工作笔记 -- 智能体与氛围编程(Vibe Coding)
AI 编程不仅仅是编码领域的事情,而是典型的软件开发,符合软件工程规律。 遵守以下流程,不轻易跳步。AI 虽然强大,也受制于你给他什么,Garbage in Garbage out,一步渣步步渣。
大模型写代码很牛了,核心原因是 Token 的上下文窗口受限,而人类能够通过抽象和压缩,实现几乎无限的上下文整合与理解。 合作模式感觉是:AI 负责生成,人类负责验证。
2025 年,注定是 Agent 从技术概念走向商业主流的转折点。无论是企业还是个人,若想在这场智能化浪潮中不被淘汰,拥抱 Agent 已不再是选择题,而是生存题。它不是替代人类,而是超级外挂。
未来的软件,不但是给人用的,同时也是给 AI 用的。 所以不但要提供 GUI 界面,还需要提供 MCP 接口,以供 豆包、元宝 之类的 AI 应用直接调用整合。 不提供 MCP 接口的软件,会被慢慢淘汰。 AI 智能体(Agents)。它们是计算机,但行为类似人类。它们就像「互联网的灵魂」,需要与软件基础设施交互。 所以,我们需要让软件更易于被 AI 理解和操控。
AI 就像新型计算机,LLM 像新的「CPU」。 上下文窗口相当于内存;而整个 LLM 则负责在这些资源之间协调内存与计算,以解决问题。
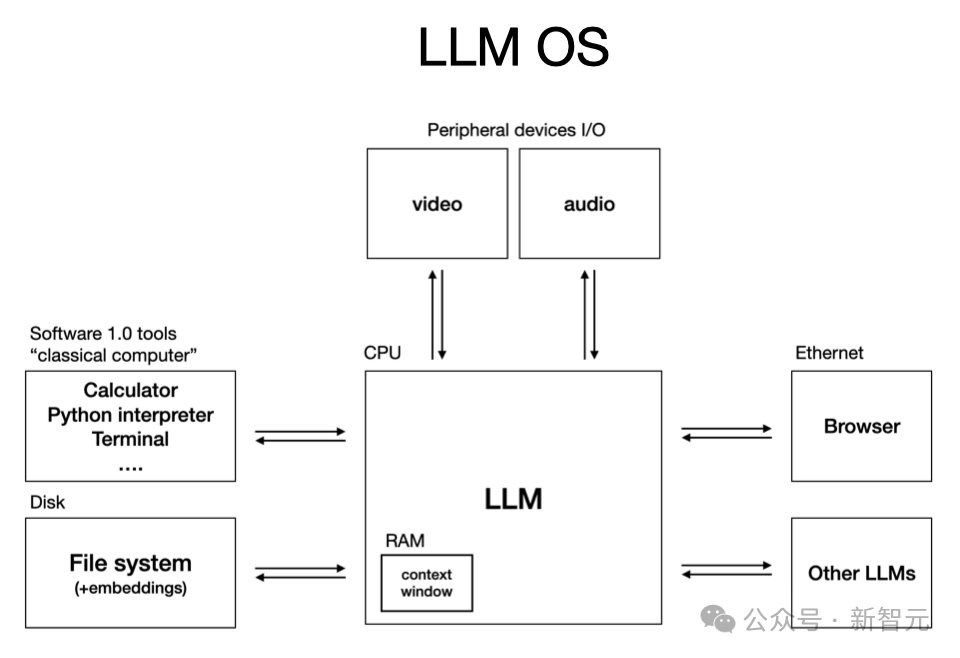
LLM 就像「人类精神」的模拟体 —— 它们是人类的「随机模拟器」。
- 优点:LLM 拥有百科全书般的知识与记忆能力,远远超过任何单一人类个体。它们可以轻松记住 Git SHA 哈希值、各种信息、文件结构等内容。 就像电影《雨人》里的「自闭症天才」,能一字不差地背下电话簿。
- 缺点:LLM 同时也存在很多「认知缺陷」,比如容易幻觉(hallucination),胡编乱造,缺乏对自身知识状态的良好感知。
