评估某一个站点上某一频道的访问和点击效果,以及后续引导和成交情况。
- 单独统计 spm 的 a.b.c.d 部分,我们可以评估某一个频道上某一具体页面的点击效果,以及后续引导和成交情况。
第 3 章 函数
优化判空
if (user != null) {
Address address = user.getAddress();
if (address != null) {
Country country = address.getCountry();
if (country != null) {
String isocode = country.getIsocode();
if (isocode != null) {
isocode = isocode.toUpperCase();
}
}
}
}
String isocode = Optional.ofNullable(user)
.map(User::getAddress)
.map(Address::getCountry)
.map(Country::getIsocode)
.orElse("default");
可以看到,新的写法比旧的判空方式在复杂度和简洁性上都提升了很多,简洁也是一种美。
SLAP
抽象层次一致性(Single Level of Abstraction Principle,SLAP),是和组合函数密切相关的一个原则。 组合函数要求将一个大函数拆成多个子函数的组合,而 SLAP 要求函数体中的内容必须在同一个抽象层次上。 如果高层次抽象和底层细节杂糅在一起,就会显得凌乱,难以理解。
举个例子,假如有一个冲泡咖啡的原始需求,其制作咖啡的过程分为 3 步。
- 倒入咖啡粉。
- 加入沸水。
- 搅拌。
其伪代码(pseudo code)如下:
public void makeCoffee() {
pourCoffeePowder();
pourWater();
stir();
}
如果要加入新的需求,比如需要允许选择不同的咖啡粉,以及选择不同的风味,那么代码就会变成这样:
public void makeCoffee(boolean isMilkCoffee, boolean isSweetTooth, CoffeeType type) {
// 选择咖啡粉
if (type == CAPPUCCINO) {
pourCappuccinoPowder();
} else if (type == BLACK) {
pourBlackPowder();
} else if (type == MOCHA) {
pourMochaPowder();
} else if (type == LATTE) {
pourLattePowder();
} else if (type == ESPRESSO) {
pourEspressoPowder();
}
// 加入沸水
pourWater();
// 选择口味
if (isMilkCoffee) {
pourMilk();
}
if (isSweetTooth) {
addSugar();
}
// 搅拌
stir();
}
如果继续有更多的需求加入,那么代码会进一步恶化,最后变成一个谁也看不懂且难以维护的逻辑迷宫。
再回看上面的代码,新需求的引入当然是根本原因。但除此之外,另一个原因是新代码已经不再满足 SLAP 了。具体选择用什么样的咖啡粉是倒入咖啡粉这个步骤应该去考虑的实现细节,和主流程步骤不在一个抽象层次上。同理,加奶和加糖也是实现细节。
因此,在引入新需求以后,制作咖啡的主要步骤从原来的 3 步变成了 4 步。
- 倒入咖啡粉,会有不同的选择。
- 加入沸水。
- 调味,根据需求加糖或加奶。
- 搅拌。
按照组合函数和 SLAP 原则,我们要在入口函数中只显示业务处理的主要步骤。具体的实现细节通过私有方法进行封装,并通过抽象层次一致性来保证,一个函数中的抽象在同一个水平上,而不是高层抽象和实现细节混杂在一起。
根据 SLAP 原则,我们可以将代码重构为:
public void makeCoffee(boolean isMilkCoffee, boolean isSweetTooth, CoffeeType type) {
// 选择咖啡粉
pourCoffeePowder(type);
// 加入沸水
pourWater();
// 选择口味
flavor(isMilkCoffee, isSweetTooth);
// 搅拌
stir();
}
private void flavor(boolean isMilkCoffee, boolean isSweetTooth) {
if (isMilkCoffee) {
pourMilk();
}
if (isSweetTooth) {
addSugar();
}
}
private void pourCoffeePowder(CoffeeType type) {
if (type == CAPPUCCINO) {
pourCappuccinoPowder();
} else if (type == BLACK) {
pourBlackPowder();
} else if (type == MOCHA) {
pourMochaPowder();
} else if (type == LATTE) {
pourLattePowder();
} else if (type == ESPRESSO) {
pourEspressoPowder();
}
}
重构后的 makeCoffee() 又重新变得整洁如初了,满足 SLAP 实际上是构筑了代码结构的金字塔。 金字塔结构是一种自上而下的,符合人类思维逻辑的表达方式。
在构筑金字塔的过程中,要求金字塔的每一层要属于同一个逻辑范畴、同一个抽象层次。在这一点上,金字塔原理和 SLAP 是相通的,世界就是如此奇妙,很多道理在不同的领域同样适用。
上面列举了 Spring 源码中的一个“坏味道”,接下来我们来看 Spring 的“好味道”。在 Spring 中,做上下文初始化的核心类 AbstractApplicationContext 的 refresh() 函数为我们在遵循 SLAP 方面做了一个很好的示范。
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining(non-lazy-init)singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
} catch (BeansException ex) {
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
} finally {
// Reset common introspection caches in Spring's core,
// since we might not ever need metadata for singleton
// beans anymore...
resetCommonCaches();
}
}
}
试想,如果上面的代码逻辑不是这样写,而是平铺在 refresh() 函数中,结果会是怎样?