- 智能参差不齐:它们在某些任务上表现超人,但有时却会犯一些基本错误,比如说「9.11 大于 9.9」。这种「锯齿形智能」现象很独特。
- 前向性遗忘:LLM 不具备持久学习的能力。
我们正在与 AI 合作 —— AI 负责生成,人类负责验证。我们需要尽可能地加快这个生成—验证的循环,这样才能真正提高效率。
- 加快验证速度。GUI 非常关键。视觉界面能调动人类大脑「图像识别 GPU」,而阅读文本费力又不直观。图形界面是直通大脑的高速通道。
- 牢牢地把 AI 控制在手上。很多人现在对「AI 智能体」(agent)过于兴奋。但实际上,如果 AI 给软件 repo 提交了 10,000 行代码,那人类审查员就是最大瓶颈:还得逐行确保没有引入 bug,没有安全问题等等。
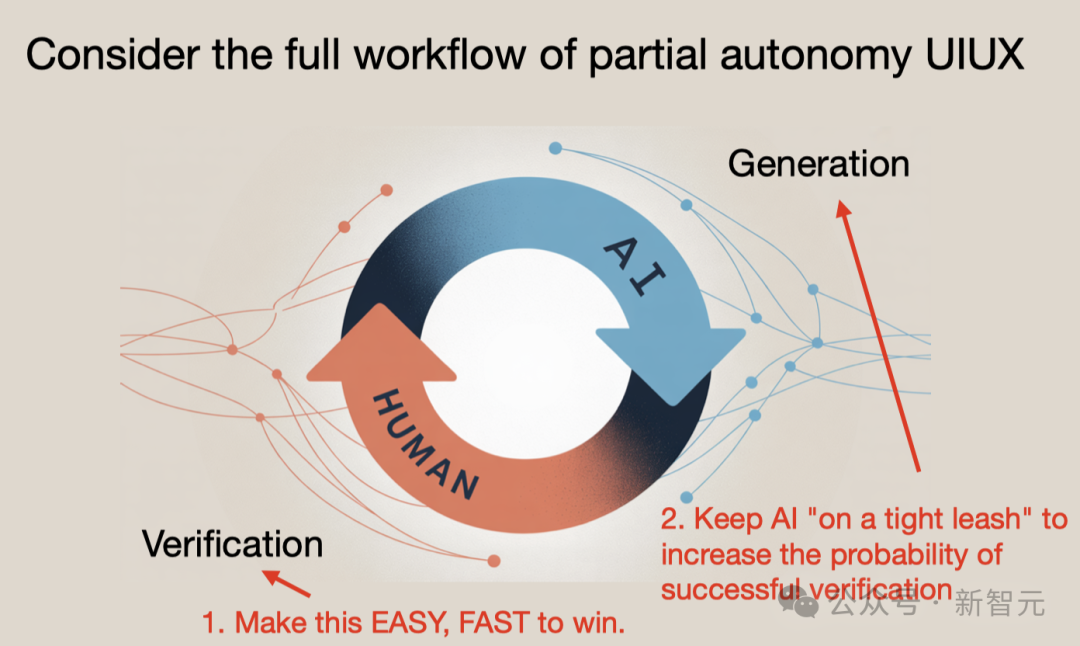
「与 LLM 合作的最佳实践」: 「明确的提示语」(prompt)很关键; 如果提示太模糊,AI 可能偏离预期,导致验证失败; 一旦验证失败,就要不断试错、反复循环; 所以花点时间写更明确、清晰的 prompt,其实是提高效率的关键。
Don’t Build Multi-Agents
Don’t Build Multi-Agents In some cases, libraries such as https://github.com/openai/swarm by OpenAI and https://github.com/microsoft/autogen by Microsoft actively push concepts which I believe to be the wrong way of building agents. Namely, using multi-agent architectures, and I’ll explain why.
https://mp.weixin.qq.com/s/LZcfYqHR2Zl6GnBtzLuMSg 当前流行的多代理框架(Multi-Agent 范式,如 OpenAI 的 Swarm 和 Microsoft 的 AutoGen)违背了 认知可靠性 的基本原理。
AI 代理的根本目标是 在有限上下文约束下完成复杂任务的可靠执行 。而多代理架构在此框架下存在两个根本性矛盾。
- 上下文碎片化悖论
- 第一性原理:LLM 的决策质量与上下文完整性正相关
- 决策熵增定律
- 第一性原理:并行系统决策节点数与系统混乱度呈指数关系
构建可靠代理的两个基本规则:
- 原则 1:全局上下文共享(Full-context Tracing)
- 智能体的每个动作必须基于系统中所有相关决策的完整上下文。
- 原则 2:决策一致性约束(Implicit Decision Coherence)
- 动作中隐含未明说的决策,冲突会导致系统崩溃。
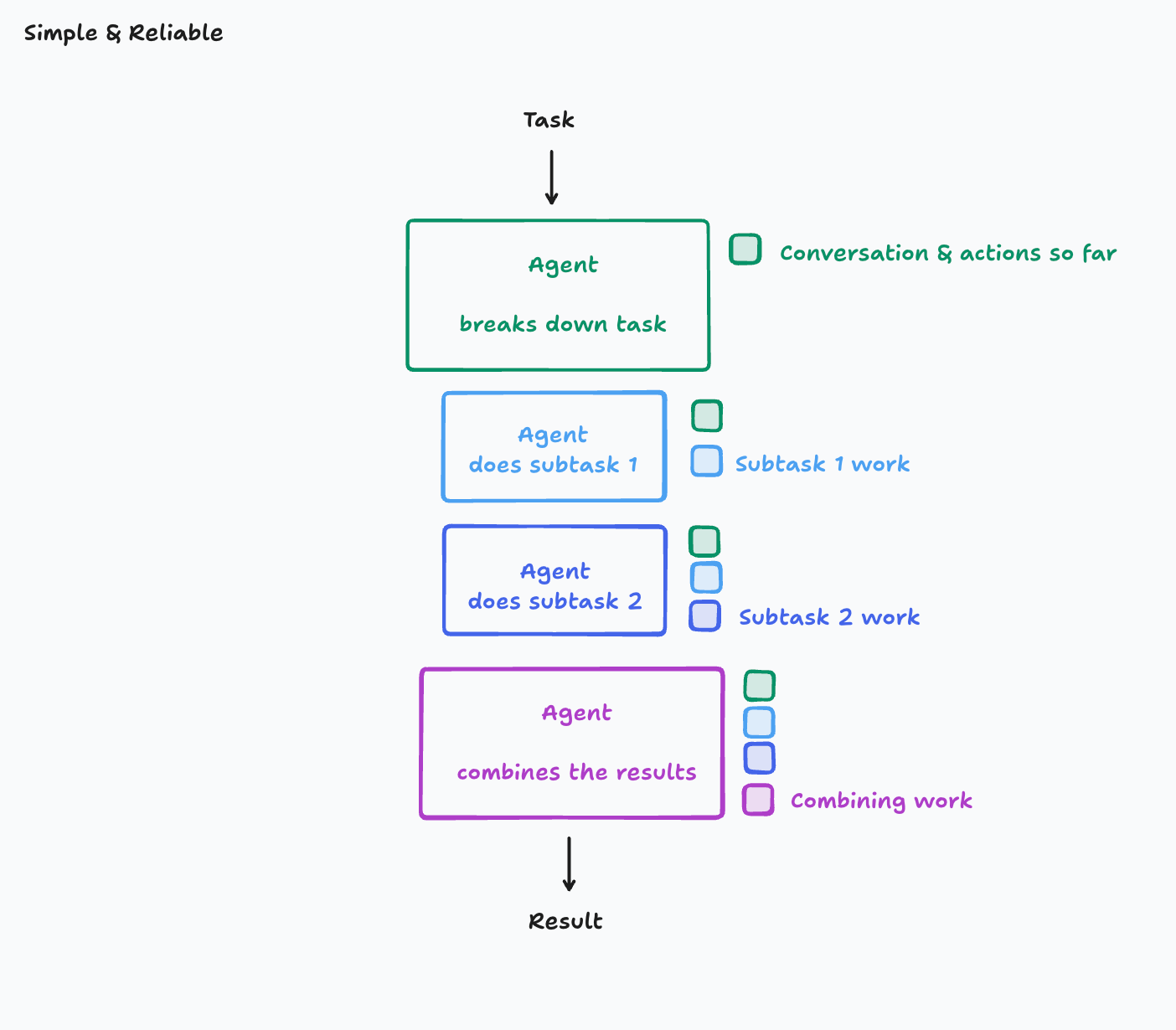
架构范式建议:从多线程回归单线程
- 基础单线程:单线程线性智能体(Single-Threaded Linear Agent)
- 所有动作在单一连续上下文中执行(如图示),避免决策分散。
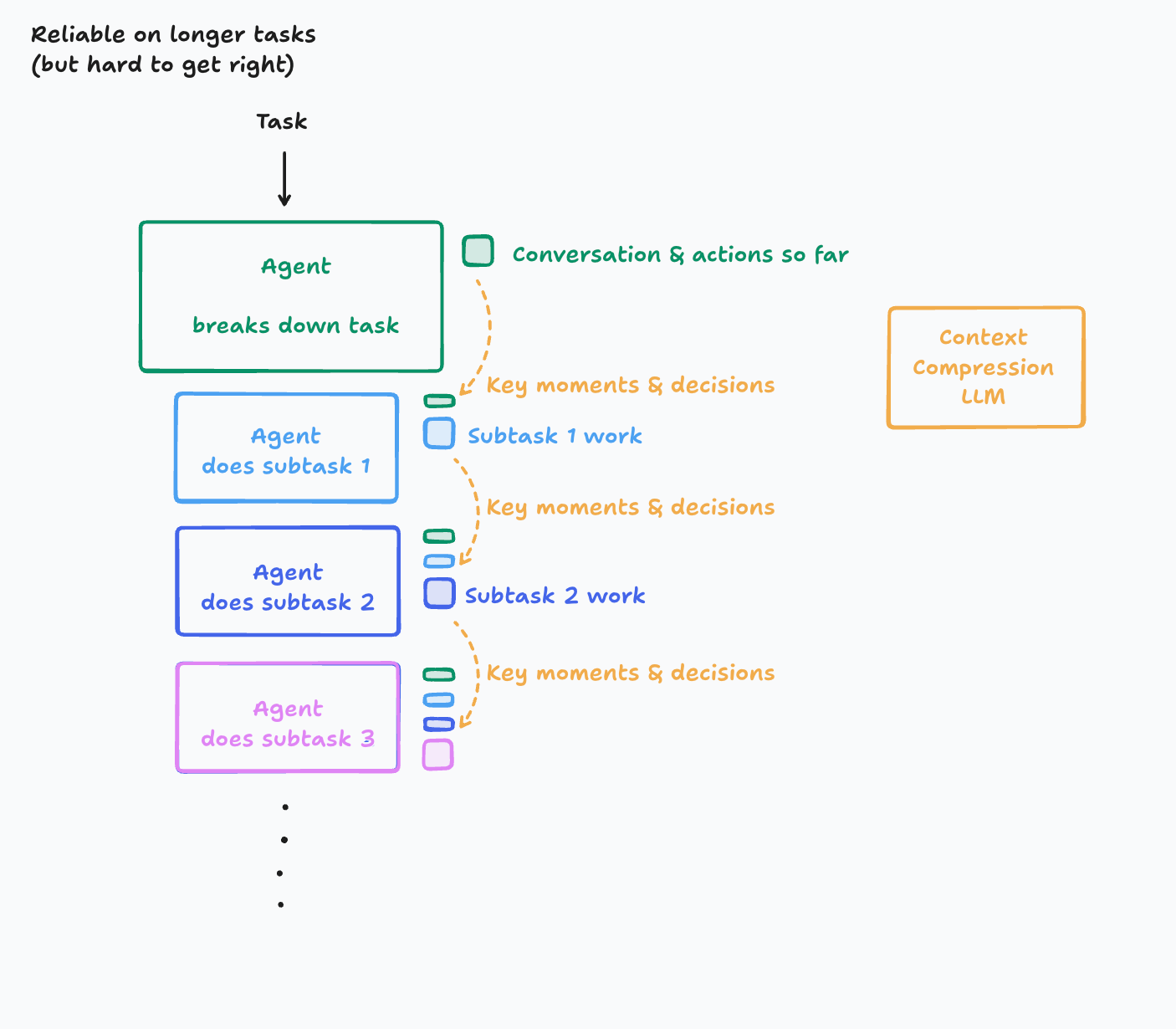
- 压缩中继:上下文压缩模型(Context Compression Model)
- 引入 LLM(可能是专用 LLM)压缩历史动作 / 对话,提炼关键事件和决策。
| 架构类型 | 上下文处理方式 | 可靠性指数 | 适用场景 |
| 基础单线程 | 原始全量上下文 -> 信息无损压缩 | ★★★★☆ | 中、短任务(10 分钟内) |
| 压缩中继 | 动态摘要关键决策 -> 信息有损压缩 | ★★★☆☆ | 长任务(几十分钟甚至几小时) |
DeepSearch 属于单线程,Manus https://manus.im/ 属于压缩中继类型。