第 4 章 设计原则
SOLID 概览
SOLID 是 5 个设计原则开头字母的缩写,其本身就有“稳定的”的意思,寓意是“遵从SOLID原则可以建立稳定、灵活、健壮的系统”。5 个原则分别如下。
- Single Responsibility Principle(SRP):单一职责原则。
- Open Close Principle(OCP):开闭原则。
- Liskov Substitution Principle(LSP):里氏替换原则。
- Interface Segregation Principle(ISP):接口隔离原则。
- Dependency Inversion Principle(DIP):依赖倒置原则。
开闭原则和里氏代换原则是设计目标;单一职责原则、接口分隔原则和依赖倒置原则是设计方法。
第 5 章 设计模式
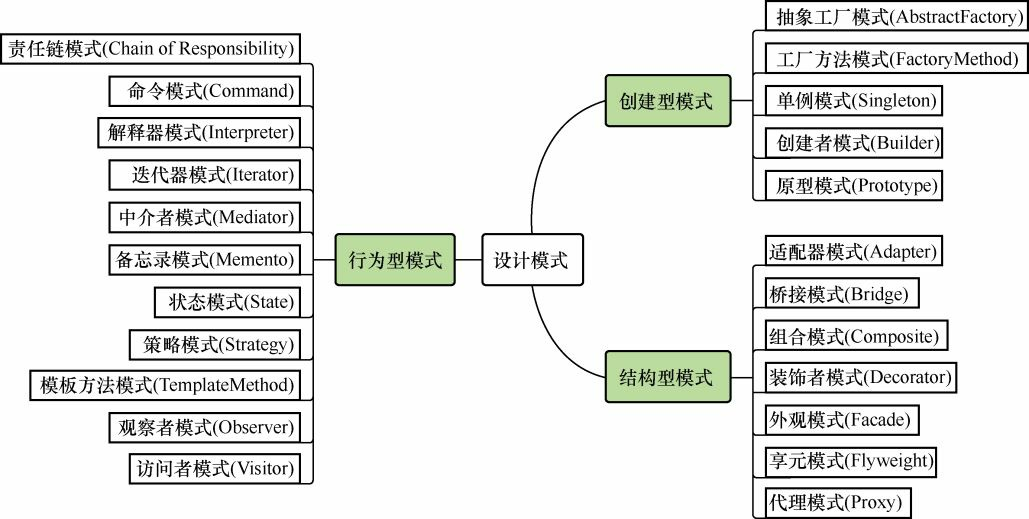
- 创建型模式:用于描述“怎样创建对象”,主要特点是“将对象的创建与使用分离”。 GoF 中提供了单例、原型、工厂方法、抽象工厂、建造者 5 种创建型模式。
- 结构型模式:用于描述如何将类或对象按某种布局组成更大的结构, GoF 中提供了代理、适配器、桥接、装饰、外观、享元、组合 7 种结构型模式。
- 行为型模式:用于描述类或对象之间怎样相互协作共同完成单个对象无法单独完成的任务, 以及怎样分配职责。GoF 中提供了模板方法、策略、命令、职责链、状态、观察者、中介者、迭代器、访问者、备忘录、解释器 11 种行为型模式。
以上提到了 GoF23 种设计模式的分类,简要介绍如下。
- 单例(Singleton)模式:某个类只能生成一个实例,该类提供了一个全局访问点,以便外部获取该实例,其拓展是有限多例模式。
- 原型(Prototype)模式:将一个对象作为原型,通过对其进行复制操作而复制出多个和原型类似的新实例。
- 工厂方法(Factory Method)模式:定义一个用于创建产品的接口,由子类决定生产什么产品。
- 抽象工厂(AbstractFactory)模式:提供一个创建产品族的接口,其每个子类可以生产一系列相关的产品。
- 建造者(Builder)模式:将一个复杂对象分解成多个相对简单的部分,然后根据不同的需要分别创建它们, 最后构建成该复杂对象。
- 代理(Proxy)模式:为某对象提供一种代理以控制对该对象的访问,即客户端通过代理间接地访问该对象, 从而限制、增强或修改该对象的一些特性。
- 适配器(Adapter)模式:将一个类的接口转换成客户希望的另一个接口,使得原本由于接口不兼容而不能一起工作的那些类能一起工作。
- 桥接(Bridge)模式:将抽象与实现分离,使它们可以独立变化。它是用组合关系代替继承关系来实现的, 从而降低了抽象和实现这两个可变维度的耦合度。
- 装饰(Decorator)模式:动态地给对象增加一些职责,即增加其额外的功能。
- 外观(Facade)模式:为多个复杂的子系统提供一个一致的接口,使这些子系统更加容易被访问。
- 享元(Flyweight)模式:运用共享技术来有效地支持大量细粒度对象的复用。
- 组合(Composite)模式:将对象组合成树状层次结构,使用户对单个对象和组合对象具有一致的访问性。
- 模板方法(TemplateMethod)模式:定义一个操作中的算法骨架,将算法的一些步骤延迟到子类中, 使子类可以在不改变该算法结构的情况下,重定义该算法的某些特定步骤。
- 策略(Strategy)模式:定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的改变不会影响使用算法的客户。