进一步探讨:对大模型上下文窗口的影响 当智能体范式从多线程回归单线程,也就意味着未来的大模型需要更关注上下文窗口(支持更长的上下文窗口), 正如 Sam Altman 在前些天的一个访谈节目 https://www.youtube.com/watch?v=qhnJDDX2hhU 中提到的那样:
Sam Altman: 一个非常小的模型,拥有超人类的推理能力,运行速度极快,有 1 万亿 Token 的上下文窗口,并能调用你能想到的所有工具。 在这个设定下,问题是什么、模型有没有现成知识或数据,其实都不重要。
Multi-Agent 系统的核心仍然是 Prompt 设计!
Anthropic 实践发现:Multi-Agent 系统的核心仍然是 Prompt 设计! 
https://www.anthropic.com/engineering/built-multi-agent-research-system https://cognition.ai/blog/dont-build-multi-agents
-
像你的智能体一样思考。 要迭代提示,你必须理解它们的效果。使用系统中的确切提示和工具,然后逐步观察智能体的工作。 这立即揭示了失败模式:智能体在已经获得足够结果时继续运行,使用过于冗长的搜索查询,或者选择错误的工具。 有效的提示依赖于开发智能体的 准确心理模型 ,这可以使最具影响力的更改变得显而易见。
-
教协调者如何委派任务。 首席智能体将查询分解为子任务,并向子智能体描述这些任务。 每个子智能体需要一个目标、输出格式、关于要使用的工具和来源的指导以及清晰的任务边界。 如果没有详细的任务描述,智能体会重复工作、留下空白,或者找不到必要的信息。 最初允许首席智能体给出简单、简短的指令,如“研究半导体短缺”, 但发现这些指令往往过于模糊,导致子智能体误解任务或者与其他智能体进行完全相同的搜索。
-
根据查询复杂性调整工作量。 智能体难以判断不同任务的适当工作量, 因此在 Prompt 中嵌入了调整规则。 简单的事实查找只需要 1 个智能体进行 3-10 次工具调用,直接比较可能需要 2-4 个子智能体, 每次调用 10-15 次,而复杂的研究可能需要超过 10 个子智能体,并且每个子智能体都有明确的职责划分。 这些明确的指导方针有助于首席智能体高效分配资源,并防止在简单查询上过度投入。
-
工具设计和选择至关重要。 智能体与工具的接口和人机界面一样重要。 使用正确的工具是高效的 —— 很多时候,这是绝对必要的。 为智能体提供了明确的启发式规则 :例如,先检查所有可用的工具,将工具的使用与用户意图相匹配,通过网络搜索进行广泛的外部探索, 或者优先选择专业工具而不是通用工具。糟糕的工具描述可能会让智能体走上完全错误的道路, 因此每个工具都需要有明确的目的和清晰的描述。
-
让智能体自我改进。 Claude 4 模型可以成为出色的提示工程师。 当给定一个提示和一个失败模式时,它们能够诊断智能体失败的原因并提出改进建议。 甚至创建了一个工具测试智能体 —— 当给定一个有缺陷的 MCP 工具时,它会尝试使用该工具,然后重写工具描述以避免失败。 通过多次测试工具,这个智能体能够发现关键的细微差别和漏洞。这种改进工具易用性的过程使后续使用新描述的智能体的任务完成时间减少了 40%, 因为它们能够避免大多数错误。
-
先广泛探索,然后逐步缩小范围。 搜索策略应该像专家人类研究一样:先探索整体情况,然后再深入具体细节。 通过提示智能体先从简短且广泛的查询开始,评估可用信息 ,然后逐步缩小关注范围,从而抵消了这种倾向。
-
引导思考过程。 扩展思考模式(导致 Claude 以可见的思考过程输出额外 Token)可以作为一种可控的草稿。 首席智能体使用思考来规划其方法,评估哪些工具适合任务,确定查询的复杂性和子智能体的数量,并定义每个子智能体的角色。
-
并行工具调用改变了速度和性能。 复杂的研究任务自然涉及探索许多来源。为了提高速度,引入了两种并行化:
- 首席智能体同时启动 3-5 个子智能体,而不是依次启动;
- 子智能体同时使用 3 个或更多的工具。这些改变将复杂查询的研究时间缩短了高达 90%,使研究能够在几分钟内完成更多工作, 而不是像其他系统那样需要数小时,同时覆盖了更多的信息。