- 命令(Command)模式:将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分割开。
- 职责链(Chain of Responsibility)模式:把请求从链中的一个对象传到下一个对象,直到请求被响应为止。 通过这种方式可以去除对象之间的耦合。
- 状态(State)模式:允许一个对象在其内部状态发生改变时改变其行为能力。
- 观察者(Observer)模式:多个对象间存在一对多关系,当一个对象发生改变时,把这种改变通知给其他多个对象, 从而影响其他对象的行为。
- 中介者(Mediator)模式:定义一个中介对象来简化原有对象之间的交互关系,降低系统中对象间的耦合度, 使原有对象之间不必相互了解。
- 迭代器(Iterator)模式:提供一种方法来顺序访问聚合对象中的一系列数据,而不暴露聚合对象的内部表示。
- 访问者(Visitor)模式:在不改变集合元素的前提下,为一个集合中的每个元素提供多种访问方式, 即每个元素有多个访问者对象访问。
- 备忘录(Memento)模式:在不破坏封装性的前提下,获取并保存一个对象的内部状态,以便以后恢复它。
- 解释器(Interpreter)模式:提供如何定义语言的文法,以及对语言句子的解释方法,即解释器。
拦截器模式
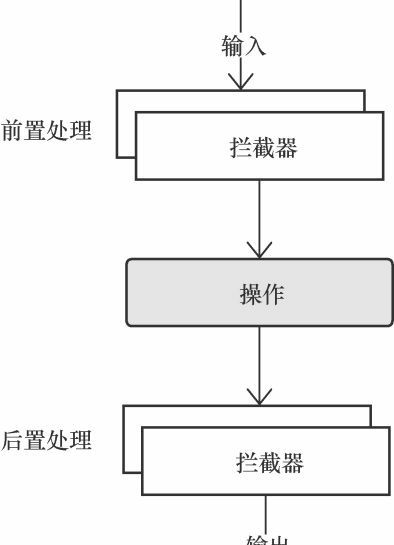
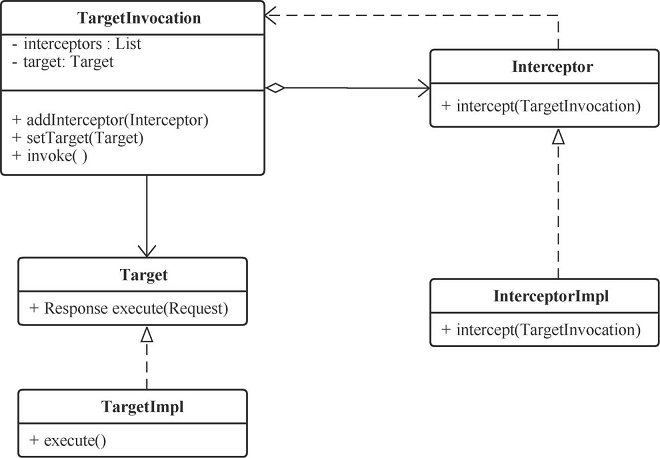
在拦截器模式中,主要包含以下角色。
- TargetInvocation:包含了一组 Interceptor 和一个 Target 对象,确保在 Target 处理请求前后,按照定义顺序调用 Interceptor 做前置和后置处理。
- Target:处理请求的目标接口。
- TargetImpl:实现了 Target 接口的对象。
- Interceptor:拦截器接口。
- InterceptorImpl:拦截器实现,用来在 Target 处理请求前后做切面处理。
- 创建 Target 接口。
public interface Target { public Response execute(Request request); } - 创建 Interceptor 接口。
public interface Interceptor { public Response intercept(TargetInvocation targetInvocation); } - 创建 TargetInvocation。
public class TargetInvocation { private List<Interceptor> interceptorList = new ArrayList<>(); private Iterator<Interceptor> interceptors; private Target target; private Request request; public Response invoke() { if ( interceptors.hasNext() ) { Interceptor interceptor = interceptors.next(); // 此处是整个算法的关键,这里会递归调用 invoke() return interceptor.intercept(this); // 2 } return target.execute(request); } public void addInterceptor(Interceptor interceptor) { // 添加新的 Interceptor 到 TargetInvocation 中 interceptorList.add(interceptor); interceptors = interceptorList.iterator(); } } - 创建具体的 Interceptor。AuditInterceptor 实现如下:
public class AuditInterceptor implements Interceptor { @Override public Response intercept(TargetInvocation targetInvocation) { if (targetInvocation.getTarget() == null) { throw new IllegalArgumentException("Target is null"); } System.out.println("Audit Succeeded "); return targetInvocation.invoke(); } }LogInterceptor 实现如下:
public class LogInterceptor implements Interceptor { @Override public Response intercept(TargetInvocation targetInvocation) { System.out.println("Logging Begin"); Response response = targetInvocation.invoke(); System.out.println("Logging End"); return response; } } - 使用 InterceptorDemo 来演示拦截器设计模式。
public class InterceptorDemo { public static void main(String[] args) { TargetInvocation targetInvocation = new TargetInvocation(); targetInvocation.addInterceptor(new LogInterceptor()); targetInvocation.addInterceptor(new AuditInterceptor()); targetInvocation.setRequest(new Request()); targetInvocation.setTarget(request->{return new Response();}); targetInvocation.invoke(); } } - 执行程序,输出结果。
Logging Begin Audit Succeeded Logging End
插件模式
在一个插件框架中,通常会涉及以下概念。
- ExtensionPoint:扩展点,用来标识可以扩展的功能点。
- Extension:扩展,是对 ExtensionPoint 的扩展实现。
- PluginDescriptor:插件描述,即描述插件的元数据,定义了包括对外暴露的扩展点,运行插件所需要的依赖等信息。一个 PluginDescriptor 对应一个 Plugin.xml 配置。
- PluginRegistry:插件注册,用来进行插件注册和存储。
- PluginManager:插件管理,用来装载和激活插件实例。
- Plugin:插件实例,当 PluginManager 调用 activate 方法激活 Plugin 时,就会产生一个 Plugin 实例。
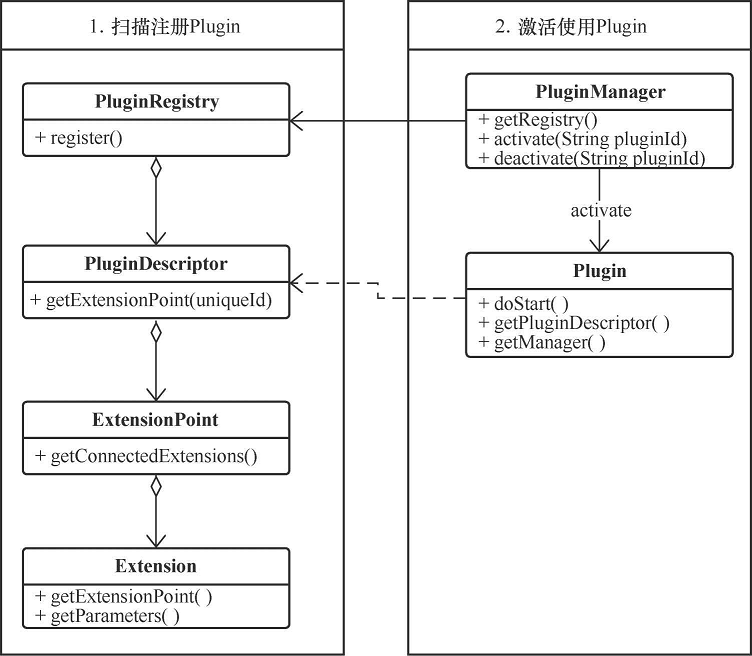
插件模式的概念类图
推荐一个开源项目 JPF(Java Plug-inFramework),它受到了 Eclipse 的插件式启发,致力于打造一个通用的 Java 插件框架。
管道模式
第 6 章 模型
第 7 章 DDD 的精髓
第 8 章 抽象
第 9 章 分治
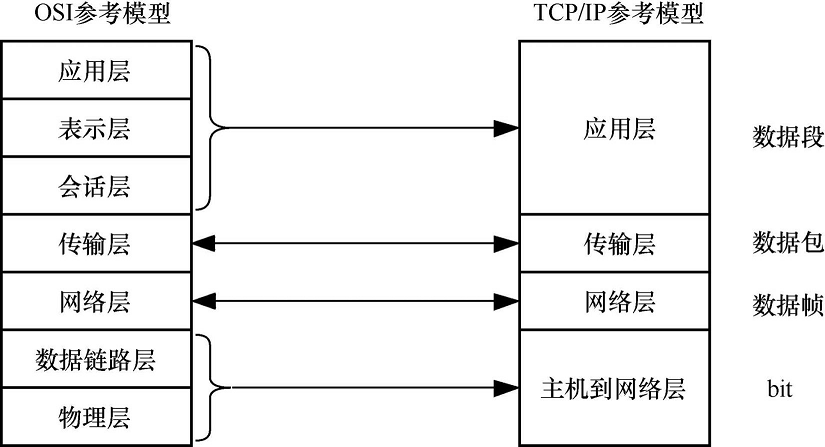
七层模型和四层模型
第 10 章 技术人的素养

成长型思维和固定型思维对比图
精进
精进就是你每天必须进步一点点!记住,慢就是快。千万不要忽视每天进步一点点的力量,也不要试图一口吃成胖子,真正的进步是滴水穿石的累积,这就是精进。
第 11 章 技术 Leader 的修养
技术氛围
一个技术团队,不管大小,如果没有“技术味道”,那么技术 Leader 负有很大的责任。“技术味道”的缺失,是目前技术团队存在的最大问题。特别是做业务开发的技术团队,如果管理者完全不关心技术细节,绩效完全和业务 KPI 绑定,就会导致工程师们整天只会写 if-else 的业务代码,得不到技术上的成长。在这样的技术团队,团队的战斗力和凝聚力都会每况愈下。
什么是 OKR
目标管理的常见手段有关键绩效指标(Key Performance Indicator,KPI)和目标与关键成果(Objectives and Key Results,OKR)两种方法。相比较而言,一味地追求 KPI,可能会导致短视;OKR 更注重短期利益和长期战略之间的平衡。
Leader 和 Manager 的区别
简单来说,Manager 是管理事务,是控制和权威;而 Leader 是领导人心,是引领和激发。 Leader 要做一些 Manager 的管理事务,但是管理绝对不是 Leader 工作的全部。

Leader 和 Manager 的区别
P 线:Profession,专业线。M 线:Manager,管理线。
只有和团队建立了情感链接和信任关系,才能更好地开展工作。 我们在公司工作,实际上是在给两个账号存钱:一个是绩效货币(Performance Currency),这是对事的; 另一个是关系货币(Relationship Currency),这是对人的。 所有的判断都有人的主观因素在里面,因此第二个货币也很重要。
在此提醒一点,搞好关系并不是拉帮结派,还是那句话:“动机至善,了无私心”。 我们做事情的出发点必须要是正的、善的。在这个大前提下,我们可以积极地拓展自己的人脉关系和影响力。
做一个 Leader 不容易,因为你不仅要管好自己,还要成就他人。做一个技术 Leader 更不容易,因为技术的发展日新月异,你没有退路,如果不持续学习,你就会落伍;如果不深入技术细节,你就很难赢得下属的尊重。
第 12 章 COLA 架构
命令查询分离
CQS 命令查询分离(Command Query Separation)最早是 Bertrand Meyer(Eiffel 语言之父,OCP 的提出者)提出的概念,其基本思想在于任何一个对象的方法可以分为以下两类。
- 命令(Command):不返回任何结果(void),但会改变对象的状态。
- 查询(Query):返回结果,但是不会改变对象的状态,对系统没有副作用。
CQRS(Command Query Responsibility Segregation,命令查询职责分离)是在 CQS 思路上的架构扩展。使用了 CQRS 之后,我们能够把读模型和写模型完全分开,从而可以优化读操作和写操作。除了性能提升,CQRS 还让代码库更清晰简洁,更能体现出领域,易于维护。
第 13 章 工匠平台
https://github.com/alibaba/COLA
参考资料快照
 .
.