能力上限更高,用“数据”而非“设计”来驱动增长 当我们发现 Agent 在某类问题上表现不佳时,我们的解决方案不是去绞尽脑汁地修改 Prompt 或 Workflow, 而是将这类问题加入到训练数据中,通过增加“训练题量”和算力,让模型自己学会如何解决。 前者的天花板是“人的智慧”,后者的天花板是“数据和算力” —— 我们坚信后者要高得多。
如果把 Agent 看作终端用户,那么人类软件史上曾经出现过的工具都有机会重写一遍,比如 Agent 要不要有自己的身份?需不需要自己的电话去接收短信?是不是得有支付能力?
我觉得人类最大的一个偏见,就是我们非常相信人类的先验知识对大模型来说很重要,所以我们不停地把我们的知识灌输给大模型,觉得这样它会越来越聪明。 但有没有可能人类的知识对大模型来说其实毫无必要呢? 就像 AlphaZero 一样,对吧?最后大家发现人类的棋谱对它来说其实根本没有用。
Context Engineering for Agents
https://rlancemartin.github.io/2025/06/23/context_engineering/
上下文工程正在替代提示工程。“上下文工程“实际上是构建智能体的工程师的首要工作。LLMs就像是一种新型操作系统。LLM就像是CPU,它的上下文窗口就像是RAM,代表着模型的“工作内存”。如操作系统管理 CPU 的 RAM 空间,进行“上下文工程”,这是填充上下文窗口所需信息的艺术和科学执行任务。文件是存储内容的一种简单方式,最简单的方法就是将所有的记忆都拉进智能体的上下文窗口。
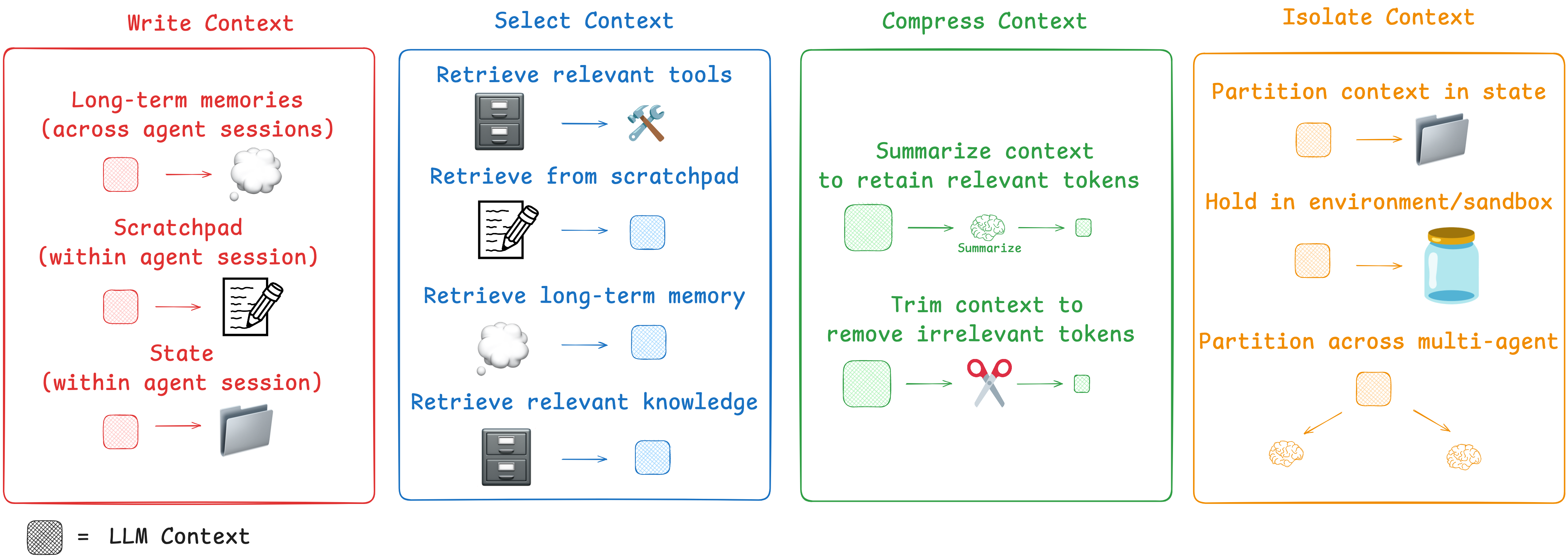
决定 Agent 成功还是失败的主要因素是你给它的上下文的质量。大多数智能体故障不再是模型故障,而是上下文故障。
2025 年是 AI Agent 商业化的转折点,掌握氛围编程不仅是技术选择,更是生存必需。 未来的软件开发者,将是那些能够熟练驾驭 AI 协作的“代码指挥家”。
Claude Code 最佳实践
Claude Code 究竟牛在哪里?
https://baoyu.io/translations/decoding-claude-code
https://tumeicoding.github.io/tumei_study_materials/claude_code_decode.html https://tumeicoding.github.io/tumei_study_materials/claude-code-slides2_zh.html
References
参考资料快照
- https://cognition.ai/blog/dont-build-multi-agents
- https://github.com/openai/swarm
- https://github.com/microsoft/autogen
- https://mp.weixin.qq.com/s/LZcfYqHR2Zl6GnBtzLuMSg
- https://manus.im/
- https://www.youtube.com/watch?v=qhnJDDX2hhU
- https://mp.weixin.qq.com/s/Pp7-ZY63PkktnKs2CGigGg
- https://www.anthropic.com/engineering/built-multi-agent-research-system
- https://rlancemartin.github.io/2025/06/23/context_engineering/
- https://www.anthropic.com/engineering/claude-code-best-practices
- https://baoyu.io/translations/decoding-claude-code
- https://tumeicoding.github.io/tumei_study_materials/claude_code_decode.html
- https://tumeicoding.github.io/tumei_study_materials/claude-code-slides2_zh.html
- https://mp.weixin.qq.com/s/yfjm23XhFwQQOPcOkbJDMQ